논문을 상세히 번역하고 한단어씩 해석해주는 포스팅은 많다.
나는 논문을 누구나 알아듣도록 쉽고 간결하게 전달하고자 한다.
NGCF
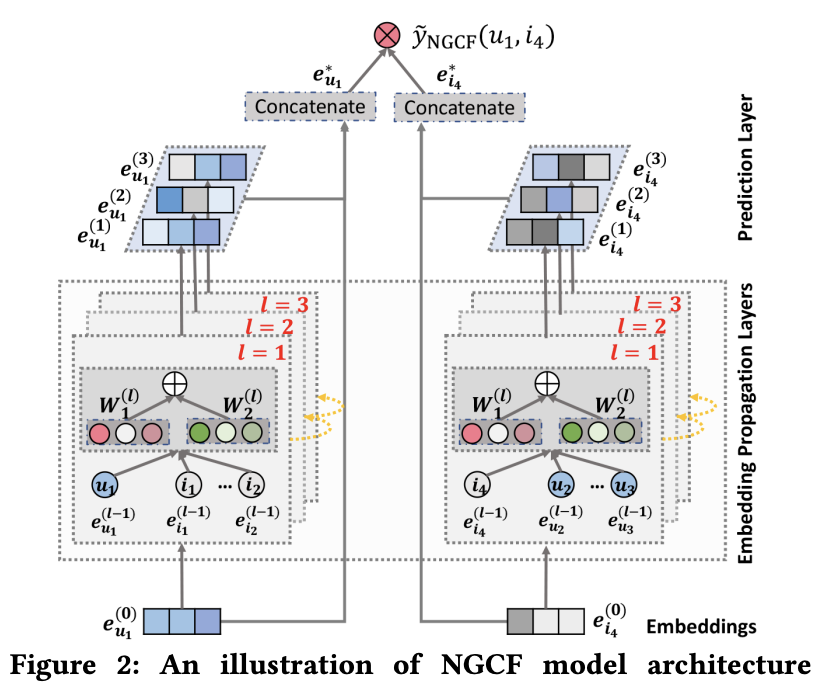
저자의 의도
1. 관계 기반 임베딩 vs 속성 기반 임베딩
유저 임베딩과 아이템 임베딩을 학습하는 것은 현대 추천 시스템의 핵심이다.
MF 기반 알고리즘부터 딥러닝 기반 알고리즘까지 대부분 비슷한 방법을 사용한다.
그 방법은 유저나 아이템의 이미 존재하는 feature들을 사용하는 방법이다.
따라서 내포하고 있는 치명적인 단점이 존재한다. (collaborative signal)
오직 속성 기반의 임베딩만 사용하며, 관계 기반의 임베딩은 사용하지 않는다.
따라서 최종 임베딩이 collaborative filtering을 충분히 반영하지 않는다.
2. NGCF
Neural Graph Collaborative Filtering
저자들은 유저-아이템 관계를 bipartite 그래프 구조로 통합할 것을 제안한다.
NGCF는 유저-아이템 관계를 그래프로 표현하고, 임베딩을 학습한다.
이를 통해서 유저-아이템 그래프의 high-order connectivity를 학습할 수 있다.
이 방법은 명시적으로 collaborative signal을 임베딩에 잘 주입한다.
기존 문제점
1. Collaborative Filtering
개인화 추천은 이커머스, 광고, SNS 등에서 중요한 역할을 한다.
핵심은 구매, 클릭과 같은 과거 상호작용으로 유저를 최적화 하는 것이다.
기존 CF 방법론은 비슷한 행동 유저가 비슷한 아이템을 선호한다는 가정을 한다.
이 가정을 구현하기 위해 유저와 아이템을 파라미터화 하고 선호도를 예측한다.
여기서 CF 모델의 중요한 2개의 요소는 임베딩과 인터랙션 모델링 이다.
임베딩이란 유저와 아이템의 벡터화된 representation이다.
인터랙션 모델링이란 임베딩을 기반으로 과거 상호작용을 재구축하는 것이다.
이 인터랙션은 유저-아이템 임베딩을 내적(MF)으로, MLP(NCF)로 재구축된다.
저자들은 기존 방법이 유저-아이템 관계를 충분히 반영하지 못한다고 설명한다.
임베딩을 만드는 방식 자체가 collaborative signal을 반영하지 못하기 때문이다.
더 자세히 말하면 descriptive features, 즉 묘사적인 특징만 사용하기 때문이다.
descriptive features란 이미 정해진 값, 정적인 값을 말한다. (예: ID, 속성 등)
이것은 본질적으로 유저-아이템의 인터랙션에 대한 값이 아니다.
따라서 간접적으로 혹은 암시적으로 collaborative signal을 반영할 뿐이다.
쉽게 말하면 피처로 임베딩을 만들면 안되고 인터랙션으로 임베딩을 만들어야 한다.
물론 직접적으로 인터랙션을 시그널에 넣는 것이 가장 좋지만 쉬운 일이 아니다.
real world로 모델링할 경우 수백만 혹은 수억개의 인터랙션이 생기게 되기 때문이다.
이걸 디스틸레이션해서 collaborative signal으로 표현하는 것은 매우 어렵다.
저자들은 이를 high-order connectivity로 해결하고자 한다.
2. high-order connectivity
HOP-Rec 이라는 논문에서도 유사한 아이디어를 언급했다.
저자들은 HOP-Rec의 경우 학습 데이터셋을 보완하는 용도로만 사용했다고 주장한다.
특히 HOP-Rec은 MF 기반의 예측 모델이며 변경된 점은 loss 함수 뿐이라고 주장한다.
high-order connectivity를 loss 함수에만 반영한 MF 예측 모델이라는 것이다.
반면 저자들이 제안한 방법은 예측 모델 자체를 변경한다.
예측 모델 아키텍처에 high-order connectivity를 통합하는 방법을 제안한다.
high-order connectivity를 반영한 임베딩을 예측하고 이를 통해 추천을 한다.
즉, 명시적으로 (explicitly) 인코딩하는 것을 제안했다.
해결 아이디어
1. high-order connectivity
인터랙션 그래프 구조에서 자연스럽게 collaborative signal을 인코딩하는 방법이다.
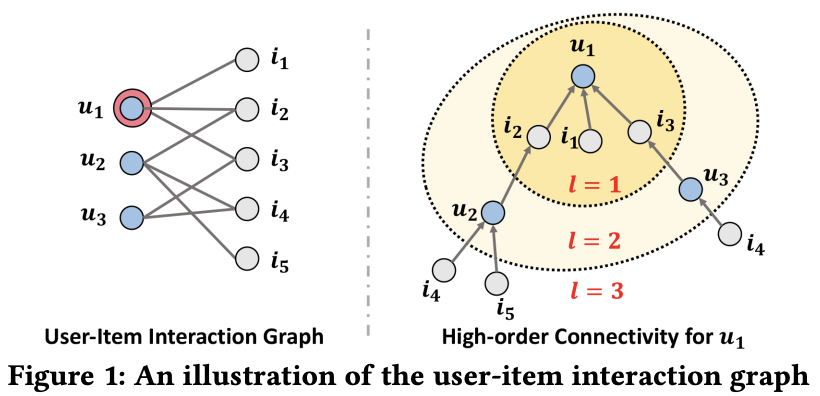
Fig 1은 유저-아이템 인터랙션 그래프와 high-order connectivity를 보여준다.
u1은 추천을 제공할 타겟 유저이다.
왼쪽 그림은 유저-아이템 인터랙션 그래프이다.
오른쪽 그림은 u1을 기준으로 확장한 트리 구조로 high-order connectivity이다.
이 구조는 u1을 기준으로 l 길이로 연결된 모든 노드를 나타낸다.
이 구조는 collaborative signal 전달에 대한 풍부한 의미 정보를 포함한다.
예를들어 u1 - i2 - u2 경로에서 u1과 u2가 i2를 통해 인터랙션 한다.
그리고 u2는 i4 상품을 샀기 때문에 u1도 i4를 선호할 가능성이 있다.
게다가 u1은 l=3에서 i4가 2개, i5가 1개 이므로 i4를 더 선호할 가능성이 있다.
2. embedding functionize
저자들은 이런 high-order connectivity를 임베딩 함수로 모델링하는 것을 제안한다.
인터랙션 그래프를 복잡한 트리 구조로 확장하는 것은 쉽지 않다.
즉, Fig 1의 왼쪽 그래프를 오른쪽 그래프로 만들고 점점 확장 시키는 것은 어렵다.
따라서 neural network를 사용해서 임베딩을 재귀적으로 업데이트한다.
저자들은 이것을 위해 embedding propagation 레이어를 설계했다.
embedding propagation 레이어는 인터랙션에 대한 임베딩을 집계하고 정제한다.
즉, high-order connectivity의 collaborative signal을 임베딩으로 추출한다.
Fig 1을 함께 보자.
레이어 2개를 쌓아서 행동 유사도를 포착한다. (L=2, u1 - i2 - u2)
레이어 3개를 쌓아서 잠재적 추천을 포착한다. (L=3, u1 - i2 - u2 - i4)
정보 흐름의 강도 (학습 가능한 가중치)로 추천 선호도를 결정한다. (i4 vs i5)
3. NGCF
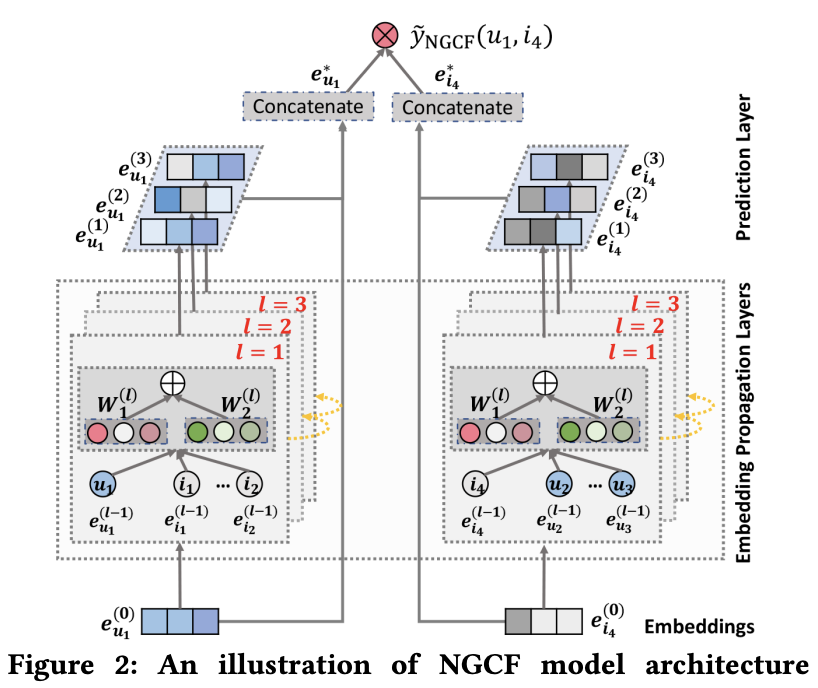
왼쪽은 유저 u1의 representation을 만드는 과정을 보여준다.
오른쪽은 아이템 i4의 representation을 만드는 과정을 보여준다.
각 과정에서는 embedding propagation layer를 여러개 쌓아서 사용한다.
각 layer는 중간 단계의 representation을 출력한다.
중간 단계의 representation들을 모두 concat해서 최종 representation을 만든다.
u1과 i4의 representation을 내적하여 선호도를 예측한다.
(1) embedding layer: 유저와 아이템 임베딩을 초기화한다.
(2) embedding propagation layer: high-order connectivity를 임베딩에 반영한다.
(3) prediction layer: 임베딩들을 집계하고 affinity score를 예측한다.
4. Embedding Layer
기존 메인 스트림의 추천 모델 (NCF, BPR 등)의 임베딩 표기법을 따라 설명한다.
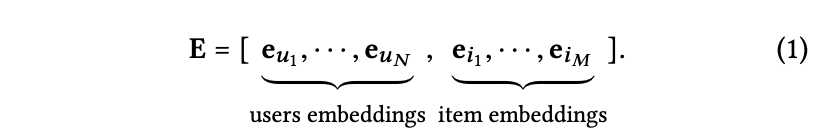
u: 유저, i: 아이템
e_u: 유저 임베딩, e_i: 아이템 임베딩
d: 임베딩 차원
임베딩 룩업 테이블로 파라미터 행렬을 구축하는 것으로 볼 수 있다.
(쉽게 말하면 유저-아이템 임베딩의 인덱싱 사전을 구축하는 것, 키는 고정이지만 값은 학습됨)
주목할 점은 임베딩 테이블이 유저와 아이템 임베딩의 초기값을 제공하는 것이다.
기존 모델과 비교 해보자.
MF나 Neural CF와 같은 기존 모델들은 사용자와 아이템의 ID 임베딩을 사용한다.
여기서 ID 임베딩이란 유저와 아이템의 고유한 ID를 n차원의 임베딩으로 만든 것이다.
기존 모델들은 이 ID 임베딩을 직접 내적같은 계산을 해서 예측값을 구한다.
반면에 NGCF는 ID 임베딩을 초기값으로 사용하고 수정한 뒤 예측값을 구한다.
그리고 이 초기값은 어떠한 의미도 없는 랜덤값으로, 아무런 정보가 없이 시작하는 것이다.
이러한 과정이 embedding propagation layer에서 일어난다.
이는 명시적으로 collaborative signal을 주입해 효율적인 임베딩을 만들 수 있다.
5. Embedding Propagation Layer
이제 저자들은 GNN의 메시지 패싱 아키텍처를 설계한다.
이 아키텍처는 그래프 구조에서 CF 신호를 포착하고 임베딩을 업데이트한다.
5.1. First-order Propagation
직관적으로 유저가 아이템과 상호작용한 것은 선호도의 직접적인 근거이다.
이는 쇼핑 도메인에서 유저가 아이템을 구매한 것을 아이템의 특징으로 간주할 수 있다.
그리고 이 특징에서 두 아이템 간의 collaborative 유사도를 계산할 수 있다.
저자들은 이를 기반으로 연결된 유저와 아이템 간에 임베딩 전파를 설계한다.
message construction과 message aggregation으로 이 과정을 공식화할 수 있다.
5.2. Message Construction

m_ui: 메시지 임베딩, 아이템에서 유저로 propagation되는 정보
f: 메시지 인코딩 함수, e_i, e_u, p_ui를 입력으로 받음
p_ui: 각 edge의 propagation에 대한 decay 계수

N_u: u와 상호작용 하는 아이템들의 집합
N_i: i와 상호작용 하는 유저들의 집합
W1과 W2는 학습가능한 웨이트로 propagation을 통해 유용한 정보를 추출한다.
다른 그래프 GCN 계열 모델들은 e_i만을 활용하도록 설계되어 있다. (ex. GCN, PinSAGE)
반면 NGCF의 경우 e_i와 e_u의 내적을 명시적으로 사용한다.
이 텀을 통해 메시지 임베딩 m이 e_i와 e_u의 친화력(affinity)에 의존하게 만든다.
또한, 유사한 아이템일 경우 더 많은 메시지를 패싱하도록 유도한다.
이러한 설계는 모델의 representation 능력과 추천 성능을 개선한다.
Eq 2의 p_ui는 Eq 3의 1/√NN (라플라시안 정규화) 텀으로 나타낸다.
학습에서는 first-hop 이웃이 몇개인지 나타내며, 임베딩에 얼마나 기여할지 결정한다.
메시지 패싱에서는 멀리 있는 이웃에 대한 discount factor로 작동한다.
5.3. Message Aggregation

e_u_1은 첫번째 임베딩 propagation 레이어로부터 얻은 유저 representation 이다.
activation function으로 LeakyRELU를 사용한다.
u와 상호작용하는 모든 아이템들에서 메시지 (Eq 3에서 계산한 것, m_ui)를 전파 받는다.
또한 자기 자신으로부터 m_uu를 받아 정보를 보존한다. (self-connection term)
(유저는 다른 유저로부터 메시지를 받지 않는다. 오직 아이템으로부터 메시지를 받는다.)
유사하게 e_i_1은 상호작용하는 모든 유저들에서 메시지를 전파받아 구할 수 있다.
결론적으로 유저-아이템의 first-order connectivity 정보를 명시적으로 주입한다.
5.4. High-order Propagation
first-order propagation 형태는 반복 실행 가능한 구조이다.
따라서 이걸 여러번 쌓게 되면 high-order propagation layer 가 된다.
그리고 이 결과로 high-order connectivity 정보를 얻을 수 있다.
l개의 임베딩 레이어를 쌓게 되면 유저는 l-hop 이웃의 메시지를 받을 수 있다.

임베딩 레이어를 재귀적으로 쌓은 수식이 Eq 5 이다.
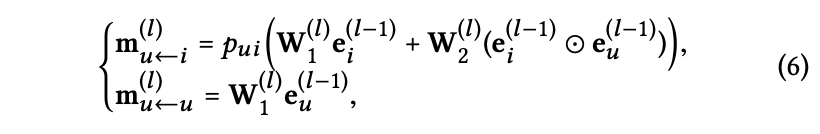
Eq 2 ~ Eq 5 수식을 요약하고 간단하게 표시하면 Eq 6가 된다.
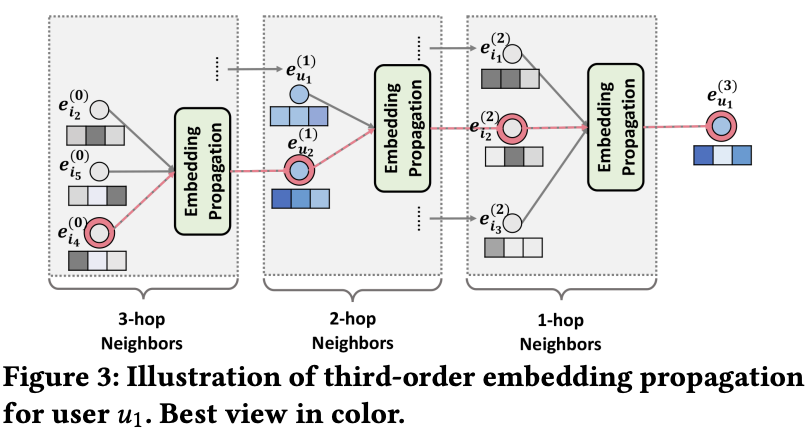
그림에서 third-order embedding propation의 과정을 볼 수 있다.
u1 <- i2 <- u2 <- i4 의 과정을 통해 collaborative signal이 임베딩에 캡쳐된다.
i4의 메시지는 명시적으로 e_u1_3에 인코딩되는 것을 볼 수 있다. (Fig 3의 빨간 표시)
이제 우리는 이 레이어를 쌓아서 자연스럽게 collaborative signal을 주입할 수 있다.
5.5. Propagation Rule in Matrix Form
행렬으로 한번 더 설명 (생략)
6. Model Prediction
L개의 레이어를 전파하고나면 우리는 여러개의 representation을 얻는다. (e_u_1, ~ e_u_L)
각각의 representation은 서로 다른 레이어에 의해 메시지 패싱이 일어난 결과이다.
따라서 각각의 representation은 서로 다른 의미를 가지고 서로 다른 유저 선호도를 캡쳐한다.
저자들은 최종 임베딩을 구성하기 위해 이 representation들을 모두 concat 한다.

e_u_*: 최종 유저 임베딩
e_i_*: 최종 아이템 임베딩
||: 벡터 concat 연산
최종 임베딩을 계산하는 수식은 Eq 9과 같다.
이제 L을 조정하면 propagation 범위를 조정할 수 있다.
저자들은 concat을 사용했지만 weighted sum, max pool, LSTM 등도 가능하다.
저자들이 concat을 사용한 이유는 간단하고 추가로 학습할 파라미터가 없기 때문이다.
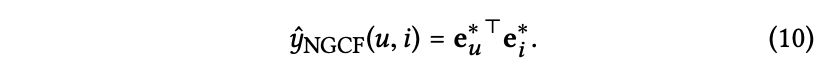
이제 최종적으로 유저와 아이템 임베딩의 내적으로 affinity score를 예측한다.
y_ui: u가 i를 선호하는 정도 (affinity score)
7. Optimization
추천 시스템에서 주로 사용하는 pairwise BPR loss를 사용한다.
BPR loss는 관측한 아이템이 관측 안한 아이템보다 상대적으로 앞 순서가 되도록 고려한다.
특히 관측이 인터랙션이라고 가정하는데, 이것은 유저의 선호도를 반영한다고 가정한다.
따라서 관측한 아이템이 관측하지 않은 아이템보다 더 높은 예측값을 갖도록 학습한다.

R+: positive sample, 관측한 아이템
R-: negative sample, 관측하지 않은 아이템
σ: 시그모이드 함수
Ө: 모델 파라미터 집합
λ: 정규화 계수
||Ө||^2: L2 정규화
추가로 Adam을 사용하여 최적화 한다.
각 배치는 랜덤으로 샘플링된 트리플렛 (u, i, j)로 구성된다.
i는 관측한 아이템, j는 관측하지 않은 아이템에서 랜덤 샘플링 한다.
8. Model Size
NGCF의 경우 각 propagation layer마다 임베딩 행렬이 필요하지만 매우 적은 양이다.
l개의 레이어를 쌓으면 2l개의 임베딩 행렬이 필요하다. (W1과 W2, d_l x d_l-1 크기)
임베딩 행렬들은 임베딩 룩업 테이블 E의 크기에 의존한다.
MF 기반 모델과 비교했을 때 매우 작으며, NGCF는 오직 2Ld_ld_l-1개의 파라미터만 사용한다.
보통 L은 5보다 작으며 d_l은 유저와 아이템 수보다 훨씬 작은 임베딩 사이즈로 설정한다.
예를들어 Gowalla 데이터셋은 유저와 아이템 수가 총 60K개 이지만 d_l은 64로 설정한다.
L=3, d_l=64로 설정하면 MF=4.5M, NGCF=0.024M개의 파라미터를 사용한다.
9. Message and Node Dropout
딥러닝 모델이 강력한 representation 능력을 갖게 되면서 과적합이 심해졌다.
이를 해결하기 위해 dropout 기법이 널리 사용되고 있다.
NGCF 역시 과적합을 막기 위해 dropout 기법을 사용한다.
message dropout: 메시지 패싱 과정에서 임의로 메시지를 드롭한다.
node dropout: 임베딩 propagation 레이어에서 임의로 노드를 드롭한다.
결과 분석
1. Experiment
Dataset: Gowalla, Yelp2018, Amazon-book 데이터셋을 사용한다.
eval metric: Recall@20, NDCG@20
baselines: MF, NeuMF, CMN, HOP-Rec, PinSAGE, GC-MC
parameter: 각 모델별 lr과 계수, 논문 원문 참고
2. RQ1: NGCF와 SOTA 모델 비교

기본적인 MF 방식들은 성능이 낮으며, 점차 개선되어 CMN은 나름 좋은 성능을 보인다.
GC-MC나 CMN은 1-hop 이웃만을 사용하는 방식이다.
NGCF는 더 많은 hop을 사용하여 반영할 수 있고, 실제 성능도 가장 좋다.

RecSys의 고질병인 sparse한 데이터에서도 더 좋은 성능을 보이는지 확인한다.
더 sparse한 데이터에서도 NGCF가 더 좋은 성능을 보인다.
3. RQ2: NGCF의 하이퍼파라미터 영향

레이어 수: 레이어를 더 많이 쌓을수록 성능이 좋아진다. (L=3이 가장 좋음)

Propagation & Aggregation: 다른 모델과 결합한 것보다 NGCF가 더 좋다.

Dropout: 노드 드롭아웃이 대부분 더 좋은 성능을 보인다.

Epoch: NGCF가 더 빠르게 수렴한다.
4. RQ3: high-order connectivity의 효과

embedding propagation을 여러층 쌓는 것이 어떻게 도움이 되는지 확인한다.
Gowalla 데이터셋에서 유저 6명과 상호작용 아이템을 무작위로 고른다.
propagation을 하지 않은 NGCF-0 (=MF)와 NGCF-3의 임베딩을 시각화했다.
NGCF-3은 같은 사용자의 상호작용 아이템이 가깝게 위치해 클러스터를 이룬다.
반면 NGCF-0은 임베딩이 무작위로 흩어져 있다. (약간의 경향성은 보이나 클러스터는 아님)
따라서 high-order connectivity가 고품질 임베딩을 만드는데 효과가 있다.
코드 및 구현
오피셜 코드는 텐서플로우
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import scipy.sparse as sp
class NGCF(nn.Module):
def __init__(self, n_user, n_item, norm_adj, args):
super(NGCF, self).__init__()
self.n_user = n_user
self.n_item = n_item
self.emb_dim = args.embed_size
self.batch_size = args.batch_size
self.node_dropout = args.node_dropout[0]
self.message_dropout = args.message_dropout
self.norm_adj = norm_adj
self.layers = eval(args.layer_size)
self.n_layers = len(self.layers)
self.decay = eval(args.regs)[0]
self.embedding_dict, self.weight_dict = self.init_weight()
self.L = self._convert_sp_mat_to_sp_tensor(self.norm_adj).to(args.device)
self.L_I = self._convert_sp_mat_to_sp_tensor(self.norm_adj + sp.eye(self.norm_adj.shape[0])).to(args.device)
def init_weight(self):
initializer = nn.init.xavier_uniform_
embedding_dict = nn.ParameterDict({
'user_emb': nn.Parameter(initializer(torch.empty(self.n_user, self.emb_dim))),
'item_emb': nn.Parameter(initializer(torch.empty(self.n_item, self.emb_dim)))
})
weight_dict = nn.ParameterDict()
layers = [self.emb_dim] + self.layers
for k in range(len(self.layers)):
weight_dict.update({'W_gc_{}'.format(k): nn.Parameter(initializer(torch.empty(layers[k], layers[k + 1])))})
weight_dict.update({'b_gc_{}'.format(k): nn.Parameter(initializer(torch.empty(1, layers[k + 1])))})
weight_dict.update({'W_bi_{}'.format(k): nn.Parameter(initializer(torch.empty(layers[k], layers[k + 1])))})
weight_dict.update({'b_bi_{}'.format(k): nn.Parameter(initializer(torch.empty(1, layers[k + 1])))})
return embedding_dict, weight_dict
def _convert_sp_mat_to_sp_tensor(self, X):
coo = X.tocoo().astype(np.float)
i = torch.LongTensor(np.mat([coo.row, coo.col]))
v = torch.FloatTensor(coo.data)
res = torch.sparse.FloatTensor(i, v, coo.shape)
return res
def sparse_dropout(self, x, rate, noise_shape):
random_tensor = 1 - rate
random_tensor += torch.rand(noise_shape).to(x.device)
dropout_mask = torch.floor(random_tensor).type(torch.bool)
i = x._indices()
v = x._values()
i = i[:, dropout_mask]
v = v[dropout_mask]
out = torch.sparse.FloatTensor(i, v, x.shape).to(x.device)
return out * (1. / (1 - rate))
def forward(self, users, pos_items, neg_items, drop_flag=True):
if drop_flag:
L_hat = self.sparse_dropout(self.L, self.node_dropout, self.L._nnz())
L_I_hat = self.sparse_dropout(self.L_I, self.node_dropout, self.L_I._nnz())
else:
L_hat, L_I_hat = self.L, self.L_I
ego_embeddings = torch.cat([self.embedding_dict['user_emb'], self.embedding_dict['item_emb']], 0)
all_embeddings = [ego_embeddings]
for k in range(self.n_layers):
L_side_embeddings = torch.sparse.mm(L_hat, ego_embeddings)
L_I_side_embeddings = torch.sparse.mm(L_I_hat, ego_embeddings)
sum_embeddings = torch.matmul(L_I_side_embeddings, self.weight_dict['W_gc_{}'.format(k)]) + \
self.weight_dict['b_gc_{}'.format(k)]
bi_embeddings = torch.mul(L_side_embeddings, ego_embeddings)
bi_embeddings = torch.matmul(bi_embeddings, self.weight_dict['W_bi_{}'.format(k)]) + self.weight_dict[
'b_bi_{}'.format(k)]
ego_embeddings = nn.LeakyReLU(negative_slope=0.2)(sum_embeddings + bi_embeddings)
ego_embeddings = nn.Dropout(self.message_dropout[k])(ego_embeddings)
norm_embeddings = F.normalize(ego_embeddings, p=2, dim=1)
all_embeddings += [norm_embeddings]
all_embeddings = torch.cat(all_embeddings, 1)
u_g_embeddings = all_embeddings[:self.n_user, :]
i_g_embeddings = all_embeddings[self.n_user:, :]
u_g_embeddings = u_g_embeddings[users, :]
pos_i_g_embeddings = i_g_embeddings[pos_items, :]
neg_i_g_embeddings = i_g_embeddings[neg_items, :]
return u_g_embeddings, pos_i_g_embeddings, neg_i_g_embeddings
def bpr_loss(self, u_g_embeddings, pos_i_g_embeddings, neg_i_g_embeddings):
pos_yui = torch.sum(torch.mul(u_g_embeddings, pos_i_g_embeddings), axis=1)
neg_yuj = torch.sum(torch.mul(u_g_embeddings, neg_i_g_embeddings), axis=1)
maxi = nn.LogSigmoid()(pos_yui - neg_yuj)
mf_loss = -1 * torch.mean(maxi)
# regularizer = (torch.sum(u_g_embeddings**2) + torch.sum(pos_i_g_embeddings**2) + torch.sum(neg_i_g_embeddings**2))/2
regularizer = (torch.norm(u_g_embeddings) ** 2
+ torch.norm(pos_i_g_embeddings) ** 2
+ torch.norm(neg_i_g_embeddings) ** 2) / 2
emb_loss = (self.decay * regularizer) / self.batch_size
bpr_loss = mf_loss + emb_loss
return bpr_loss
def rating(self, u_g_embeddings, pos_i_g_embeddings):
return torch.matmul(u_g_embeddings, pos_i_g_embeddings.t())
'논문리뷰' 카테고리의 다른 글
| [논문 리뷰] RLM 요약, 코드, 구현 (2) | 2026.03.31 |
|---|---|
| [논문 리뷰] DeepFM 요약, 코드, 구현 (0) | 2025.12.18 |
| [논문 리뷰] CLIP 요약, 코드, 구현 (0) | 2025.12.15 |
| [논문 리뷰] GCN 요약, 코드, 구현 (6) | 2025.08.03 |
| [논문 리뷰] LLaMA v1 요약, 코드, 구현 (0) | 2025.03.31 |



