논문을 상세히 번역하고 한단어씩 해석해주는 포스팅은 많다.
나는 논문을 누구나 알아듣도록 쉽고 간결하게 전달하고자 한다.
CLIP
저자의 의도
고정된 카테고리를 '분류'로 학습하는 것은 일반화가 어렵다.
'분류' 대신 '이미지를 서술하는 raw 텍스트에서 직접 학습'하는 것을 제안한다.
이미지-텍스트 쌍 데이터셋을 사전학습하여 이미지 representation을 학습한다.

기존 문제점
[Predetermined categories]
기존 CV 시스템은 사전에 결정된 고정 카테고리를 예측한다.
이미지넷을 생각해보자. 이미지넷은 1000개의 카테고리 이미지를 학습한다.
그런데 이 1000개의 카테고리는 우리가 '미리 지정한' (=predetermined) 것이다.
이런 경우에 일반화와 사용성에 문제를 야기한다.
1000개의 카테고리가 1001개가 되면 어떻게 할 것인가.
1000개의 카테고리 중에 100개만 하고싶으면? 아니면 새로운 1000개로 하고싶으면?
이렇게 미리 지정한 카테고리로 학습하는 것은 일반적인 다른 task에 적용하기 힘들다.
CV는 특히 웹의 텍스트를 가져다 쓰기 힘들기 때문에 이미지넷을 사용한다.
NLP는 문자이기 때문에 웹에 '학습 가능한 형태로' 널리고 널렸다.
CV는 이미지이기 때문에 설명이 포함되어 '학습 가능한 형태'로 존재하지 않드다.
따라서 어쩔수 없이 이미지넷을 쓰고 있는 현황이다.
[Zero-shot transfer]
학습이 끝나면 오직 1개의 task에만 사용 가능하다.
위에서 말한 것과 유사하다. 클래스가 바뀌면? 못쓴다.
그럼 분류가 아니라 객체 인식에 쓰고싶으면? 못쓴다.
이런 문제점이 CV가 고전하고 있는 대표적인 문제이다.
해결 아이디어
1. Image-Text 쌍을 사용한 사전 학습

저자들은 이미지에 대한 raw 텍스트에서 직접 학습하는 것을 제안했다.
이것을 위해 간단한 사전학습 task (이미지에 대한 캡션 예측)을 정의했다.
이 방법은 효율적이며 확장가능한 (데이터를 추가로 사용할 수 있는) 방법이다.
인터넷에서 수집한 400M개의 이미지-텍스트 쌍을 사용한다.
2. Natural Language Supervision
저자들의 핵심 아이디어는 자연어 supervision(학습 정보)에서 시각 모델을 학습하는 것이다.
자연어 학습은 다른 학습법에 비해 몇가지 강점을 가진다.
첫번째, 기존 방법보다 훨씬 확장하기 쉽다.
골드 라벨을 만들기 위해 사람의 어노테이션을 할 필요가 없기 때문이다.
그저 인터넷에 있는 방대한 양의 이미지-텍스트 쌍을 사용하면 된다.
두번째, 단순히 representation을 학습하는 것이 아니라 언어와 연결하여 학습한다.
따라서 유연하게 zero-shot transfer를 시도할 수 있다.
3. Creating a Sufficiently Large Dataset
기존 연구들은 3가지 메인 데이터셋을 사용한다. (MS COCO, Visual Genome, YFCC100M)
기존 데이터셋은 너무 작거나, 이미지에 대한 설명의 질이 낮다.
따라서 저자들은 400M개의 이미지-텍스트 쌍을 인터넷에서 수집했다.
(이게 바로 그 유명한 OpenAI의 Closed 데이터셋. 응? open?AI)
이때 검색에 사용한 쿼리는 500k개이며, 위키피디아에서 추출해 가공했다.
사실 여기서 연구자들의 힘이자 우리가 나아가야할 방향이 나온다.
이 데이터 큐레이션과 가공 방법은 이 연구의 핵심적인 부분이다.
[가공 방법]
위키피디아에서 100번 이상 등장하는 단어만 추출한다.
high PMI bi-gram을 추가한다. (함께 사용하는 의미있는 조합, ex. new york)
검색량 높은 위키 문서명을 추가한다.
WordNet synset의 단어를 추가한다. (동의어 그룹, ex. car, auto, automobile)
각 쿼리(=클래스)의 이미지는 20k개로 제한했다.
이 데이터셋의 길이는 GPT-2 학습에 사용한 WebText와 비슷하다.
이 데이터셋을 WebImageText (WIT)라고 부른다. (비공개 데이터셋)
4. Selecting an Efficient Pre-Training Method
비전 분야에서 SOTA 모델을 학습하는 것은 매우 긴 시간이 걸린다.
그리고 고작 1000개 클래스를 학습한건데 그럼 어떻게 이미지쌍을 학습할지 막막하다.
즉, 학습 효율성을 올리는 것이 자연어 supervision(학습 정보)를 활용하는데 핵심이다.

이 그림은 이제 소개할 여러가지 시행착오에 대한 것이다.
(1) Transformer Language Model
저자들은 먼저 VirTex처럼 image CNN과 text Transformer를 사용했다.
이 방법은 이미지에 대한 캡션 전체를 생성하는 방법이다.
CNN과 TR을 모두 학습했는데, text TR이 너무 느려서 비효율적이었다.
(2) Bag-of-Words (BoW)
이 방법은 캡션 전체가 아니라 캡션에 포함된 단어들의 집합을 예측하는 방법이다.
이 방법은 text TR을 학습하지 않고, 이미지 CNN만 학습한다.
2번 방법은 1번 방법에 비해 3배 빠르다. (위 그림 참고)
이런 방법들은 text의 정확한 단어를 예측하려고 하는데 이건 너무 어렵다.
따라서 다른 방법을 검토했는데 이것이 contrastive learning이다.
contrastive objective는 상대적으로 더 나은 representation을 학습한다.
(3) Bag-of-Words Contrastive (CLIP)
저자들은 확률적으로 더 쉬운 proxy task를 설계하여 이를 구현했다.
두 text 중에 이미지에 더 적합한 text가 무엇인지만 맞추는 것이다.
쉽게 말해서 이미지와 캡션이 짝인지 아닌지만 맞추면 된다.
3번 방법은 2번 방법에 비해 4배 빠르다. (위 그림 참고)
N개의 이미지-텍스트 쌍이 주어지면 CLIP은 NxN개의 이미지-텍스트 쌍을 만든다.
N개의 이미지 임베딩과 N개의 텍스트 임베딩을 계산하고 행렬 형태로 만드는 것이다.
(위 그림에서 왼쪽 부분 참고)
이를 위해서 CLIP은 멀티모달 임베딩 공간을 학습하며, 과정은 다음과 같다.
1. 전체 배치 NxN 안에 N개의 실제 (정답이 맞는 것) 이미지-텍스트 쌍이 있다. (위 그림 왼쪽 부분의 파란 색 요소)
2. 이 쌍의 코사인 유사도를 최대화하고, 나머지 (N^2-N)개의 코사인 유사도를 최소화한다. (위 그림 왼쪽 부분의 흰 색 요소)
3. 이 유사도 점수에 대해 symmetric cross-entropy loss를 사용한다.
4. 양쪽이 대칭으로 학습하는 것으로 이미지 인코더와 텍스트 인코더가 모두 학습된다.
(이미지 -> 텍스트 의 positive, negative) + (텍스트 -> 이미지 의 positive, negative)

CLIP 모델 구현의 핵심에 대한 수도코드를 작성한 것이다.
loss를 이미지, 텍스트 양쪽에 대해 계산한 뒤 평균을 내어 반영하는 것을 볼 수 있다.
유사한 방법론으로는 SimCLR, MoCo 가 사용하는 InfoNCE loss가 있다.
하지만 SimCLR, MoCo 같은 경우는 한쪽 방향으로만 학습한다.
(이미지 -> 텍스트 의 (positive, negative))
(=이미지 인코더만 학습하는 것)
5. Multi-Modal Embedding Space
CLIP은 사전학습을 하지 않은 이미지 인코더와 텍스트 인코더를 처음부터 학습한다.
또한 representation과 embedding space 사이에 비선형 프로젝션을 사용하지 않는다.
대신 저자들은 인코더의 representation을 리니어 프로젝션으로 바로 매핑했다.
CLIP을 설명할 때 사람들이 매우 헷갈려 하는 부분이 여기다. (여전히 잘못 아는 사람도 많다.)
CLIP은 사전학습된 이미지 인코더를 쓰지 않는다. 심지어 텍스트 인코더도 처음부터 학습한다.
그리고 이 임베딩 스페이스는 이미지 스페이스도 텍스트 스페이스도 아니다.
이 스페이스는 '멀티 모달 스페이스'이며, 이 스페이스를 위해 복잡한 프로젝션을 하지 않는다.
이 논문의 핵심 아이디어 중에 하나는 문제를 단순화 하는 것이니 꼭 기억하자.
6. Choosing and Scaling a Model
이미지 인코더로는 ResNet50과 Vision Transformer (ViT)를 사용했다.
텍스트 인코더로는 Transformer를 사용했다.
7. Training
ResNet: 50, 101, 50x4, 50x16, 50x64
ViT: B/32, B/16, L/14
epochs=32, batch size=32768, Adam, cosine annealing
1 epoch grid search 후 최적의 하이퍼파라미터를 찾아 32 epochs로 학습했다.
직접 Mixed Precision을 구현하여 메모리를 아끼고 속도를 높였다.
V100 GPU 592개로 RN50x64 모델을 학습하는데 18일이 걸렸다.
V100 GPU 256개로 ViT-B/32 모델을 학습하는데 12일이 걸렸다.
결과 분석
1. Zero-Shot Transfer
학습에 사용하지 않은 데이터셋에 대하여 image classification을 수행한다.
1.1. Prompt Engineering and Ensembling

이미지에 대한 캡션을 만들기 위해 텍스트 프롬프트를 사용한다.
예를 들어 "A photo of a {label}." 형태로 프롬프트를 만든다.
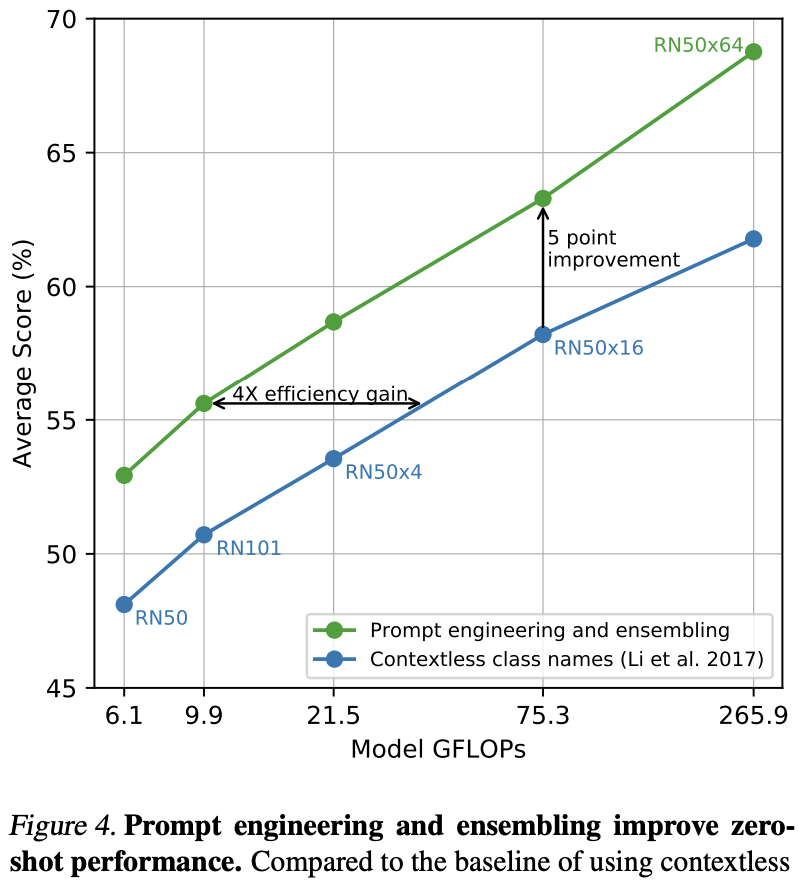
GPT-3 논문에서 언급한 것처럼 프롬프트의 형태에 따라 성능이 크게 달라진다.
따라서 80개의 다른 프롬프트를 앙상블하는 방법을 사용했다.
1.2. Analysis of Zero-Shot CLIP Performance

27개의 데이터셋 중에서 16개의 데이터셋에서 CLIP이 더 좋은 성능을 보인다.
CLIP이 더 안좋은 경우에는 해당 데이터셋이 너무 복잡하거나 추상적인 경우였다.
예를들어 EuroSAT은 인공위성 이미지로 구성되어 있다.
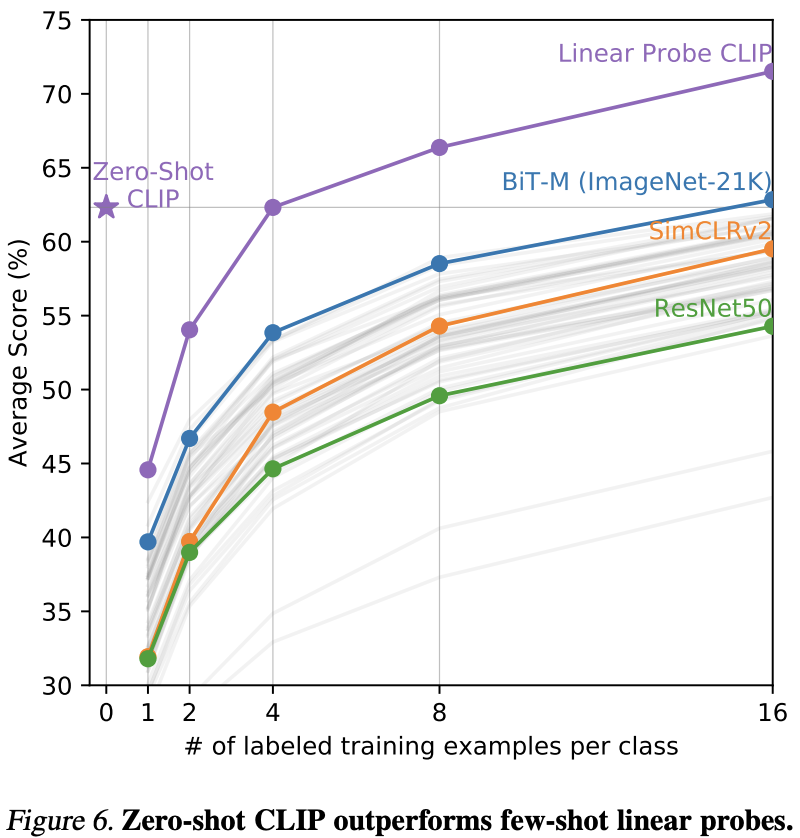
zero-shot CLIP이 16 shot BiT-M(21K)와 유사수준이다.
CLIP을 linear probe할 경우 16 shot BiT-L(21K)보다 더 좋은 성능을 보인다.

zero-shot CLIP과 linear probe CLIP의 성능 차이에 대한 그래프이다.
zero-shot CLIP이 충분히 좋은 성능을 보이며, 조금 더 학습할 경우 성능이 더 올라간다.
이 결과는 무엇인가 제대로 학습되었다라는 것을 증명한다.
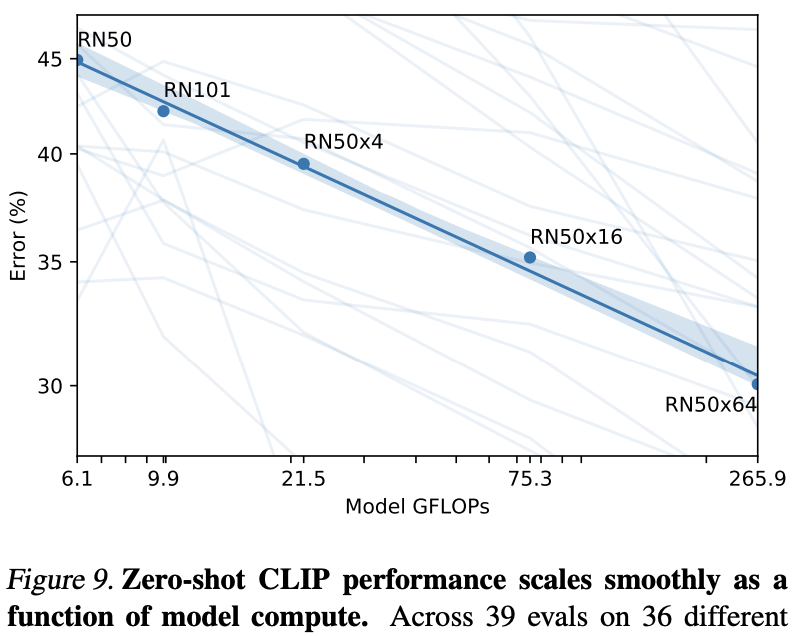
ResNet에 대하여 모델 크기에 따라 예쁘게 성능이 증가하는 것을 볼 수 있다.
1.3. Representation Learning

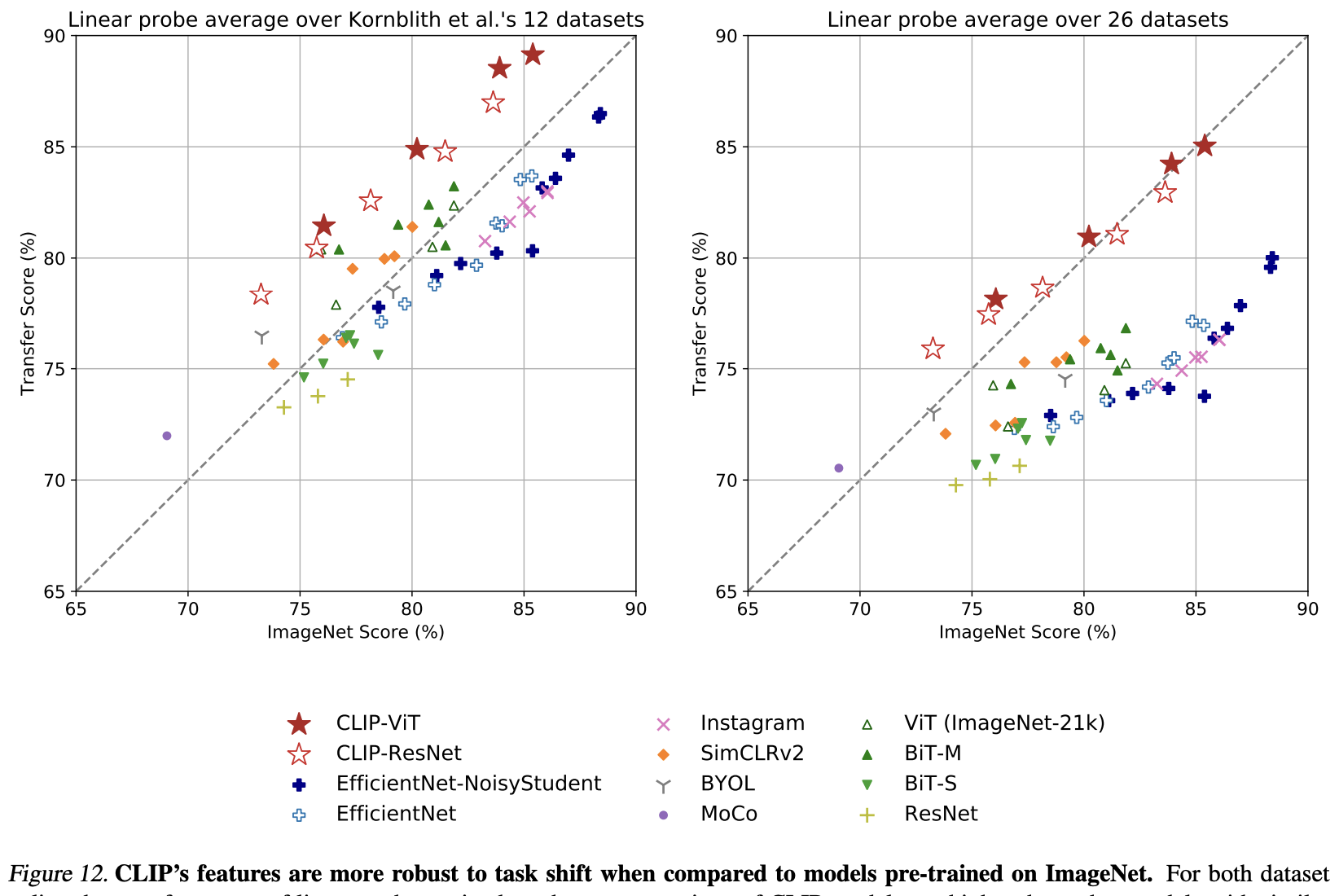
CLIP, ResNet, ViT, SimCLR, BiT, BYOL, MoCo 등 다양한 모델을 비교했다.
대상 데이터셋은 12개, 27개이며 결과를 평균해서 비교했다.
양쪽 실험 모두에서 CLIP이 가장 좋은 성능을 보였다.
1.4. Robustness to Natural Distribution Shift
이미지넷만 학습한 모델로 다른 모델을 평가한다.
양쪽 실험 모두에서 CLIP이 가장 좋은 성능을 보였다.
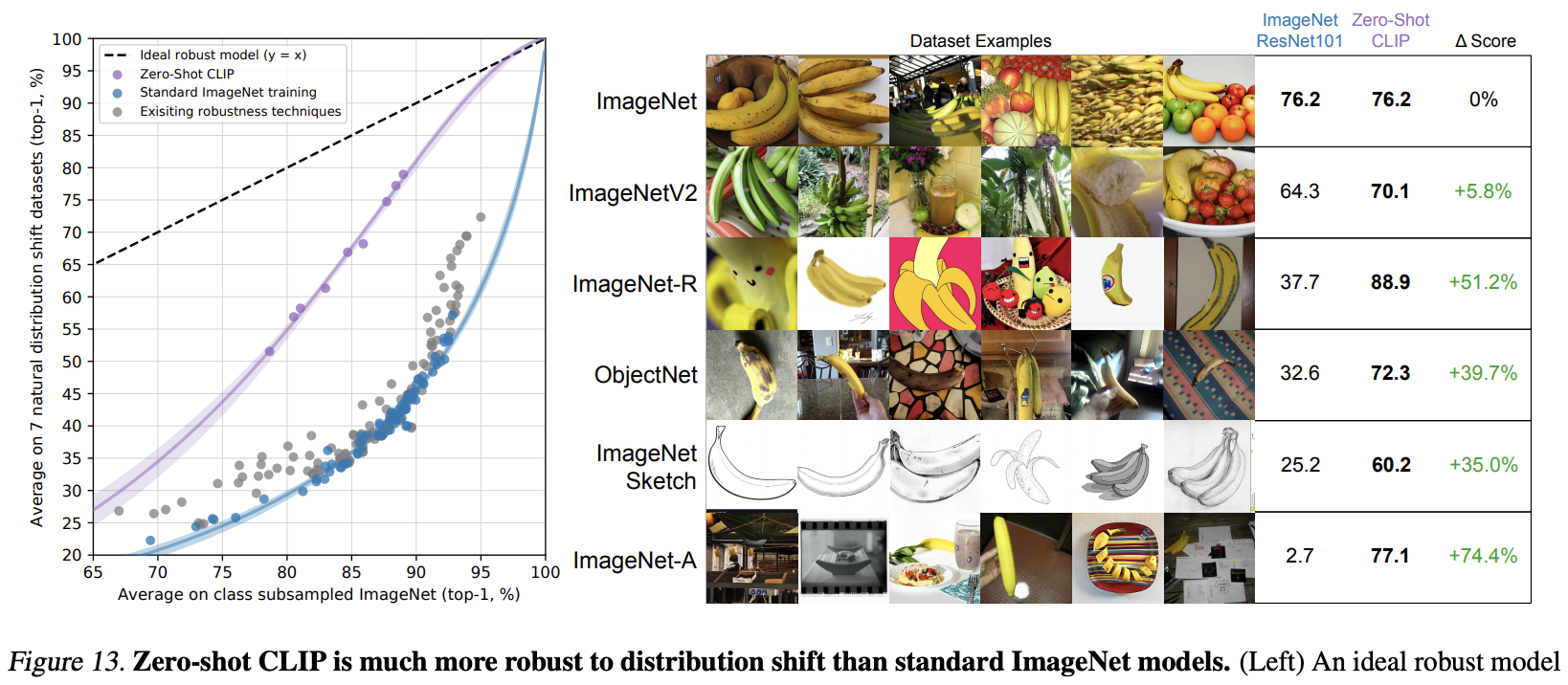
이미지넷을 변형한 V2, R, A, Sketch 등의 데이터셋에서 평가했다.
여기서도 CLIP이 가장 좋은 성능을 보였다.
2. Comparison to Human Performance
CLIP과 유사한 환경에서 인간의 퍼포먼스를 측정해 평가했다.
Oxford-IIT Pets 데이터셋의 약 3.7k개 이미지 (개 or 고양이 37개 품종)를 사용했다.
(ex. 개 사진 보여주고 이건 말티즈? 푸들? 이런 식)
(내생각: 위에서 CLIP 평가할 때 클래스 간 비슷한 데이터셋은
성능 안나온다면서 왜 굳이 이런 데이터셋을 골라서 했는지 모르겠음.
고양이 개 품종 구분하는건 사람 입장에서만 어려운거 아닌지 싶었다.
이게 인간 입장에서 진정한 제로샷이 아니지 않을까.)
제로샷에서는 인간에게 어떠한 품종 예시도 주지 않고 스스로 판단하게 했다.
원샷에서는 인간에게 각 품종의 샘플 이미지 한장을 주었고, 투샷은 두장을 주었다.
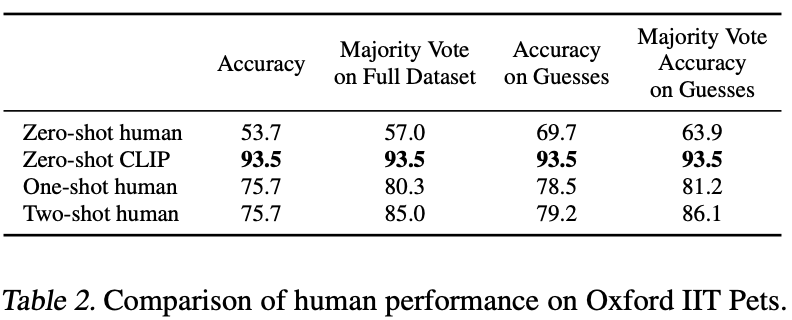
인간은 제로샷에서 54% -> 원샷에서 76%로 성능이 크게 올랐다.
인간의 성능을 CLIP과 비교할 경우 크게 떨어진다.
CLIP이 맞추지 못한 문제들은 대부분 인간도 맞추지 못했다.
3. Data Overlap Analysis
CLIP은 인터넷에서 모은 대규모 데이터셋으로 학습을 진행했다.
따라서 의도치 않게 downstream task의 데이터셋과 겹칠 가능성이 있다.
이를 방지하기 위해서 특정 threshold 이상의 유사도 이미지를 오염도로 측정했다.
또한 오염도를 완전히 제거하여 얼마나 성능이 떨어지는지도 평가했다.

그림이 매우 복잡하지만 결론은 오염이 크게 영향을 주지 않는다는 것이다.
가장 오버랩이 많이 되는 Country211 데이터셋 (21%)도 성능이 거의 동일하다.
4. Limitations
4.1. Task
첫번째로 fine-grained classification에서 성능이 낮다.
fine-grained는 매우 유사한 클래스들을 구별하는 것을 의미한다.
예를들어 차 종류, 꽃 품종, 비행기 모델 등이 있다.
두번째로 CLIP은 객체의 수를 세는 추상적이고 시스템적인 task에서 성능이 낮다.
마지막으로 거리를 측정하는 task에서 성능이 낮다.
4.2. Data Distribution
CLIP은 여전히 몇몇 비주류 데이터 분산에서 안좋은 성능을 보인다.
예를들어 사람의 손글씨인 MNIST에 대해서는 성능이 낮은 것을 볼 수 있다.
아이러니하게도 OCR의 성능은 매우 뛰어나다.
다시 말해서 학습한 데이터 분포에 없는 데이터에 대해서는 성능이 낮다.
4.3. Generative
CLIP은 다양한 downstream에서 좋은 zero-shot 성능을 보인다.
하지만 주어진 개념 중에서만 선택할 수 있다는 문제가 있다.
예를 들어서 이미지 캡셔닝과 같은 생성 작업을 수행할 수 없다.
4.4. Data Efficiency
CLIP은 여전히 데이터 효율성이 낮다고 봐야한다.
학습하는 모든 이미지를 1초씩 본다고 생각하면 무려 405년이다.
자기지도학습 (SSL)과 같은 방법을 결합하는 것은 좋은 방향이다.
4.5. Data Biases
CLIP은 인터넷 상의 이미지-텍스트 쌍으로 학습되었다.
따라서 다양한 사회적 편향 (social biases)을 같이 학습할 수 밖에 없다.
(ex. 성별, 인종, 민족 등에 대한 부정적인 편향)
4.6. Nature Language Limitations
CLIP은 자연어를 통해서 학습을 진행한다.
그런데 종종 어떤 task는 자연어로 표현하기 어려운 경우가 있다.
코드 및 구현
핵심 모듈만 발췌
class CLIP(nn.Module):
def __init__(self,
embed_dim: int,
# vision
image_resolution: int,
vision_layers: Union[Tuple[int, int, int, int], int],
vision_width: int,
vision_patch_size: int,
# text
context_length: int,
vocab_size: int,
transformer_width: int,
transformer_heads: int,
transformer_layers: int
):
super().__init__()
self.context_length = context_length
if isinstance(vision_layers, (tuple, list)):
vision_heads = vision_width * 32 // 64
self.visual = ModifiedResNet(
layers=vision_layers,
output_dim=embed_dim,
heads=vision_heads,
input_resolution=image_resolution,
width=vision_width
)
else:
vision_heads = vision_width // 64
self.visual = VisionTransformer(
input_resolution=image_resolution,
patch_size=vision_patch_size,
width=vision_width,
layers=vision_layers,
heads=vision_heads,
output_dim=embed_dim
)
self.transformer = Transformer(
width=transformer_width,
layers=transformer_layers,
heads=transformer_heads,
attn_mask=self.build_attention_mask()
)
self.vocab_size = vocab_size
self.token_embedding = nn.Embedding(vocab_size, transformer_width)
self.positional_embedding = nn.Parameter(torch.empty(self.context_length, transformer_width))
self.ln_final = LayerNorm(transformer_width)
self.text_projection = nn.Parameter(torch.empty(transformer_width, embed_dim))
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
self.initialize_parameters()
def initialize_parameters(self):
nn.init.normal_(self.token_embedding.weight, std=0.02)
nn.init.normal_(self.positional_embedding, std=0.01)
if isinstance(self.visual, ModifiedResNet):
if self.visual.attnpool is not None:
std = self.visual.attnpool.c_proj.in_features ** -0.5
nn.init.normal_(self.visual.attnpool.q_proj.weight, std=std)
nn.init.normal_(self.visual.attnpool.k_proj.weight, std=std)
nn.init.normal_(self.visual.attnpool.v_proj.weight, std=std)
nn.init.normal_(self.visual.attnpool.c_proj.weight, std=std)
for resnet_block in [self.visual.layer1, self.visual.layer2, self.visual.layer3, self.visual.layer4]:
for name, param in resnet_block.named_parameters():
if name.endswith("bn3.weight"):
nn.init.zeros_(param)
proj_std = (self.transformer.width ** -0.5) * ((2 * self.transformer.layers) ** -0.5)
attn_std = self.transformer.width ** -0.5
fc_std = (2 * self.transformer.width) ** -0.5
for block in self.transformer.resblocks:
nn.init.normal_(block.attn.in_proj_weight, std=attn_std)
nn.init.normal_(block.attn.out_proj.weight, std=proj_std)
nn.init.normal_(block.mlp.c_fc.weight, std=fc_std)
nn.init.normal_(block.mlp.c_proj.weight, std=proj_std)
if self.text_projection is not None:
nn.init.normal_(self.text_projection, std=self.transformer.width ** -0.5)
def build_attention_mask(self):
# lazily create causal attention mask, with full attention between the vision tokens
# pytorch uses additive attention mask; fill with -inf
mask = torch.empty(self.context_length, self.context_length)
mask.fill_(float("-inf"))
mask.triu_(1) # zero out the lower diagonal
return mask
@property
def dtype(self):
return self.visual.conv1.weight.dtype
def encode_image(self, image):
return self.visual(image.type(self.dtype))
def encode_text(self, text):
x = self.token_embedding(text).type(self.dtype) # [batch_size, n_ctx, d_model]
x = x + self.positional_embedding.type(self.dtype)
x = x.permute(1, 0, 2) # NLD -> LND
x = self.transformer(x)
x = x.permute(1, 0, 2) # LND -> NLD
x = self.ln_final(x).type(self.dtype)
# x.shape = [batch_size, n_ctx, transformer.width]
# take features from the eot embedding (eot_token is the highest number in each sequence)
x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection
return x
def forward(self, image, text):
image_features = self.encode_image(image)
text_features = self.encode_text(text)
# normalized features
image_features = image_features / image_features.norm(dim=1, keepdim=True)
text_features = text_features / text_features.norm(dim=1, keepdim=True)
# cosine similarity as logits
logit_scale = self.logit_scale.exp()
logits_per_image = logit_scale * image_features @ text_features.t()
logits_per_text = logits_per_image.t()
# shape = [global_batch_size, global_batch_size]
return logits_per_image, logits_per_text
'논문리뷰' 카테고리의 다른 글
| [논문 리뷰] NGCF 요약, 코드, 구현 (0) | 2025.12.18 |
|---|---|
| [논문 리뷰] DeepFM 요약, 코드, 구현 (0) | 2025.12.18 |
| [논문 리뷰] GCN 요약, 코드, 구현 (6) | 2025.08.03 |
| [논문 리뷰] LLaMA v1 요약, 코드, 구현 (0) | 2025.03.31 |
| [논문 리뷰] data2vec 요약, 코드, 구현 (3) | 2024.07.16 |



