논문을 상세히 번역하고 한단어씩 해석해주는 포스팅은 많다.
나는 논문을 누구나 알아듣도록 쉽고 간결하게 전달하고자 한다.
data2vec
저자의 의도
general self-supervised learning에 대한 연구이다.
speech, NLP, CV에서 모두 동일한 러닝 메서드를 사용한 data2vec을 제안한다.
아이디어는 마스킹 인풋을 받아 원본 인풋의 representation을 예측하는 것이다.
word 같은 특정 모달리티의 타겟이 아니라 컨텍스트화된 representation을 예측한다.
기존 문제점
SSL 연구는 각 모달리티에 집중되어 왔는데, 이건 특정 학습 편향을 유발한다.
이 학습 편향은 해당 모달리티에서는 도움이 되지만 다른 모달리티로 일반화할 수 없다.
사람은 실제로 시각 세계를 이해할 때 언어를 이해할 때와 유사한 러닝 프로세스를 거친다.
그런데 뉴럴 네트워크 모델들은 각 모달리티에 따로따로 별개로 학습되고 있다.
해결 아이디어
1. data2vec overview
제너럴한 환경을 이해하기 위해 여러 모달리티에서 동일한 objective로 학습해보자.
현재는 각 모델을 학습한 후 통합하는데, 1개의 알고리즘을 사용해 한번에 학습해보자.
저자들은 각 모달리티의 masked prediction(BERT, BEiT, wave2vec)을 합쳤다.
latent 타겟을 학습한 뒤 멀티 헤드를 통과해 각 모달리티의 타겟으로 일반화한다.

Transformer를 teacher 모드, student 모드로 사용해 학습한다.
teacher 모드로 전체 인풋에 대한 representation을 추출하고 타겟으로 사용한다. (Fig 1의 윗부분)
student 모드로 masked 인풋에 대한 representation을 추출한다. (Fig 1의 아랫부분)
이를 바탕으로 전체 인풋에 대한 representation을 예측한다. (Fig 1에서 아래를 보고 위를 예측)
teacher의 웨이트는 student의 exponentially decaying average 값이다.
타겟이 연속된 값이고 컨텍스트화 되어있기 때문에 기존 모델보다 representation이 풍부하다.
이제 이 내용을 더 자세하게 살펴보겠다.
2. Method
핵심은 인풋 데이터의 일부를 보고 전체 인풋 데이터를 예측하는 것이다.
student 모델을 학습시키며 EMA 값으로 teacher 모델을 학습한다.
2-1. Model architecture
스탠다드 Transformer를 사용하며 각각의 모달리티에 맞는 인코딩을 한다.
CV는 BEiT, speech는 wave2vec, text는 BERT를 사용한다.

2-2. Masking
인풋 샘플이 토큰 시퀀스로 임베딩된 후 일부를 마스킹 해준다.
마스킹된 시퀀스를 위에서 말한 Transformer에 넣는다.
마찬가지로 BEiT, wave2vec, BERT의 전략을 각각 따른다.
(각 모달리티 마다 마스킹 전략이 다를텐데 각 모델을 그대로 계승)
2-3. Training target
student 모델은 마스킹되지 않은 원본 샘플의 representation을 예측한다.
입력 데이터 중에서 마스킹을 한 해당 타임 스텝의 representation만 예측한다.
(타임 스텝 개념을 자꾸 강조하는데 이건 wav에 해당하는 내용)
2-4. Teacher parameterization
teacher 모델은 마스킹되지 않은 원본 샘플의 representation을 인코딩한다.
이 파라미터는 exponentially moving average (EMA)로 업데이트 된다.

EMA는 SSL에 자주 등장하는 내용이다.
한문장으로 말하면 '과거 이터레이션에서 학습하며, 천천히 학습된다.' 라고 할 수 있다.
teacher 업데이트를 자기 자신인 student의 직전 값으로 하는데,
그 값을 다 반영하는게 아니라 0.4% 정도만 업데이트 한다.
(이 업데이트 양은 점점 줄인다.)
2-5. Objective

컨텍스트화된 타겟 y_t가 주어지면, Smooth L1 loss를 사용한다.
β는 MSE loss와 L1 loss 간에 변환을 컨트롤한다.
타겟 y_t와 모델의 예측값 f(x)_t 간의 갭에 따라 결정된다.
갭이 β보다 작으면 MSE, 크면 L1 으로 계산된다.
Smooth L1의 장점은 이상값(outliers)에 대하여 민감하게 반응하지 않는다.
결과 분석
1. Result
1-1. Computer vision

여기서 싱글 모델이란 별개의 토크나이저를 사용하지 않은 모델이다.
멀티플 모델은 외부 데이터로 학습한 VAE와 같은 토크나이저를 사용한다.
ViT-B는 세팅에서는 가장 뛰어났다.
ViT-L은 전체 모델 중에서 가장 뛰어났다.
기존의 픽셀을 예측하는 것보다 latent representation을 예측하는 것이 좋다.
1-2. Speech, NLP
필자는 이 두 분야에 전문가가 아니기에 제대로된 분석을 할 수 없으니 이해해주기 바란다.

speech에서 최고 아웃풋

NLP에서 BERT, RoBERT 보다 좋은 결과
2. Ablations

타겟 representation을 많이 컨텍스트화 할수록 좋은 결과
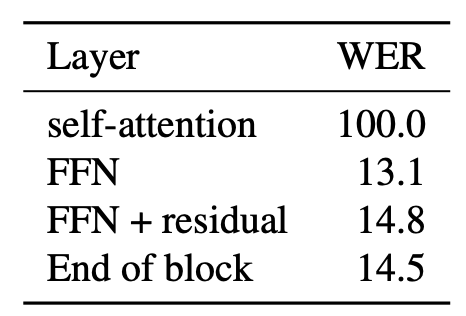
타겟 feature를 어텐션 레이어가 아닌 FFN으로 변경 시 안좋은 결과
코드 및 구현
forward 부분 발췌
def forward(self, src, trg=None, mask=None, **kwargs):
"""
Data2Vec forward method.
Args:
src: src tokens (masked inputs for training)
trg: trg tokens (unmasked inputs for training but left as `None` otherwise)
mask: bool masked indices, Note: if a modality requires the inputs to be masked before forward this param
has no effect. (see the Encoder for each modality to see if it uses mask or not)
Returns:
Either encoder outputs or a tuple of encoder + EMA outputs
"""
# model forward in online mode (student)
x = self.encoder(src, mask, **kwargs)['encoder_out'] # fetch the last layer outputs
if trg is None:
return x
# model forward in offline mode (teacher)
with torch.no_grad():
self.ema.model.eval()
y = self.ema.model(trg, ~mask, **kwargs)['encoder_states'] # fetch the last transformer layers outputs
y = y[-self.cfg.model.average_top_k_layers:] # take the last k transformer layers
# Follow the same layer normalization procedure for text and vision
if self.modality in ['vision', 'text']:
y = [F.layer_norm(tl.float(), tl.shape[-1:]) for tl in y]
y = sum(y) / len(y)
if self.cfg.model.normalize_targets:
y = F.layer_norm(y.float(), y.shape[-1:])
# Use instance normalization for audio
elif self.modality == 'audio':
y = [F.instance_norm(tl.float()) for tl in y]
y = sum(y) / len(y)
if self.cfg.model.normalize_targets:
y = F.instance_norm(y.transpose(1, 2)).transpose(1, 2)
x = x[mask]
y = y[mask]
x = self.regression_head(x)
return x, y
'논문리뷰' 카테고리의 다른 글
| [논문 리뷰] GCN 요약, 코드, 구현 (6) | 2025.08.03 |
|---|---|
| [논문 리뷰] LLaMA v1 요약, 코드, 구현 (0) | 2025.03.31 |
| [논문 리뷰] iBOT 요약, 코드, 구현 (0) | 2024.07.11 |
| [논문 리뷰] DINO 요약, 코드, 구현 (0) | 2024.07.11 |
| [논문 리뷰] CAE(Context Autoencoder) 요약, 코드, 구현 (0) | 2024.06.25 |



