논문을 상세히 번역하고 한단어씩 해석해주는 포스팅은 많다.
나는 논문을 누구나 알아듣도록 쉽고 간결하게 전달하고자 한다.
LLaMA v1
참고로 LLaMA는 Large Language model Meta AI의 줄임말이다.
저자의 의도
7B ~ 65B 크기의 foundation language 모델을 만든다.
독점적이고 비공개된 데이터가 아니라 오픈 데이터로 SOTA를 달성해보자.
저자들은 리서치 커뮤니티에 모델의 모든 정보를 공개했다.
기존 문제점
요즘 LLM 연구들은 모델 사이즈가 성능에 비례한다는 가정을 가진다.
기존 모델들은 학습 예산만 고려하고 추론 예산에 대하여 고려하지 않는다.
(학습 예산과 추론 예산은 아래에서 설명하겠다.)
친칠라, PaLM, GPT-3는 본인들만 접근할 수 있는 클로즈 데이터셋을 사용한다.
해결 아이디어
1. 1T 학습 토큰 모델과 학습 예산
approach에 앞서 친칠라 논문을 먼저 분석해본다.
더 작은 사이즈의 모델도 더 많은 데이터로 학습하면 성능이 좋다.
친칠라는 오직 `학습 예산`에서 모델 사이즈와 데이터셋 사이즈의 최적의 조합을 찾는다.
저자들은 이 논문이 `추론 예산`를 무시하고 있다고 말한다.
모델을 연구하는 사람은 학습이 중요한데 서비스하는 사람은 추론이 중요하다.
학습하는데 오래걸리더라도 실제 구동할때 더 빠르게 동작하는게 좋다는 이야기다.
저자들의 주장은 아래와 같다.
성능의 타겟 레벨을 고정했을 때, 학습이 빠른 모델보다 추론이 빠른 모델이 더 좋다.
비록 학습이 빠른 모델은 연구에서 비용이 싸지만, 추론이 빠른 모델이 서비스에서 더 싸다.
서비스에서 더 싼 것이 궁극적으로 더 유리할 수 있다.
이 관점에서 기존 모델 (친칠라) 보다 더 많은 학습 토큰으로 훈련해보자.
학습 토큰 수를 늘린 모델으로 다양한 `추론 예산`에서 최상의 성능 모델을 훈련한다.
2. Overview

LLaMA 논문의 목적을 한문장으로 줄이면 다음과 같다.
대규모 데이터셋에 대하여 대규모 트랜스포머를 기존 옵티마이저를 사용해 학습한다.
3. Pre-training Data
LLM은 기본적으로 트랜스포머 구조를 가진다.
트랜스포머 구조는 기본적으로 사전학습을 통해 큰 장점을 보인다.
LLaMA는 이 사전학습에 오픈소스 데이터셋만 사용했고 7종을 섞어서 사용했다.
[사용한 데이터셋]
CC: CCNet의 소스 데이터셋으로 크롤링 데이터셋, 영어 외 제거, 저퀄 제거
C4: 다른 크롤링 데이터셋, CommonCrawl을 다양하게 넣을수록 성능이 좋아지므로 사용
Github: 깃허브 데이터셋, 구글 빅쿼리로 접근 가능
Wikipedia: 20개 국어의 위키피디아 데이터셋, 라틴어 키릴어 계열 20개 언어
Gutenberg, Books3: 구텐베르크 프로젝트와 ThePile의 Books3 섹션 데이터셋
ArXiv: 아카이브 레이텍 파일 데이터셋, 과학 데이터셋 추가 용도
Stack Exchange: 스택 익스체인지 사이트 자료 데이터셋, 다양한 도메인의 질문과 답변
토크나이저는 서브워드 기법인 BPE (Byte Pair Encoding)를 사용했다.
토크나이저는 텍스트를 LLM이 처리할 수 있는 단위인 '토큰(token)'으로 나누는 도구이다.
즉 사람이 보는 단어를 LLM이 알아듣는 단어로 바꾸는 도구이다.
토큰은 실제 영어 단어 혹은 한글의 1개 글자보다 약간 더 큰 편이다.
토크나이제이션이 끝나면 약 1.4T 크기의 토큰이 포함된다.
에포크 수를 보면 위키피디아와 Books 2개 빼고 나머지는 단 1번만 학습에 사용된다.
4. Architecture
트랜스포머 아키텍처에 다양한 개선 메서드를 적용했다.
LLM은 기본적으로 트랜스포머 구조의 디코더만을 연결해 만든다.
4-1. Pre-normalization
GPT-3에서 영감을 얻은 메서드이다.
아웃풋 시 norm을 하는게 아니라 인풋 전에 norm을 한다.
학습의 안정성을 개선하는 효과가 있다.
norm은 RMSNorm을 사용한다.
4-2. SwiGLU
PaLM에서 영감을 얻은 메서드이다.
활성화 함수 ReLU를 SwiGLU로 모두 대체한다.
성능이 향상되는 효과가 있다.
4-3. Rotary Embeddings
GPTNeo에서 영감을 얻은 메서드이다.
기존의 absolute 포지션 임베딩을 rotary 포지션 임베딩으로 대체한다.
5. Optimizer
AdamW 인데 일반적으로 쓰는 β_2인 0.999 보다 낮은 0.95를 사용한다.
예전 학습 배치보다 최근 학습 배치의 기울기 영향력을 더 높인 것이다.
학습 속도가 더 빨라지지만 안정성이 감소할 수 있다.
코사인 어닐링과 웜업 2가지 메서드도 사용한다.
(cosine learning rate from 100% to 10%, 2000 warm-up)
6. 효율성 개선
효율성 개선을 위해 3가지 추가 메서드를 사용한다.
1. causal multi-head attention (=Masked MHSA)을 사용한다.
디코더 기반 모델이 주로 사용하는 것으로 어텐션 웨이트를 저장할 필요 없다.
2. 백워드 마다 다시 계산해야하는 활성화 값을 저장해두고 사용한다.
3. 각 GPU는 활성화 값 계산과 GPU 간 소통을 순차적이 아닌 동시에 진행한다.
2048대의 A100으로 21일이면 학습할 수 있다.
결과 분석
1. Main results
학습들의 상세 내용은 다음과 같다.
Zero-shot: task에 대한 설명과 테스트 예제 입력, 개방형 생성 or 답변 순위 출력
Few-shot: 몇몇의 예제와 정답과 테스트 예제 입력, 개방형 생성 or 답변 순위 출력
Open-ended generation: 개방형 생성, AI의 자유로운 답변
Ranking proposed answers: 답변 순위, 여러 가능한 답변 중에 순위 매기기
주로 GPT-3, Gopher, Chinchilla, PaLM 등과 비교했다.
1-1. Common Sense Reasoning
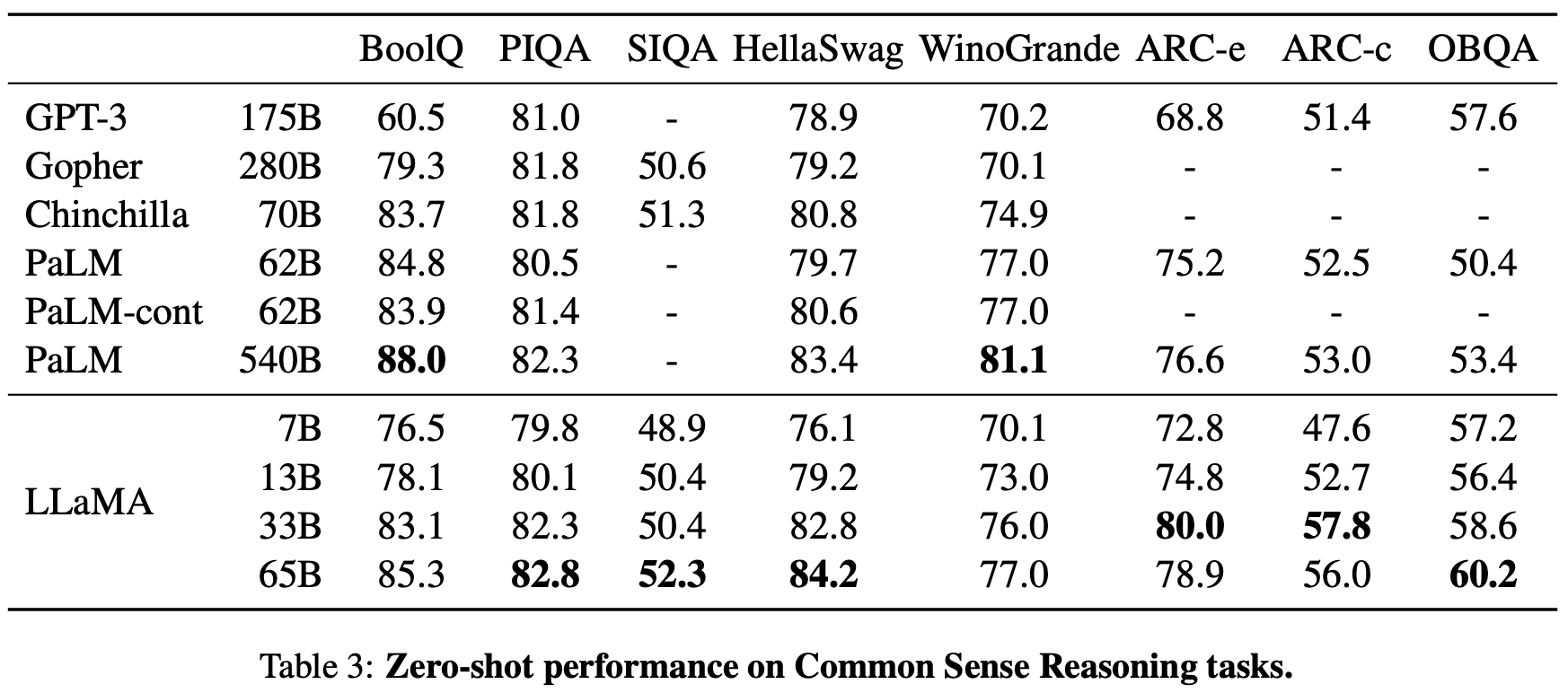
상식 추론에는 벤치마크의 종류가 많은데 다음과 같다.
BoolQ, PIQA, SIQA, HellaSwag, WinoGrande, ARC easy and challenge, OBQA
이 벤치마크들이 포함하는 task는 다음과 같다.
Cloze task: 빈칸 맞추기 문제
Winograd task: 문장 내 대명사 맞추기 문제
테이블을 보고 결과를 분석해보자.
PaLM과 비교했을 때 크기는 작은데 Winograd 외에 모든 평가에서 성능이 좋다.
특이한 점은 ARC는 65B 보다 13B 에서 더 좋은 성능을 보인다.
1-2. Closed-book Question Answering
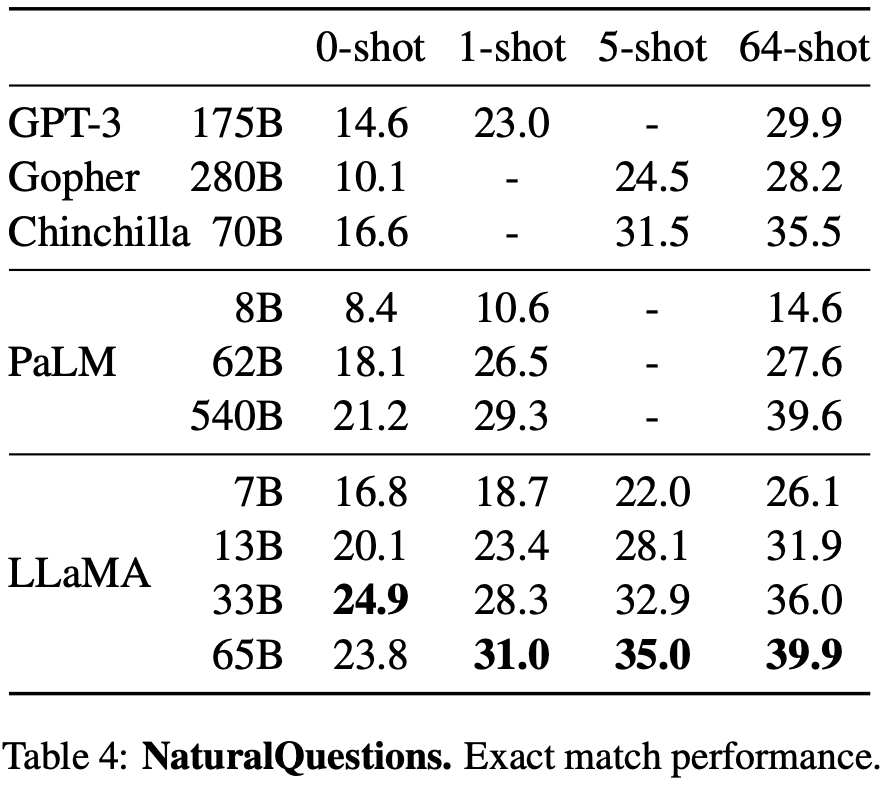
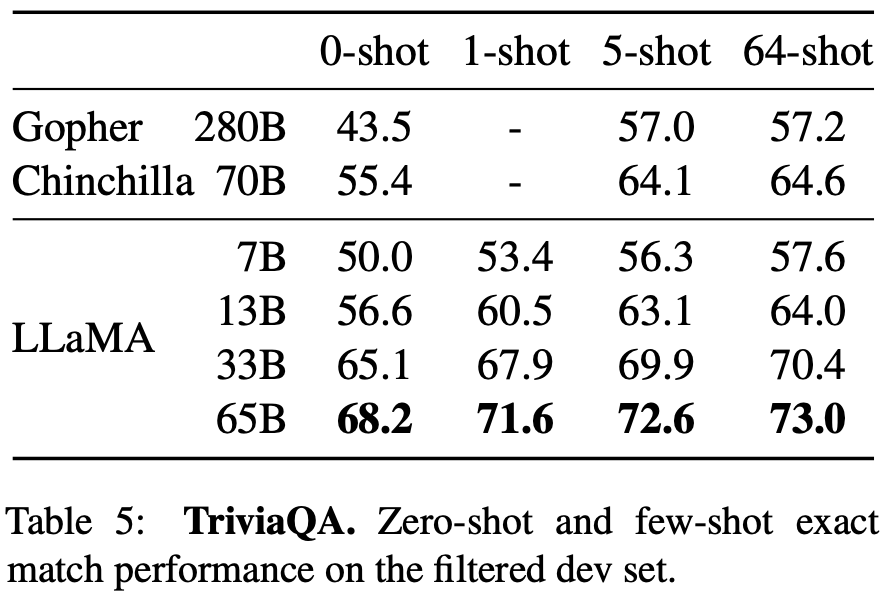
클로즈북 질문과 답변은 NaturalQuestions, TriviaQA 2가지 벤치 마크가 있다.
질문을 답할 수 있는 근거를 포함한 문서를 접근하지 않고 대답한다.
테이블을 보고 결과를 분석해보자.
65B가 0 shot, few shot 평가에서 SOTA를 달성했다.
3B 크기만 해도 기존 모델과 견줄만한 성능이다.
특이한 점은 NaturalQuestions 0 shot에서 33B가 성능이 더 좋다.
1-3. Reading Comprehension

독해력은 RACE 벤치마크에서 진행된다.
RACE는 중국 학생들의 영어 교육에 사용되는 독해 문제 자료이다.
65B 모델이 PaLM-540B 수준이며, 13B 모델이 GPT-3 보다 성능이 좋다.
1-4. Mathematical reasoning

수학관련 벤치마크는 MATH, GSM8k 2개에서 진행했다.
MATH: 레이텍으로 작성된 중고등학교 수학 문제 12k
GSM8k: 중학교 수학 문제 세트
maj1@k 방법: k개의 답변을 생성하고 그 중 가장 빈도가 높은 답변 선택
Minerva는 PaLM을 수학 데이터셋으로 fine-tuning 한 모델이다.
65B 모델은 파인튜닝을 하지 않았지만 비슷한 크기의 Minerva-62B 보다 좋은 성능이다.
하지만 SOTA를 달성하지 못했으며 PaLM 보다도 낮은 성능이다.
1-5. Code generation
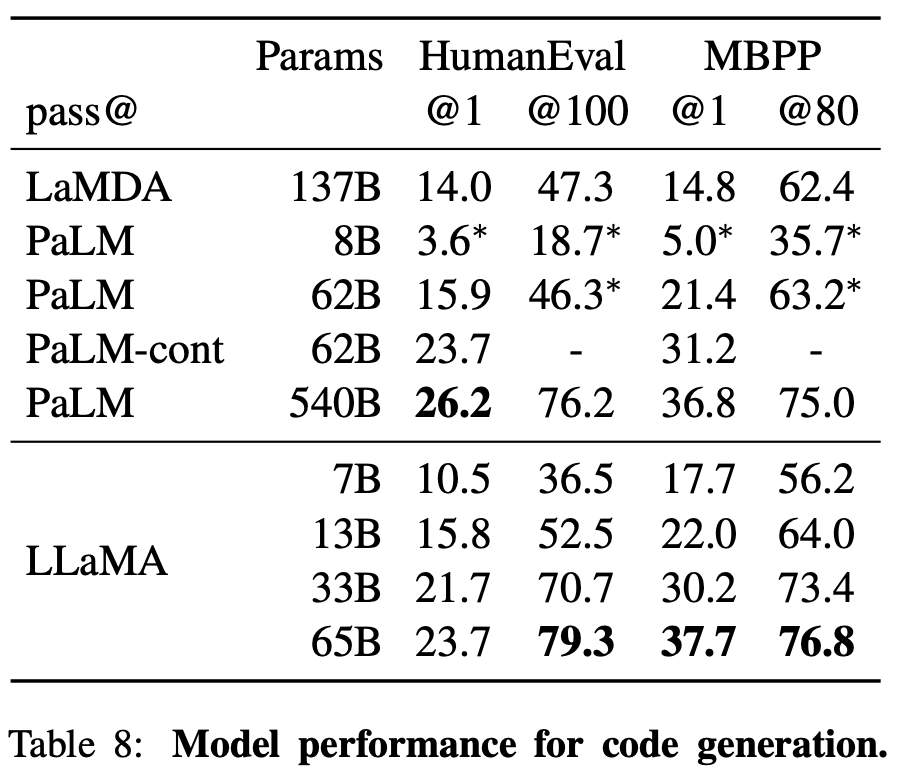
코드 생성은 HumanEval, MBPP 2가지 벤치마크를 진행했다.
프로그램에 대한 설명 제공 후 코딩, 인풋-아웃풋 예제로 코드를 평가한다.
HumanEval의 @1을 제외하면 모든 테스트에서 가장 좋은 성능을 보인다. (오픈소스 한정)
PaLM-cont 모델은 기존보다 더 길게 학습한 모델인데, 비슷한 크기의 LLaMA의 성능이 더 좋다.
모든 모델은 코드 특화 토큰으로 fine-tuning을 더 하면 성능이 올라간다.
여기서 오픈소스끼리 비교하는 것에 주목해야한다.
코딩분야에 있어서 오픈소스 LLM은 비벼볼만한 성적이 아니다.
현재(2025년 3월 기준)도 딥시크 R1 외에는 리더보드에서 찾기 힘들다.
LLaMA가 처음 나올 시절에는 더 심했다.
(LLM의 성적 비교 리더보드는 여기.)
1-6. Massive Multitask Language Understanding (MMLU)

MMLU는 인문학, 공학, 사회과학 등 다양한 도메인에 대한 다중 정답 문제 평가하는 벤치마크 이다.
5 shot에서 평가하는 것을 기본값으로 하며 table 9의 값도 그러하다.
LLaMA는 PaLM 이나 Chinchilla에 비해 안좋은 성능이다.
저자들은 오픈 데이터셋이 논문이나 책이 부족하기 때문으로 분석했다.
1-7. Instruction Finetuning
간단한 fine-tuning으로 MMLU가 급격하게 향상되었다.
이 내용은 별도로 LLaMA-I 라는 모델명으로 다른 논문에서 발표했다.
2. Bias, Toxicity and Misinformation
(생략)
코드 및 구현
핵심 모듈인 LLaMA, Transformer, Tokenizer 발췌
class LLaMA:
def __init__(self, model: Transformer, tokenizer: Tokenizer):
self.model = model
self.tokenizer = tokenizer
def generate(
self,
prompts: List[str],
max_gen_len: int,
temperature: float = 0.8,
top_p: float = 0.95,
) -> List[str]:
bsz = len(prompts)
params = self.model.params
assert bsz <= params.max_batch_size, (bsz, params.max_batch_size)
prompt_tokens = [self.tokenizer.encode(x, bos=True, eos=False) for x in prompts]
min_prompt_size = min([len(t) for t in prompt_tokens])
max_prompt_size = max([len(t) for t in prompt_tokens])
total_len = min(params.max_seq_len, max_gen_len + max_prompt_size)
tokens = torch.full((bsz, total_len), self.tokenizer.pad_id).cuda().long()
for k, t in enumerate(prompt_tokens):
tokens[k, : len(t)] = torch.tensor(t).long()
input_text_mask = tokens != self.tokenizer.pad_id
start_pos = min_prompt_size
prev_pos = 0
for cur_pos in range(start_pos, total_len):
logits = self.model.forward(tokens[:, prev_pos:cur_pos], prev_pos)
if temperature > 0:
probs = torch.softmax(logits / temperature, dim=-1)
next_token = sample_top_p(probs, top_p)
else:
next_token = torch.argmax(logits, dim=-1)
next_token = next_token.reshape(-1)
# only replace token if prompt has already been generated
next_token = torch.where(
input_text_mask[:, cur_pos], tokens[:, cur_pos], next_token
)
tokens[:, cur_pos] = next_token
prev_pos = cur_pos
decoded = []
for i, t in enumerate(tokens.tolist()):
# cut to max gen len
t = t[: len(prompt_tokens[i]) + max_gen_len]
# cut to eos tok if any
try:
t = t[: t.index(self.tokenizer.eos_id)]
except ValueError:
pass
decoded.append(self.tokenizer.decode(t))
return decoded
class Transformer(nn.Module):
def __init__(self, params: ModelArgs):
super().__init__()
self.params = params
self.vocab_size = params.vocab_size
self.n_layers = params.n_layers
self.tok_embeddings = ParallelEmbedding(
params.vocab_size, params.dim, init_method=lambda x: x
)
self.layers = torch.nn.ModuleList()
for layer_id in range(params.n_layers):
self.layers.append(TransformerBlock(layer_id, params))
self.norm = RMSNorm(params.dim, eps=params.norm_eps)
self.output = ColumnParallelLinear(
params.dim, params.vocab_size, bias=False, init_method=lambda x: x
)
self.freqs_cis = precompute_freqs_cis(
self.params.dim // self.params.n_heads, self.params.max_seq_len * 2
)
@torch.inference_mode()
def forward(self, tokens: torch.Tensor, start_pos: int):
_bsz, seqlen = tokens.shape
h = self.tok_embeddings(tokens)
self.freqs_cis = self.freqs_cis.to(h.device)
freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen]
mask = None
if seqlen > 1:
mask = torch.full((1, 1, seqlen, seqlen), float("-inf"), device=tokens.device)
mask = torch.triu(mask, diagonal=start_pos + 1).type_as(h)
for layer in self.layers:
h = layer(h, start_pos, freqs_cis, mask)
h = self.norm(h)
output = self.output(h[:, -1, :]) # only compute last logits
return output.float()
class Tokenizer:
def __init__(self, model_path: str):
# reload tokenizer
assert os.path.isfile(model_path), model_path
self.sp_model = SentencePieceProcessor(model_file=model_path)
logger.info(f"Reloaded SentencePiece model from {model_path}")
# BOS / EOS token IDs
self.n_words: int = self.sp_model.vocab_size()
self.bos_id: int = self.sp_model.bos_id()
self.eos_id: int = self.sp_model.eos_id()
self.pad_id: int = self.sp_model.pad_id()
logger.info(
f"#words: {self.n_words} - BOS ID: {self.bos_id} - EOS ID: {self.eos_id}"
)
assert self.sp_model.vocab_size() == self.sp_model.get_piece_size()
def encode(self, s: str, bos: bool, eos: bool) -> List[int]:
assert type(s) is str
t = self.sp_model.encode(s)
if bos:
t = [self.bos_id] + t
if eos:
t = t + [self.eos_id]
return t
def decode(self, t: List[int]) -> str:
return self.sp_model.decode(t)
실제 구동 코드 (README 참고)
pip install -r requirements.txt
pip install -e .
torchrun --nproc_per_node MP example.py --ckpt_dir $TARGET_FOLDER/model_size --tokenizer_path $TARGET_FOLDER/tokenizer.model
example.py에서 main을 보고 수정하면 된다.
'논문리뷰' 카테고리의 다른 글
| [논문 리뷰] data2vec 요약, 코드, 구현 (3) | 2024.07.16 |
|---|---|
| [논문 리뷰] iBOT 요약, 코드, 구현 (0) | 2024.07.11 |
| [논문 리뷰] DINO 요약, 코드, 구현 (0) | 2024.07.11 |
| [논문 리뷰] CAE(Context Autoencoder) 요약, 코드, 구현 (0) | 2024.06.25 |
| [논문 리뷰] LLaVA-UHD 요약, 코드, 구현 (1) | 2024.06.19 |



