논문을 상세히 번역하고 한단어씩 해석해주는 포스팅은 많다.
나는 논문을 누구나 알아듣도록 쉽고 간결하게 전달하고자 한다.
DeepFM

저자의 의도
기존의 방법론은 low-order 혹은 high-order 상호작용에 강한 편향이 존재한다.
low-order와 high-order 상호작용을 모두 효과적으로 모델링할 수 있는 방법론을 제시한다.
DeepFM은 별도의 피처 엔지니어링이 필요 없으며 FM과 DNN을 모두 활용하는 모델이다.
기존 문제점
1. Low-order or High-order 편향
FM은 이론적으로 고차원을 모델링할 수 있도록 설계되었다.
하지만 실제로는 2차 상호작용 (low-order bias)에 집중하는 경향이 있다.
CNN 기반 모델은 근접 피처들의 상호작용만 보는 bias가 존재한다. (receptive field)
RNN 기반 모델은 시퀀셜 클릭 데이터에서만 효과적이다.
2. 전문 Feature Engineering 요구
Wide & Deep은 low-order와 high-order 상호작용을 모두 모델링할 수 있다.
하지만 Wide & Deep의 Wide 파트를 위해서는 별도의 피처 엔지니어링이 필요하다.
3. 사전학습 필요
FNN은 FM으로 임베딩을 사전학습한 뒤 DNN에 입력하는 모델이다.
이런 기존 모델은 사전학습을 따로 해줘야하기 때문에 비효율적이다.
해결 아이디어
1. DeepFM 개요
DeepFM은 FM과 DNN을 결합한 모델이다.
FM이 low-order 상호작용을, DNN이 high-order 상호작용을 모델링한다.
Wide & Deep과 달리 별도의 피처 엔지니어링이 필요없다.
Wide & Deep과 달리 효율적으로 학습할 수 있다. (인풋과 임베딩을 공유)
2. 데이터셋 및 Task 정의
n: 데이터 개수, (X, y) 개수
X: 수집된 피처로 구성된 유저-아이템 pairwise 데이터, m차원
y: 클릭 여부 {0, 1}, 레이블
x: X에서 카테고리컬은 원핫 인코딩된 벡터, d차원
이 task는 기본적으로 매우 고차원이며 희소하다.
CTR 예측은 y=model(x)으로 유저의 클릭 확률 예측 문제로 정의된다.
3. DeepFM
DeepFM은 2개의 컴포넌트 (Deep, FM)로 구성되며 입력을 공유한다.

i: 피처
w_i: i번째 피처의 가중치
V_i: i번째 피처의 k차원 latent 벡터 (order-1)
y: CTR 예측값, {0, 1}
V_i는 FM 컴포넌트에 입력되어 2차 상호작용을 모델링한다.
이 결과는 다시 Deep 컴포넌트에 입력되어 고차 상호작용을 모델링한다.
3.1. FM 컴포넌트

factorization machine으로 추천을 위한 상호작용을 학습한다.
linear 상호작용 (order-1)과 pairwise 상호작용 (order-2)을 모델링한다.
특히 데이터가 희소(sparse, 0이 많음)할 때 더 효과적이다.
기존 접근법은 feature i와 j의 상호작용을 직접 모델링한다.
다시 말해서 한 개의 데이터 row (=기록)에서 i와 j가 모두 존재해야만 한다.
하지만 FM은 latent 벡터 V_i와 V_j의 내적을 통해 상호작용을 모델링한다.
따라서 i와 j가 동시에 존재하지 않아도 상호작용을 모델링할 수 있다.

y_FM: FM 컴포넌트의 출력
첫번째 항: 덧셈 유닛, linear 상호작용 (order-1)
두번째 항: 내적 유닛, pairwise 상호작용 (order-2)
3.2. Deep 컴포넌트

고차원 상호작용을 모델링하기 위해 DNN을 활용한다. (특히 FFN)
벡터가 신경망을 통과하면서 고차원 상호작용을 학습한다.
연속적이고 밀도 높은 이미지나 오디오 데이터와 CTR 예측의 입력은 다르다.
sparse (희소)하고, ID는 빌리언 스케일 고차원이고, 데이터가 mixed 하다.
데이터가 mixed 한 것은 카테고리컬 데이터와 연속형 데이터가 섞인 형태를 의미한다.
따라서 첫번째 레이어 전에 데이터를 압축하고 저차원으로 바꾸는 임베딩 레이어가 필요하다.
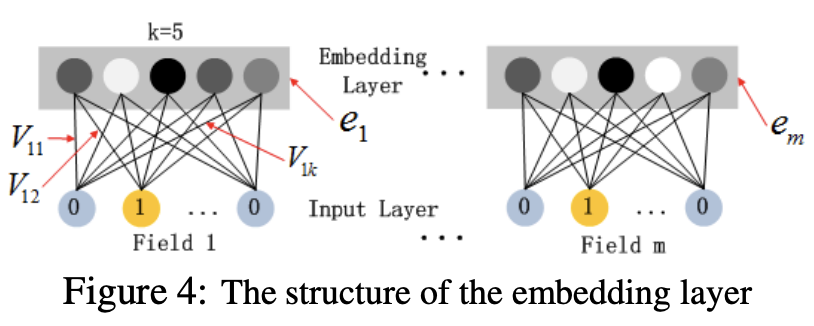
서브 네트워크인 임베딩 레이어에 대한 그림이다.
인풋을 임베딩으로 변환하는 과정을 보여준다.
2가지 핵심 포인트를 고려해야한다.
첫번째는, 인풋 벡터는 길이가 다를 수 있지만, 임베딩 벡터는 고정된 k 길이를 가진다.
두번째는, latent 벡터 V는 학습되어 인풋을 임베딩으로 압축하는데 사용한다.
FNN에서는 FM을 사전 학습하여 latent 벡터 V를 초기화하는 방법을 사용한다.
반면에 DeepFM에서는 전체 모델을 end-to-end로 학습하므로 사전학습을 하지는 않는다.
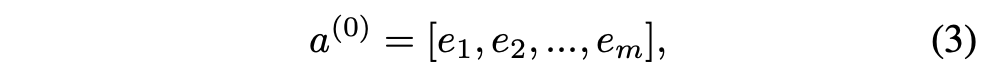
e_i: i번째 필드의 임베딩 벡터
m: 필드 개수
a_0: 임베딩 레이어의 출력 (=DNN의 입력)

a_(l): l번째 레이어의 출력
W_(l), b_(l): l번째 레이어의 가중치와 바이어스
기본적인 딥러닝 연산으로 l번째 레이어의 출력을 계산한다.
y_DNN은 기존 인풋을 매우 압축한 dense real-valued 벡터이다.
최종적으로 산출된 y_DNN은 CTR 예측을 위한 시그모이드 함수에 들어간다.
3.3. Deep + FM
최종적으로 Deep 컴포넌트와 FM 컴포넌트가 동일한 피처 임베딩을 공유한다.
그리고 이 방법은 두가지 중요한 이득을 가져온다.
첫번째, low-order와 high-order 상호작용을 'raw'에서 모두 모델링할 수 있다.
두번째, Wide & Deep 에서 요구하는 전문가 수준의 피처 엔지니어링이 필요하지 않다.
4. 기존 모델들과의 비교

4.1. FNN
Fig 5의 왼쪽 아키텍처를 가지는 모델이다.
FM으로 초기화를 한 뒤 FNN에 입력하는 모델이다.
FM에 대한 사전학습이 필요한데 여기에 2가지 한계점이 있다.
첫번째, 임베딩 파라미터가 FM에 의해 과도하게 영향을 받는다.
두번째, 사전학습 스테이지가 추가되어 학습이 비효율적이다.
오직 high-order 상호작용만 모델링할 수 있다.
(DeepFM: 사전학습 불필요, low-order + high-order 모델링)
4.2. PNN
Fig 5의 가운데 아키텍처를 가지는 모델이다.
임베딩 레이어와 첫번째 히든 레이어 사이에 프로덕트 레이어가 추가된 모델이다.
프로덕트 레이어는 3개의 변형된 프로덕트 연산을 포함한다.
(여기서 프로덕트는 내적의 영어인 이너 프로덕트에서 프로덕트를 의미)
IPNN: 벡터 내적을 기반으로 하는 연산
OPNN: 벡터 외적을 기반으로 하는 연산
PNN*: 내적과 외적을 모두 활용하는 연산
PNN은 연산의 효율성을 높이기 위해서 approximation (근사) 기법을 사용한다.
내적의 경우 일부 뉴런의 연산은 생략하여 계산량을 줄인다.
외적의 경우 m x k 차원을 k 차원으로 줄이는 방법을 사용한다.
저자들은 PNN의 외적이 신뢰성이 낮고 불안정한 결과를 초래한다고 주장한다.
(DeepFM: 오직 마지막에만 프로덕트 레이어를 사용)
4.3. Wide & Deep
Fig 5의 오른쪽 아키텍처를 가지는 모델이다.
low-order와 high-order 상호작용을 동시에 모델링할 수 있다.
하지만 Wide 파트를 위해 별도의 전문적인 피처 엔지니어링이 필요하다.
(DeepFM: 별도의 피처 엔지니어링 불필요)
4.4. Wide & Deep + LR
Wide 파트의 계산을 로지스틱 회귀 (LR)로 대체한 모델이다.
이 모델은 DeepFM과 매우 유사하다.
하지만 DeepFM은 Deep과 FM이 동일한 피처 임베딩을 공유한다.
이 공유 때문에 DeepFM은 임베딩 쪽에도 역전파가 도달한다.
이 모델은 이런 임베딩 공유가 없다.
따라서 DeepFM이 더 정교하게 학습할 수 있다.

기존 모델과의 차이점을 정리한 테이블이다.
결과 분석
1. Experiments
1.1. Datasets
[Criteo]
CTR 예측 글로벌 벤치마크 데이터셋
450만 개의 유저-아이템 쌍
39개의 피처 (13 연속형, 26 카테고리컬)
90% 학습, 10% 테스트
[Company*]
실제 산업 현장에서도 효과적인지 확인 (앱스토어 로그 데이터)
1억 개의 유저-아이템 쌍
23개의 피처 (7 연속형, 16 카테고리컬)
7 영업일 학습, 1 영업일 테스트
Metrics: AUC, Logloss
파라미터: dropout 0.5, dim [400, 400, 400], Adam, ReLU
2. Performance Evaluation
2.1. Efficiency

CPU와 GPU에서 학습 시간을 비교한 그래프이다.
IPNN과 PNN*는 매우 비효율적이다.
DeepFM은 가장 효율적인 모델로 나타났다.
2.2. Effectiveness

Wide & Deep의 경우 LR과 FM을 모두 시도하여 따로 기록하였다.
기본 LR이 가장 낮은 성능을 보인다.
따라서 피처 간의 상호작용이 중요함을 알 수 있다.
low-order 상호작용만 학습하는 FM 모델,
high-order 상호작용만 학습하는 FNN, IPNN, OPNN, PNN* 모델,
low와 high를 모두 학습하는 Wide & Deep 모델,
모든 모델보다 DeepFM이 더 좋은 성능을 보인다.
Wide & Deep에 LR까지 적용하더라도 DeepFM이 더 좋은 성능을 보인다.
2.3. Hyper-Parameter Study

relu와 tanh가 sigmoid보다 더 좋은 성능을 보인다.

Dropout은 0.6~0.9 구간에서 좋은 성능을 보인다.
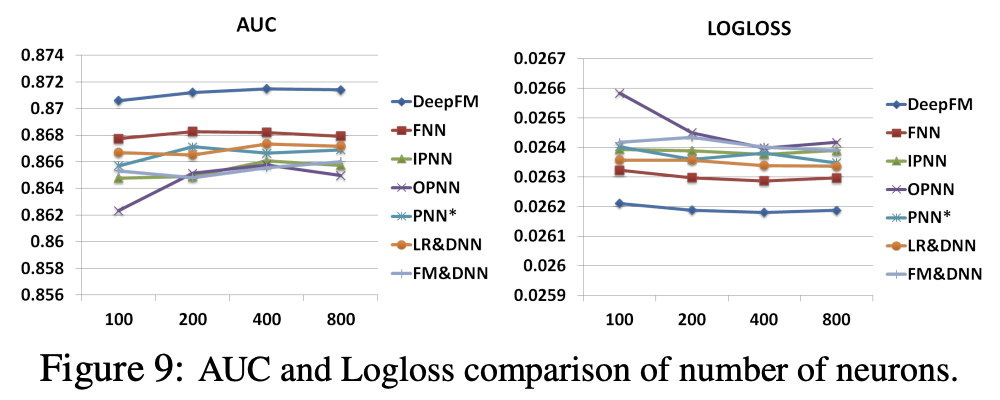
임베딩 레이어의 차원은 200~400 구간에서 좋은 성능을 보인다.
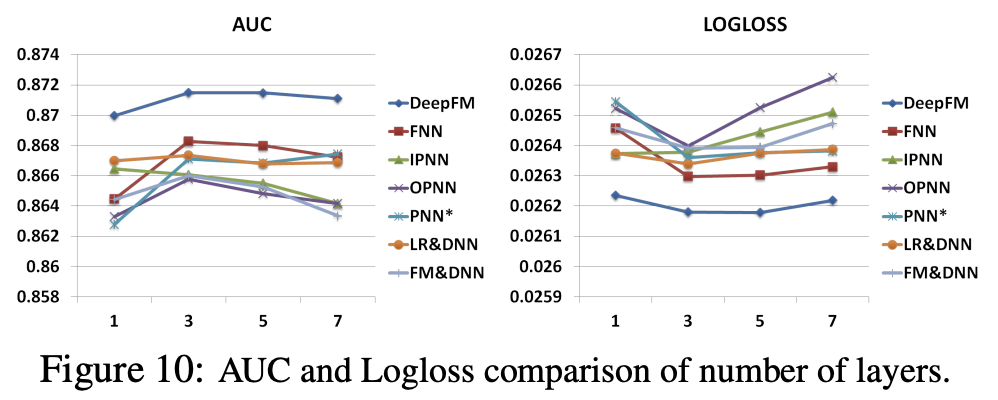
레이어 수는 3~4개가 가장 좋은 성능을 보인다.

아키텍처의 모양은 constant(200-200-200)에서 가장 좋은 성능을 보인다.
코드 및 구현
오피셜 코드 없음.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from time import time
class DeepFM(nn.Module):
"""
A DeepFM network with RMSE loss for rates prediction problem.
There are two parts in the architecture of this network: fm part for low
order interactions of features and deep part for higher order. In this
network, we use bachnorm and dropout technology for all hidden layers,
and "Adam" method for optimazation.
You may find more details in this paper:
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction,
Huifeng Guo , Ruiming Tang, Yunming Yey, Zhenguo Li, Xiuqiang He.
"""
def __init__(self, feature_sizes, embedding_size=4,
hidden_dims=[32, 32], num_classes=1, dropout=[0.5, 0.5],
use_cuda=True, verbose=False):
"""
Initialize a new network
Inputs:
- feature_size: A list of integer giving the size of features for each field.
- embedding_size: An integer giving size of feature embedding.
- hidden_dims: A list of integer giving the size of each hidden layer.
- num_classes: An integer giving the number of classes to predict. For example,
someone may rate 1,2,3,4 or 5 stars to a film.
- batch_size: An integer giving size of instances used in each interation.
- use_cuda: Bool, Using cuda or not
- verbose: Bool
"""
super().__init__()
self.field_size = len(feature_sizes)
self.feature_sizes = feature_sizes
self.embedding_size = embedding_size
self.hidden_dims = hidden_dims
self.num_classes = num_classes
self.dtype = torch.long
self.bias = torch.nn.Parameter(torch.randn(1))
"""
check if use cuda
"""
if use_cuda and torch.cuda.is_available():
self.device = torch.device('cuda')
else:
self.device = torch.device('cpu')
"""
init fm part
"""
self.fm_first_order_embeddings = nn.ModuleList(
[nn.Embedding(feature_size, 1) for feature_size in self.feature_sizes])
self.fm_second_order_embeddings = nn.ModuleList(
[nn.Embedding(feature_size, self.embedding_size) for feature_size in self.feature_sizes])
"""
init deep part
"""
all_dims = [self.field_size * self.embedding_size] + \
self.hidden_dims + [self.num_classes]
for i in range(1, len(hidden_dims) + 1):
setattr(self, 'linear_'+str(i),
nn.Linear(all_dims[i-1], all_dims[i]))
# nn.init.kaiming_normal_(self.fc1.weight)
setattr(self, 'batchNorm_' + str(i),
nn.BatchNorm1d(all_dims[i]))
setattr(self, 'dropout_'+str(i),
nn.Dropout(dropout[i-1]))
def forward(self, Xi, Xv):
"""
Forward process of network.
Inputs:
- Xi: A tensor of input's index, shape of (N, field_size, 1)
- Xv: A tensor of input's value, shape of (N, field_size, 1)
"""
"""
fm part
"""
fm_first_order_emb_arr = [(torch.sum(emb(Xi[:, i, :]), 1).t() * Xv[:, i]).t() for i, emb in enumerate(self.fm_first_order_embeddings)]
fm_first_order = torch.cat(fm_first_order_emb_arr, 1)
fm_second_order_emb_arr = [(torch.sum(emb(Xi[:, i, :]), 1).t() * Xv[:, i]).t() for i, emb in enumerate(self.fm_second_order_embeddings)]
fm_sum_second_order_emb = sum(fm_second_order_emb_arr)
fm_sum_second_order_emb_square = fm_sum_second_order_emb * \
fm_sum_second_order_emb # (x+y)^2
fm_second_order_emb_square = [
item*item for item in fm_second_order_emb_arr]
fm_second_order_emb_square_sum = sum(
fm_second_order_emb_square) # x^2+y^2
fm_second_order = (fm_sum_second_order_emb_square -
fm_second_order_emb_square_sum) * 0.5
"""
deep part
"""
deep_emb = torch.cat(fm_second_order_emb_arr, 1)
deep_out = deep_emb
for i in range(1, len(self.hidden_dims) + 1):
deep_out = getattr(self, 'linear_' + str(i))(deep_out)
deep_out = getattr(self, 'batchNorm_' + str(i))(deep_out)
deep_out = getattr(self, 'dropout_' + str(i))(deep_out)
"""
sum
"""
total_sum = torch.sum(fm_first_order, 1) + \
torch.sum(fm_second_order, 1) + torch.sum(deep_out, 1) + self.bias
return total_sum
def fit(self, loader_train, loader_val, optimizer, epochs=100, verbose=False, print_every=100):
"""
Training a model and valid accuracy.
Inputs:
- loader_train: I
- loader_val: .
- optimizer: Abstraction of optimizer used in training process, e.g., "torch.optim.Adam()""torch.optim.SGD()".
- epochs: Integer, number of epochs.
- verbose: Bool, if print.
- print_every: Integer, print after every number of iterations.
"""
"""
load input data
"""
model = self.train().to(device=self.device)
criterion = F.binary_cross_entropy_with_logits
for _ in range(epochs):
for t, (xi, xv, y) in enumerate(loader_train):
xi = xi.to(device=self.device, dtype=self.dtype)
xv = xv.to(device=self.device, dtype=torch.float)
y = y.to(device=self.device, dtype=torch.float)
total = model(xi, xv)
loss = criterion(total, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if verbose and t % print_every == 0:
print('Iteration %d, loss = %.4f' % (t, loss.item()))
self.check_accuracy(loader_val, model)
print()
def check_accuracy(self, loader, model):
if loader.dataset.train:
print('Checking accuracy on validation set')
else:
print('Checking accuracy on test set')
num_correct = 0
num_samples = 0
model.eval() # set model to evaluation mode
with torch.no_grad():
for xi, xv, y in loader:
xi = xi.to(device=self.device, dtype=self.dtype) # move to device, e.g. GPU
xv = xv.to(device=self.device, dtype=torch.float)
y = y.to(device=self.device, dtype=torch.bool)
total = model(xi, xv)
preds = (F.sigmoid(total) > 0.5)
num_correct += (preds == y).sum()
num_samples += preds.size(0)
acc = float(num_correct) / num_samples
print('Got %d / %d correct (%.2f%%)' % (num_correct, num_samples, 100 * acc))
'논문리뷰' 카테고리의 다른 글
| [논문 리뷰] NGCF 요약, 코드, 구현 (0) | 2025.12.18 |
|---|---|
| [논문 리뷰] CLIP 요약, 코드, 구현 (0) | 2025.12.15 |
| [논문 리뷰] GCN 요약, 코드, 구현 (6) | 2025.08.03 |
| [논문 리뷰] LLaMA v1 요약, 코드, 구현 (0) | 2025.03.31 |
| [논문 리뷰] data2vec 요약, 코드, 구현 (3) | 2024.07.16 |



