논문을 상세히 번역하고 한단어씩 해석해주는 포스팅은 많다.
나는 논문을 누구나 알아듣도록 쉽고 간결하게 전달하고자 한다.
DINO
저자의 의도
self-supervised learning(SSL)이 ViT에 새로운 특성을 부여하는지에 대한 연구이다.
SSL + ViT 조합에 대하여 관찰해보자.
이러한 연구 결과를 구현하여 새로운 모델 DINO를 소개한다.
DINO(self-DIstillation with NO labels)
기존 문제점
ViT가 여전히 계산이 복잡하고, 많은 데이터를 요구하고, 자신만의 유니크한 특성이 없다.
프리트레이닝에서 지도학습이 ViT의 성공과 직접적으로 연관이 있는가?
NLP에서는 더 풍부한 학습을 위해 SSL을 사용하는데 비전에도 적용해보자.
self-supervised pre-training이 ViT의 특성에 미치는 영향을 연구해보자.
해결 아이디어
1. DINO overview
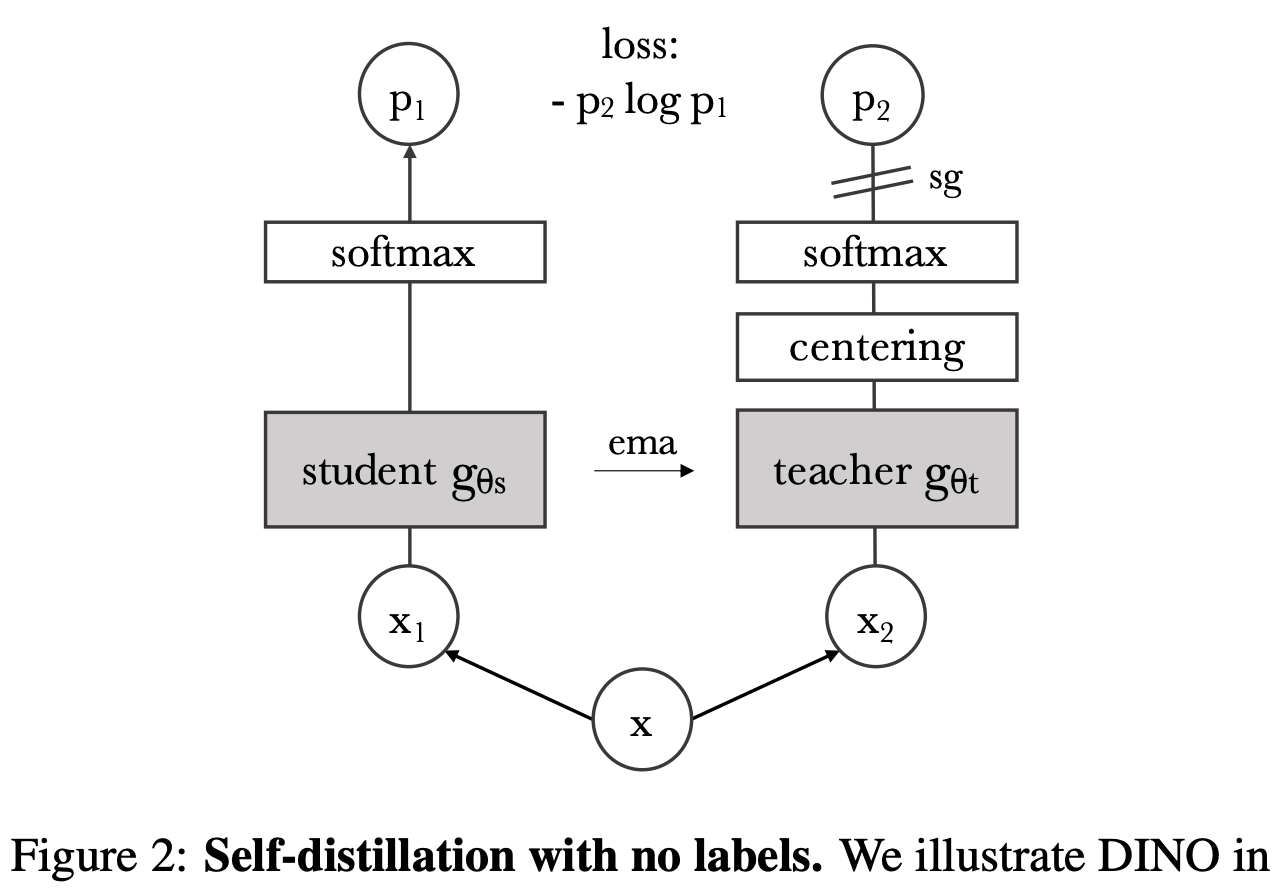
일단 전체적인 구조를 한번 살펴보고 가자.
teacher 네트워크(distillation)의 아웃풋을 label 없이(no label) 직접 예측한다.
이때 teacher는 MoCo의 메서드를 차용해 천천히 업데이트한다.
다른 모델들은 안정화를 위해 batch norm, contrastive loss 등을 썼다.
DINO는 centering과 sharpening만 해줘도 잘 학습되며 CE loss를 사용한다.
2. SSL with Knowledge Distillation
2-1. 개요
기존 SSL 방식과 비슷한 구조를 가진다.
하지만 여기에 knowledge distillation 방식을 적용한다.
다시 그림을 보자. 프로세스를 살펴볼 것이다.
인풋 이미지에 대하여 서로 다른 2개의 랜덤 transformation을 한다.
각각 student 네트워크, teacher 네트워크에 넣는다.
두 네트워크는 같은 아키텍처를 가졌으나 파라미터 값은 다르다.
teacher 네트워크의 아웃풋을 배치 평균을 사용해서 centering 해준다.
각 결과를 노멀라이제이션, softmax한다.
두 결과 간의 similarity를 CE loss로 계산한다.
teacher 네트워크는 파라미터를 고정하기 위해 stop gradient(sg) 한다.
teacehr 네트워크의 업데이트는 student 네트워크의 EMA를 사용해 진행한다.

이를 수도 코드로 도식화하면 Algo 1 이다.

여기서 네트워크는 g, 파라미터는 θ, s가 붙으면 student, t가 붙으면 teacher 이다.
인풋 이미지 x가 주어졌을 때, 확률분포는 P 이다.
student의 확률분포 P의 수식은 Eq 1과 같다.
τ는 temperature 파라미터로, 아웃풋의 샤프니스를 조절한다.
student 모델은 P 간의 차이가 작아지도록 학습된다.
인풋 이미지의 서로 다른 2개의 랜덤 transformation에 대해 알아보자.
멀티크롭 전략을 사용해서 이미지에 서로 다른 distortion, crop을 진행한다.
teacher로 가는 이미지는 큰 이미지 2개다.
원본 이미지의 절반 이상을 커버할 정도이며, 자른 이미지를 224로 리사이즈 한 것이다.
student로 가는 이미지는 작은 이미지 n개다.
원본 이미지의 절반 이하를 커버할 정도이며, 자른 이미지를 96으로 리사이즈 한 것이다.
2-2. Teacher network
원래 knowledge distillation은 teacher 모델의 능력이 student로 전사된다.
하지만 DINO에서는 사실상 teacher 모델이 없는 것이라 볼 수 있다. (EMA를 사용하였기 때문)
teacher는 곧 student 모델의 과거 이터레이션 이다.
MoCo 논문에서 나온 메서드를 적용한 것인데 매우 효과적이다.
EMA를 간단히 설명하면 teacher의 파라미터는 매우 천천히 업데이트 된다.
0.4% 정도만 업데이트 하다가 점점 0%까지 cosine하게 줄인다.
원래 MoCo에서는 큐 딕셔너리 전략과 함께 사용된다.
하지만 DINO에는 큐도 없고 contrastive loss도 없다.
딕셔너리 대신 self-training에 사용되는 mean teacher라 볼 수 있다.
그리고 EMA가 Polyak-Ruppert averaging과 닮았다.
그래서 두개를 앙상블 해봤더니 또 더 좋은 결과가 나왔다.
2-3. Network architecture
ViT와 같은 backbone f와 projection head h가 합쳐진 구성이다.
downstream task에서는 f만 가져다가 사용한다.
h는 3 layer 짜리 dim=2048의 MLP 이다.
기존 ViT와 다르게 batch normalization을 사용하지 않았다.
2-4. Avoiding collapse
SSL을 할 때는 collapse 즉, 붕괴를 방지 해야한다.
그 방법으로 contrastive loss, predictor, batch normalization 등이 있다.
저자들은 multiple normalization만 시도 했는데도 teacher 모델이 안정적이었다.
앞서 말한 centering과 sharpening과 같이 사용해도 문제 없었다.
centering은 한 dim(=feature)가 모델을 지배하는 것을 방지해준다.
하지만 이는 곧 붕괴를 야기하는 방법이기도 하다.
이때 sharpening이 centering과 정반대 역할을 한다.
두개의 밸런스를 잘 맞추면 붕괴를 방지하면서도 teacher를 학습할 수 있다.
결과 분석
1. Implementation and evaluation protocols
ViT: DeiT 사용, 패치 사이즈는 8 or 16, layer norm 사용.
Implementation details: label 없이 ImageNet 학습, adamW, batch 1024, warm up, cosine decay.
2. Main results
2-1. Comparing on ImageNet
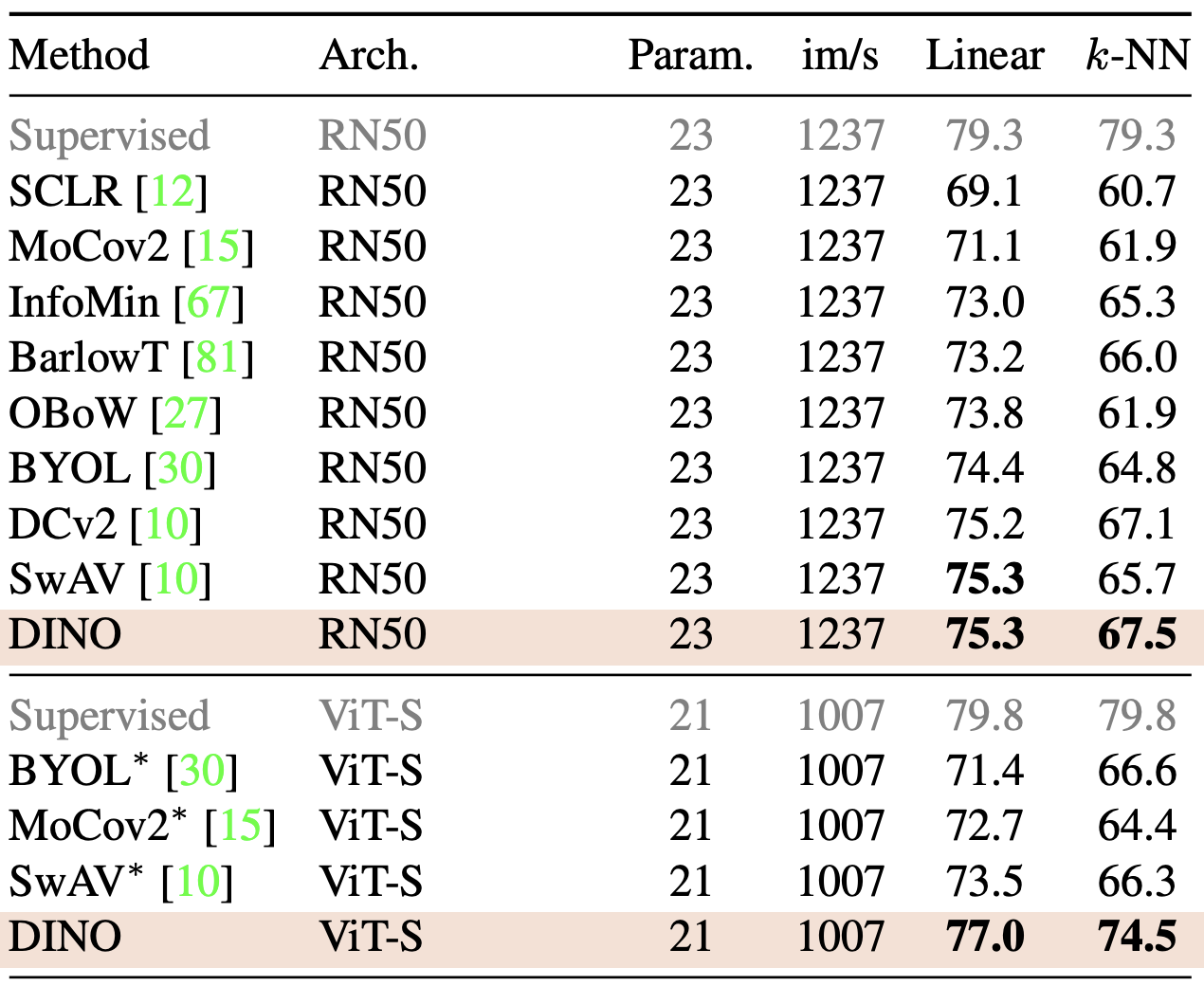
ViT-S 기준 BYOL, MoCo v2, SwAV보다 더 좋은 성능이다.
k-NN이 linear와 비슷한 수준으로 매우 높은 성능이다.
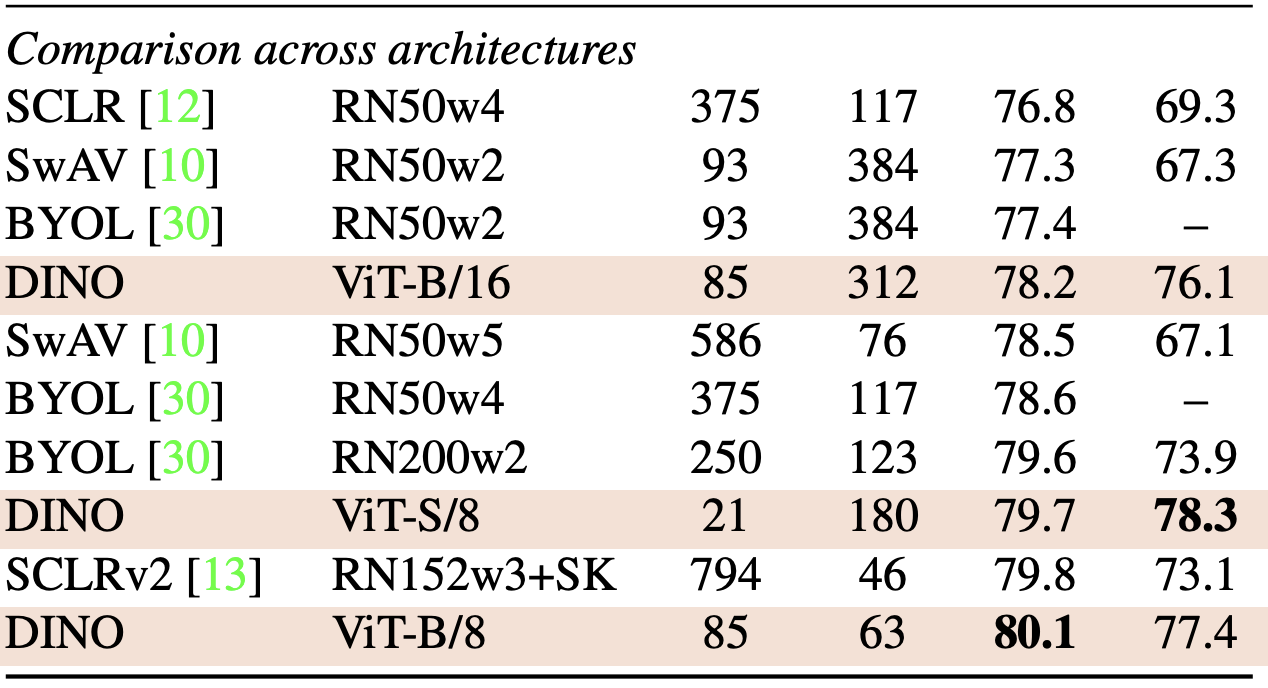
패치 사이즈 8을 사용한 경우 모든 아키텍처의 모델 중에서 가장 성능이 좋다.
물론 패치 사이즈 16에 비해서 쓰루풋이 크게 줄어든다.
2-2. Properties of ViT trained with SSL
Discovering the semantic layout of scenes

그림을 보면 self-attention maps가 segmentation 정보를 포함하고 있다.
어텐션 맵에서 바로 마스크를 추출하고 특성을 측정해보자.

색깔 별로 서로 다른 헤드를 뜻한다.
서로 다른 헤드들은 각각 다른 semantic region을 집중한다.

반면에 Fig 4를 보면,
supervised ViT는 클래스 토큰의 클러스터를 양적으로 질적으로 좋게 형성하지 못한다.
2. Ablation study
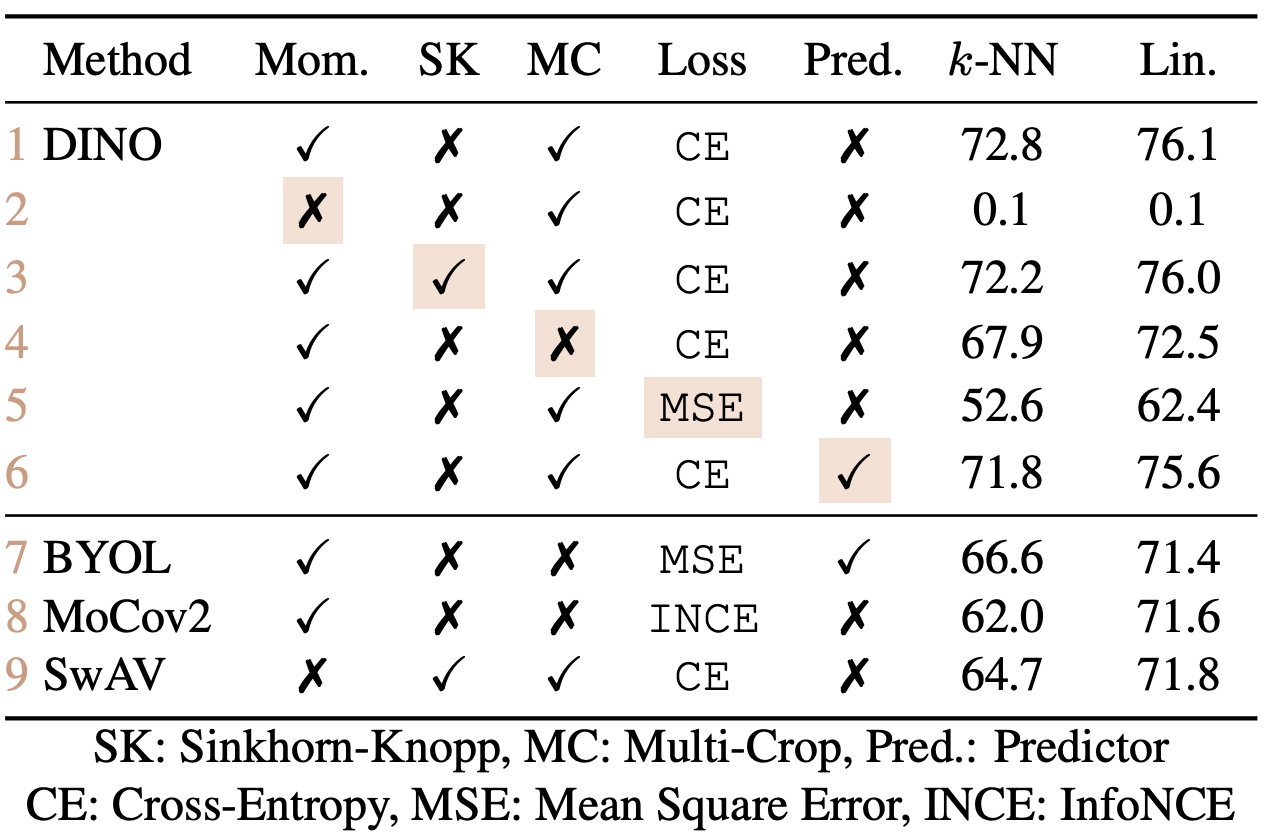
메서드를 바꿔가며 평가해봤다.
모든 메서드가 유효하다.

패치 사이즈를 줄이는 것이 DeiT의 경우보다는 쓰루풋 trade off가 덜하다.
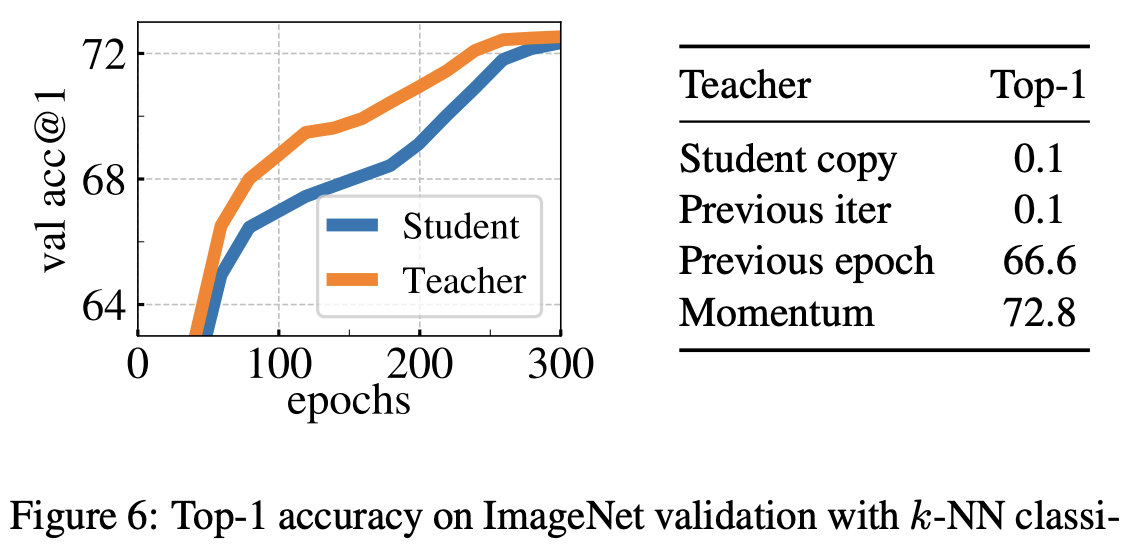
teacher 네트워크를 다양하게 바꿔봤는데 모멘텀 케이스가 가장 좋았다.
왼쪽 그림은 학습이 진행되는 동안 acc를 뽑은 것이다.
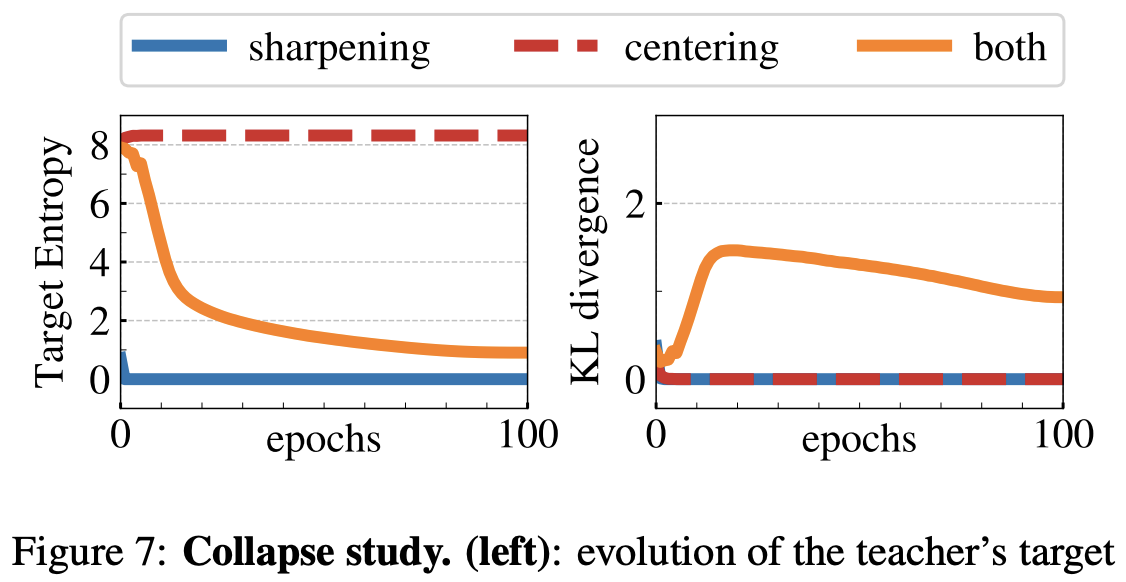
centering과 sharpening을 동시에 사용했을 경우 붕괴가 일어나지 않는다.
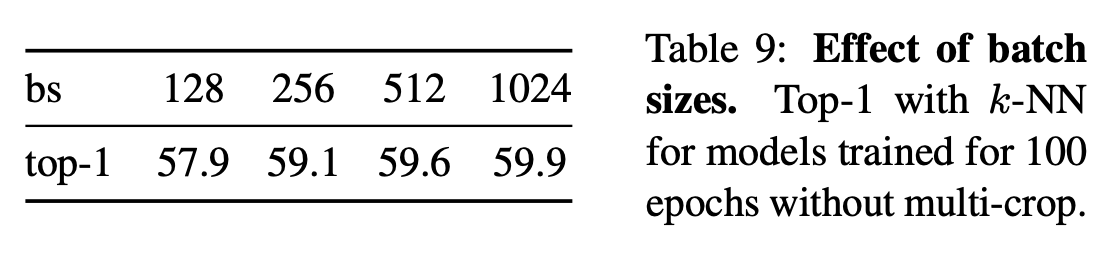
작은 배치를 사용할 경우 acc가 줄어든다......ㅇㅁㅇ....(킹받네...)
코드 구현
새로 코딩한 것은 크게 없다.
기존에 있는 메서드들과 모델으로 칵테일을 잘 말았다.
'논문리뷰' 카테고리의 다른 글
| [논문 리뷰] data2vec 요약, 코드, 구현 (3) | 2024.07.16 |
|---|---|
| [논문 리뷰] iBOT 요약, 코드, 구현 (0) | 2024.07.11 |
| [논문 리뷰] CAE(Context Autoencoder) 요약, 코드, 구현 (0) | 2024.06.25 |
| [논문 리뷰] LLaVA-UHD 요약, 코드, 구현 (1) | 2024.06.19 |
| [논문 리뷰] MambaOut 요약, 코드, 구현 (1) | 2024.06.11 |



