논문을 상세히 번역하고 한단어씩 해석해주는 포스팅은 많다.
나는 논문을 누구나 알아듣도록 쉽고 간결하게 전달하고자 한다.
CAE
I-JEPA에 레퍼런스로 나와서 읽어봤다.
representation space에서 학습하는 개념 측면에서 I-JEPA와 매우 유사하다.
근데 전체적으로 용어가 왔다갔다하고 문장도 지나치게 길고 읽기 좀 힘들었다......
저자의 의도
새로운 masked image modeling(MIM)인 CAE를 제시한다.
representation space에서 인코더를 학습해보자.
task: (masked representation을 예측 -> masked 패치를 reconstruction)
아키텍처: (인코더 -> regressor -> 디코더)
이 설계 구조를 통해 인코더를 reconstruction에서 완전히 분리하고자 한다.
기존 문제점
MIM은 이미지의 몇몇 패치를 가리고 가린 부분을 예측하며 인코더를 학습시킨다.
기존의 전형적인 MIM 모델들은 2가지 task가 섞여있다.
(인코더가 representation을 학습) + (masked 패치를 reconstruction)
최근 연구인 MAE는 인코더-디코더 구조를 최적화하여 두 task를 완전히 분리했다.
하지만 여전히 representation quality가 한계가 있다.
해결 아이디어
1. CAE

인코더-regressor-디코더 구조의 CAE를 제시한다.
인코더는 오직 visible 패치만 받아 representation을 학습한다.
regressor는 masked 패치의 representation을 예측만 한다.
디코더는 regressor의 결과를 받아 masked 패치를 reconstuction 한다.
representation space에서 예측하는 것의 장점은 다음과 같다.
visible space가 아니라 같은 space에서 예측하기 때문에 더 그럴듯한 semantic 추측이 가능하다.
따라서 더 방대한 범위의 semantics를 인코딩할 것이라고 예상했다.
인코딩 작업과 이미지 완성 작업이 분리되었기 때문에,
인코더는 정확히 인코딩 작업만 집중해서 학습할 수 있다.
representation끼리 매핑하는 작업은 regressor가 단독으로 한다.
2. 기존 모델과 비교
그림 가운데 부분은 MAE의 아키텍처를 표현한 것이다.
MAE는 디코더가 (masked 패치 예측)과 (reconstruction) 두 task를 한다.
저자들이 생각하기에 디코더는 reconstruction만 해야한다.
masked 패치 representation 예측을 하는 명시적인 모듈이 없다.
쉽게 설명하면 디코더가 representation, pixel 두 space 작업을 모두 한다.
그림 오른쪽 부분은 data2vec과 iBOT의 아키텍처를 표현한 것이다.
마찬가지로 masked 패치 representation 예측을 하는 명시적인 모듈이 없다.
그리고 타겟 representation이 전체 패치(visible+masked)를 다 보고 추출되는 구조다.
(CAE는 visible 패치만 인코딩, masked 패치만 인코딩, 따로 하는 방식)
3. Architecture
전체 이미지를 패치로 만든다.
인코더에 한번에 입력하는 것은 아니고 각각 입력한다.
패치를 2세트로 나눈다. (visible 패치 X_v, masked 패치 X_m)
인코더 : visible 패치만 인코더로 넣는다.
regressor : masked 패치의 representation 예측
(인코더가 masked 패치만 인코딩한 representation과 정렬)
디코더 : masked 패치 reconstruction
3-1. 인코더
위 그림에서 (a)의 부분이다.
인코더 F는 visible 패치 X_v를 인풋으로 받는다.
visible 패치에 포지션 임베딩 P_v를 더한 뒤 인코더 블럭에 들어간다.
아웃풋은 latent representation Z_v이다.
MAE처럼 회색 처리된 masked 패치가 같이 들어가지 않는다.
3-2. Regressor
위 그림에서 (b)의 앞부분이다.
regressor H는 인코더의 아웃풋 Z_v를 인풋으로 받는다.
masked 패치의 representation Z_m을 예측한다.
Q_m : initial queries, 어떤 패치가 masked 인지에 대한 정보
Q_m을 참고해서 representation들을 정렬한다.
(저자는 모든 모듈이 명시적이고 한가지 task만 한다고 했는데...
이 regressor가 처리하는 일이 많고 복잡하다.
하나도 간단하지 않다. 과대광고 멈춰주길 바란다...ㅇㅁㅇ)
3-3. 디코더
위 그림에서 (b)의 뒷부분이다.
디코더 G는 regressor의 아웃풋 Z_m을 인풋으로 받는다.
타겟 Y_m을 reconstruction 한다.
3-4. Objective function
[마스킹]
마스킹은 BEiT처럼 랜덤하게 아무 패치나 무작위로 한다.
마스킹 되는 양은 절반이다. (패치 196개 중 98개)
[align target]
타겟 Z_m을 구하기 위해 masked 패치 X_m만 인코더에 따로 넣는다.
이 인코더는 visible 패치를 처리하는 인코더와 동일한 인코더 이다.
[reconstruction target]
타겟 Y_m은 픽셀 수준인줄 알았는데 그건 또 아니다.
d-VAE로 reconstruction 타겟 Y_m을 만든다.
이건 패치를 각각 벡터 space로 변환한 것이다. (pixel값 아님)
[Loss]
Loss function은 reconstruction loss(l_y)와 align loss(l_z)로 구성된다.
Eq 1으로 나타낼 수 있으며, 실험결과 람다는 2가 가장 좋았다.
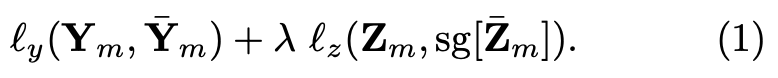
결과 분석
1. Training details
Pre-training: AdamW, epochs 300/800/1600, batch size 2048, learning rate 1.5e-03, cosine decay, warm up
Linear probing: LARS, epochs 90, batch size 16384, learning rate 6.4, no decay, warm up
Fine-tuning: AdamW, epochs 100, batch size 4096, learning rate 8e-03, layer wise decay, warm up
Attentive-probing: (생략)
2. Evaluation
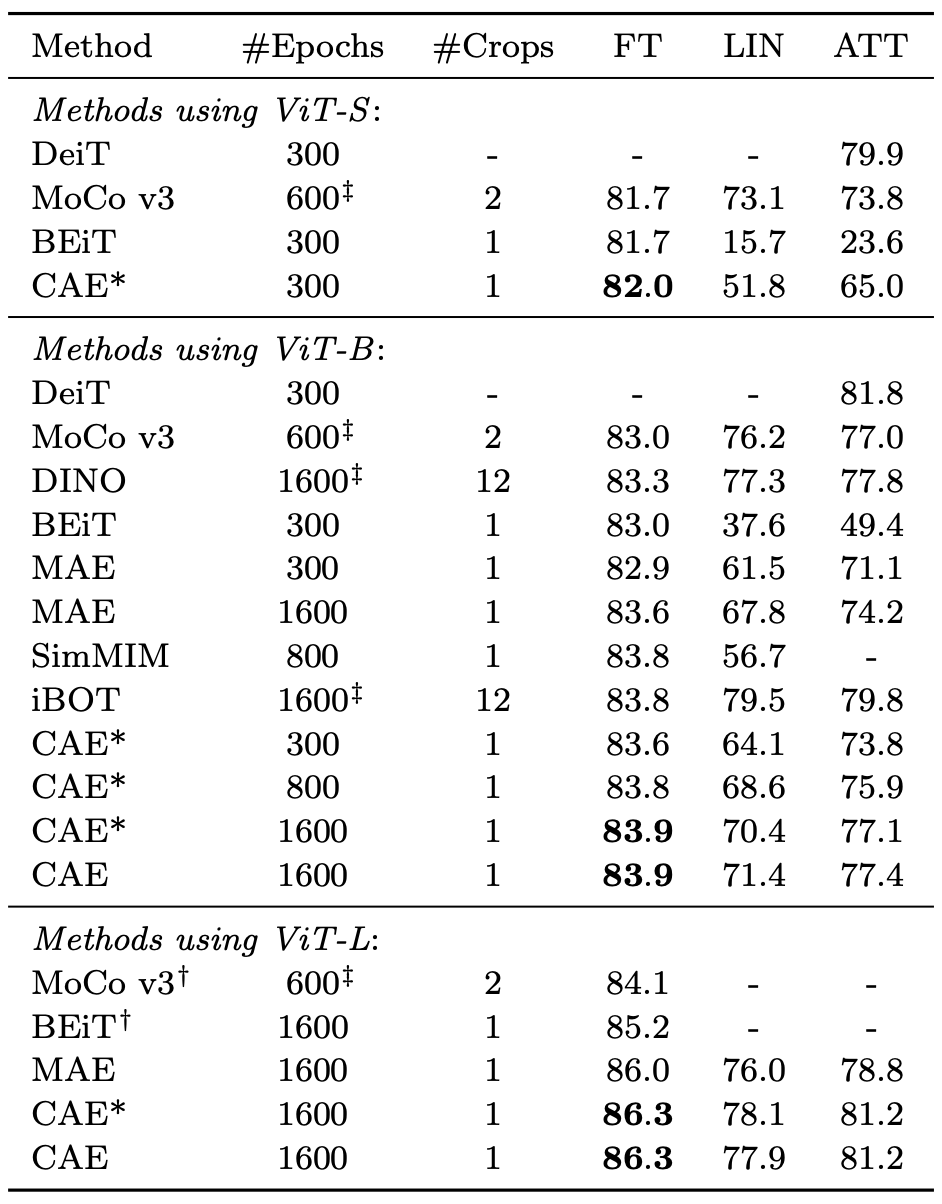
아스타(*)가 붙은 CAE는 d-VAE 대신 DALL-E를 토크나이저로 사용했다.
대부분의 모델이 있는 ViT-B를 기준으로 보자.
Linear probing은 contrastive 방식인 MoCo와 DINO가 매우 높다.
MIM 방식 보다 contrastive 방식이 높은 이유는 1000개 클래스에 대한 vocabulary를 형성하는데 집중하기 때문이다.
그래도 CAE가 MIM 방식 중에서 가장 높은 accuracy를 기록했다.
Attentive probing은 contrastive 방식과 견줄 정도로 CAE도 높다.
Fine-tuning의 경우 모든 모델 중에서 가장 높았다.
3. Downstream tasks
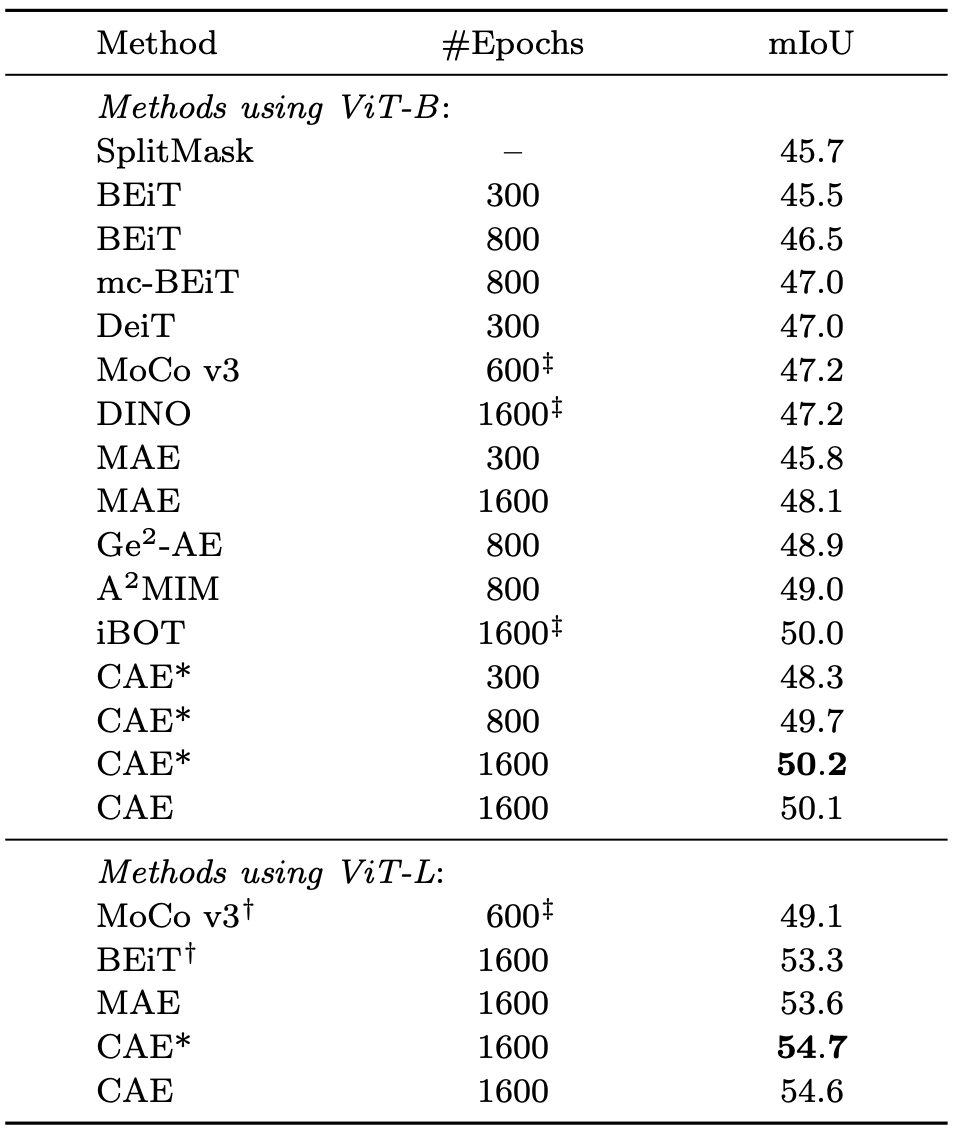
Semantic segmentation
ViT-B에서 모든 모델 중에서 가장 좋았다.
ViT-L도 모든 모델 중에서 가장 좋았다.
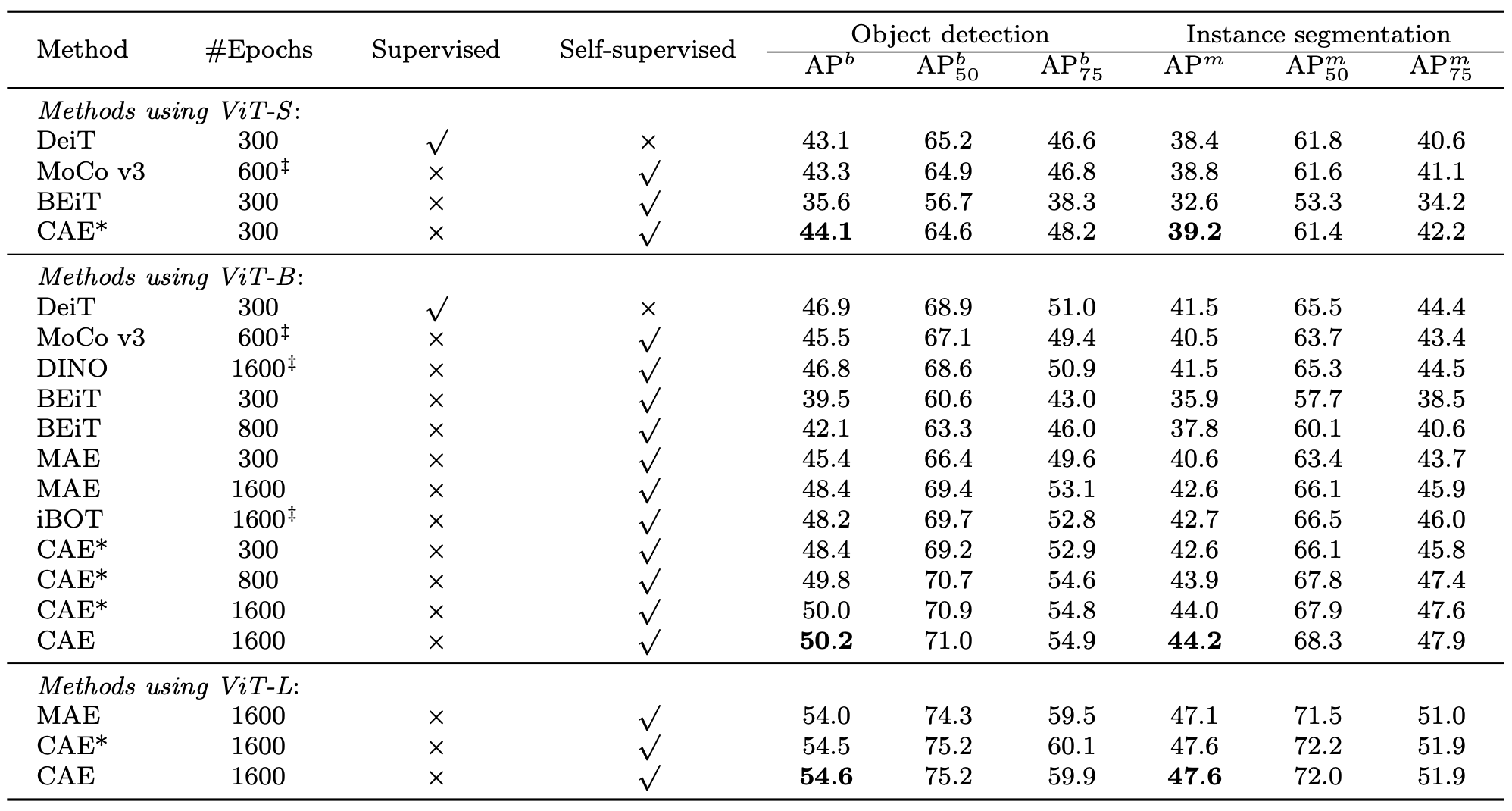
Object detection
ViT-B에서 모든 모델 중에서 가장 좋았다.
ViT-L도 모든 모델 중에서 가장 좋았다.
코드 구현
그 중에서 아키텍처 포워드 부분
'''
Input shape:
x: [bs, 3, 224, 224]
bool_masked_pos: [bs, num_patch * num_patch]
'''
def forward(self, x, bool_masked_pos):
batch_size = x.size(0)
'''
Encoder
Output shape:
[bs, num_visible + 1, C]
'''
x_unmasked = self.encoder(x, bool_masked_pos=bool_masked_pos)
# encoder to regresser projection
if self.encoder_to_regresser is not None:
x_unmasked = self.encoder_to_regresser(x_unmasked)
x_unmasked = self.encoder_to_regresser_norm(x_unmasked)
'''
Alignment branch
'''
if self.model_type == 'caev2':
latent_target = None
else:
with torch.no_grad():
latent_target = self.alignment_encoder(x, bool_masked_pos=(~bool_masked_pos))
latent_target = latent_target[:, 1:, :] # remove class token
if self.encoder_to_regresser is not None:
latent_target = self.encoder_to_regresser_norm(self.encoder_to_regresser(latent_target.detach()))
self.alignment_parameter_update()
'''
Latent contextual regressor
1. prepare masked, unmasked pos embed, and masked mebedding
'''
_, num_visible_plus1, dim = x_unmasked.shape
x_cls_token = x_unmasked[:, :1, :]
x_unmasked = x_unmasked[:, 1:, :] # remove class token
pos_embed = self.rd_pos_embed.expand(batch_size, self.num_patches+1, dim).cuda(x_unmasked.device)
pos_embed_masked = pos_embed[:,1:][bool_masked_pos].reshape(batch_size, -1, dim) # pos embed for masked patches
pos_embed_unmasked = pos_embed[:,1:][~bool_masked_pos].reshape(batch_size, -1, dim) # pos embed for unmasked patches
num_masked_patches = self.num_patches - (num_visible_plus1-1)
x_masked = self.mask_token.expand(batch_size, num_masked_patches, -1) # masked embedding
'''
2. regress masked latent via regresser
'''
x_masked_predict = self.regresser(x_masked, x_unmasked, pos_embed_masked, pos_embed_unmasked)
## preserve for alignment
if self.model_type != 'caev2':
latent_predict = x_masked_predict
'''
decoder for reconstruction
'''
if self.model_type == 'caev2':
logits, latent_predict = self.decoder(x_masked_predict, pos_embed_masked, x_cls_token=x_cls_token, x_unmasked=x_unmasked)
logits = logits / logits.norm(dim=-1, keepdim=True)
else:
logits = self.decoder(x_masked_predict, pos_embed_masked)
logits = logits.view(-1, logits.shape[2]) # flatten
return logits, latent_predict, latent_target
'논문리뷰' 카테고리의 다른 글
| [논문 리뷰] iBOT 요약, 코드, 구현 (0) | 2024.07.11 |
|---|---|
| [논문 리뷰] DINO 요약, 코드, 구현 (0) | 2024.07.11 |
| [논문 리뷰] LLaVA-UHD 요약, 코드, 구현 (1) | 2024.06.19 |
| [논문 리뷰] MambaOut 요약, 코드, 구현 (1) | 2024.06.11 |
| [논문 리뷰] MoCo v3 요약, 코드, 구현 (0) | 2024.06.04 |



