논문을 상세히 번역하고 한단어씩 해석해주는 포스팅은 많다.
나는 논문을 누구나 알아듣도록 쉽고 간결하게 전달하고자 한다.
I-JEPA
메타의 움직임이 심상치 않다.
V-JEPA가 오픈리뷰와 ICLR 논문 심사를 거치고 있는 중이다.
그런데 여기 CV의 대가 얀 르쿤 교수님이 참여하셨다.
얀 르쿤 교수님이 이 모델에 대한 자신감이 넘치신다.
언어 분야의 서비스 최강자 구글, MS가 NLP 기반모델을 완성시킨 것처럼,
비전 분야의 서비스 최강자 메타가 CV 기반모델 을 완성시킬까.
얀 르쿤 "사람처럼 추론하고 계획하는 AI 에이전트 개발 중"(기사 원문)
저자의 의도
semantic image representations를 hand-crafted 데이터 없이 학습시켜보자.
I-JEPA(Image based Joint Embedding Predictive Architecutre) 제시.
이미지 중에서 1개의 context block을 입력 받아 다른 여러개의 target block의 representations를 예측하자.
I-JEPA으로 얻는 이득은 다음 2가지다.
충분히 큰 스케일의 타겟 블럭. 즉 아웃풋 양이 많다.
충분히 공간적 분산 정보가 담긴 컨텍스트 블럭. 즉 인풋이 합리적이다.
기존 문제점
SSL(self-supervised learning)은 데이터를 구하기 좋다.
별다른 사람의 손을 거치지 않고 인풋이 그대로 label이 되기 때문이다.
SSL 프리트레이닝은 invariance-based 와 generative 2가지로 나뉜다.
2가지 개념을 먼저 간단히 이해하자.
[invariance-based methods]
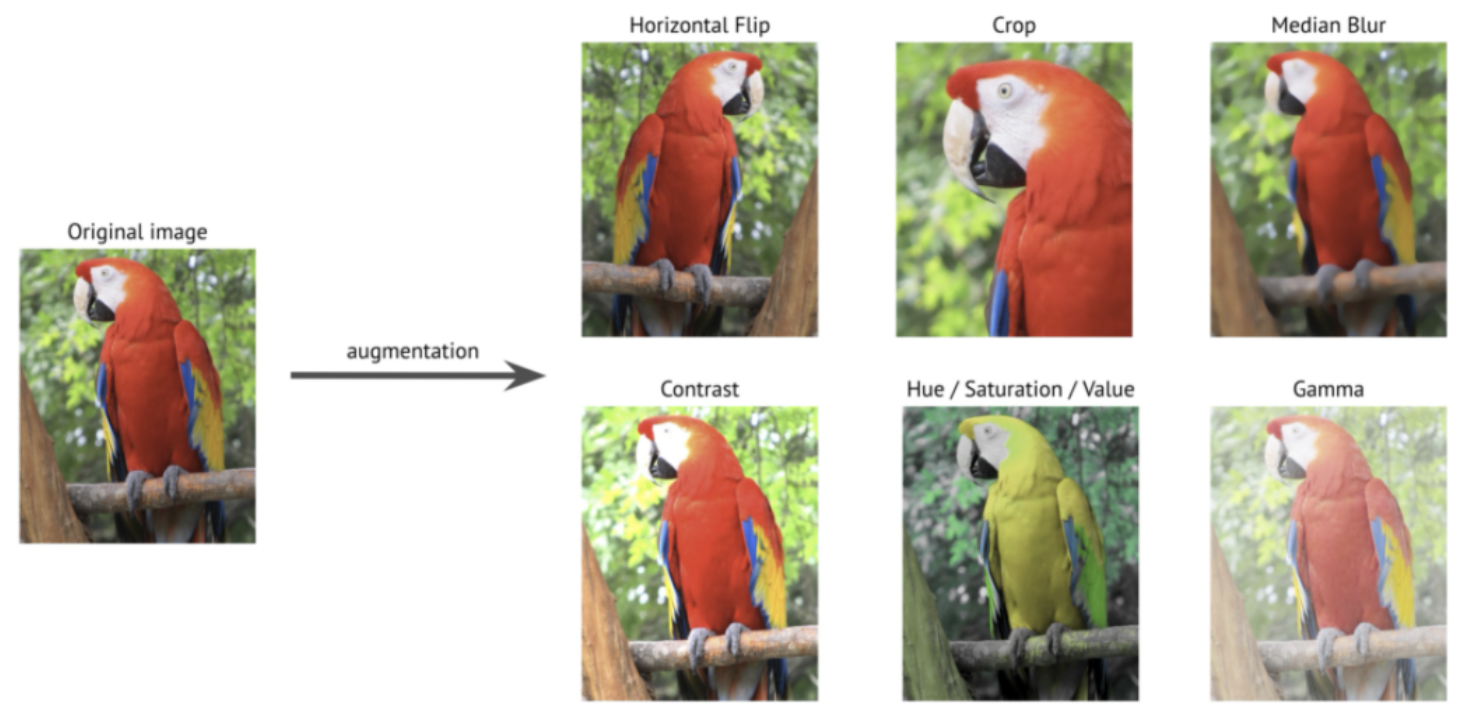
같은 이미지에 대하여 다르지만 유사한 관점에 대한 임베딩을 추출한다.
랜덤 스케일링, 랜덤 크로핑, 컬러 지터링 등이 있다.
원본 이미지에서 임베딩과 색깔을 약간 변형한 이미지에서 임베딩이 살짝 다를 것이다.
이를 이용하는 방법이다.
이 방법의 단점은 분명하다.
저 증강된 데이터의 알고리즘에 대해 강력하게 fit 시키는 것으로 강력한 바이어스를 야기한다.
강력한 바이어스가 생겼다는 것은 general 하지 않다는 것으로 보편적인 task를 수행할 수 없다.
fine-tuning이 필요하거나 다른 종류의 data distribution에서는 새로 프리트레이닝을 해야한다.
[generative methods]
[논문 리뷰] MAE(Masked Autoencoders) 요약, 코드, 구현
논문을 상세히 번역하고 한단어씩 해석해주는 포스팅은 많다. 나는 논문을 누구나 알아듣도록 쉽고 간결하게 전달하고자 한다. MAE(Masked Autoencoders) Masked Autoencoders Are Scalable Vision Learners HE, Kaiming,
davidlds.tistory.com
cognitive learning 이론은 생물학적 시스템을 모방한 매커니즘이다.
generative methods는 이 이론을 따르며, 생체 감각적인 반응을 예측하도록 한다.
사람이 학습하는 것과 유사하게 설계한다는 말이다.
사람은 이미지에서 일부 지워진 부분이 있으면 그 부분을 상상할 수 있다.
따라서 모델은 지우거나 손상된 일부분을 입력으로 받아 손상된 컨텐츠를 예측하며 학습한다. (=MAE)
이 방법의 단점은,
학습된 결과 representation이 전형적으로 lower semantic level이다.
색깔이나 선의 이어짐 등의 간단한 정보(낮은 수준의 의미들)로 유추할 수도 있다는 말이다.
따라서 linear probing으로 평가할 시 fine-tuning에 비해 퍼포먼스가 떨어진다.
linear probing은 아래에서 다시 설명해주겠다.
해결 아이디어
1. Architecture overview

이 모델의 아키텍처는 매우 간단하고 명확하다.
추상적인 representation space에서 지워진 정보를 예측한다.
아주 간단한 아이디어 같지만 쉽게 떠올릴 수 없고 구현하기는 쉬우면서 매우 효율적이다.
그냥... 천재적인 아이디어다. 역시 메타고 역시 얀 르쿤 교수님이다.
프로세스는 MAE와 유사하다.
컨텍스트 블럭 1개가 인풋으로 주어진다.
모델은 다양한 타겟 블럭의 representation을 예측한다.
이 작업은 1개의 같은 이미지 내에서 이루어진다. (SSL 이다.)
중요한 것은 타켓 블럭의 픽셀이 아니라 representation을 예측하는 것이다.
이 target representation은 이미 학습된 타겟 인코더가 계산한 값이다.
다시말해 타겟의 픽셀을 인코더에 넣어서 representation을 추출한 값이다.
기존의 generative methods (ex. MAE)는 pixel space에서 예측을 했다면,
I-JEPA는 추상적인 space에서 예측을 한다.
여기서 장점은 크게 2가지로 설명할 수 있다.
불필요한 픽셀 레벨의 디테일을 굳이 예측할 필요 없다.
고도로 압축된 의미론적 feature만 학습할 수 있다.
멀티 블럭 마스킹 학습 전략도 중요하다.
타겟 블럭을 1개가 아니라 4개로 두는 전략이다. (그림은 3개로만 표현함)
이러면 SSL을 하면서 더욱 많은 양의 타겟 블럭을 뽑아낼 수 있다.
확률적으로 매번 iteration에서 유사하지만 다른 4번의 학습을 할 수 있다.
2. Background (배경지식)

먼저 EBM에 대하여 알아보고 위 그림을 보겠다.
2-1. EBM(Energy-Based Models)
I-JEPA는 EBM에서 아이디어를 차용했다.
EBM은 호환되지 않는 인풋 사이에는 높은 에너지를 할당하고,
호환되는 인풋 사이에는 낮은 에너지를 할당한다.
기존의 SSL 방식들을 이 프레임워크로 변형한다.
위에서 설명한 2가지 methods를 EBM화 한다.
2-2. JEA(Joint-Embedding Architectures)
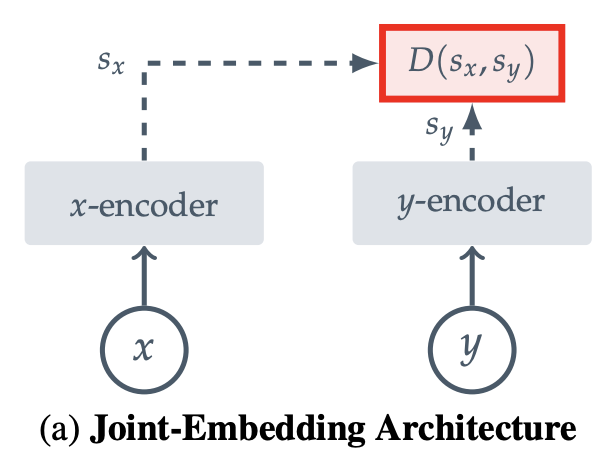
Figure 2의 왼쪽 그림이다.
JEA으로 invariance-based methods를 EBM화 한다.
이미지 기반의 프리트레이닝은 보통 호환되는 x, y 쌍을 가지고 있다.
단지 인풋 x에 랜덤한 hand-craft 증강을 했을 뿐이다.
이걸 그림으로 나타내면 왼쪽 그림처럼 된다.
JEA의 차원 붕괴 관점의 문제는 에너지 면이 평평하다는 것이다.
2-3. GA(Generative Architectures)

Figure 2의 가운데 그림이다.
GA로 generative methods를 EBM화 한다.
얘도 마찬가지로 호환되는 x, y 쌍을 가지고 있다.
인풋 x에서 증강없이 다이렉트로 y를 reconstruction 한다.
디코더에서 추가적인 정보 z를 reconstruction에 활용한다.
MAE로 예를 들면
y를 복사하고 일부를 마스킹한 x를 인풋하며,
어떤 패치를 가렸는지에 대한 위치 정보와 그 마스크 자체를 디코더에서 z로 받는다.
GA는 차원 붕괴 관점에서 문제가 있지 않다.
2-4. JEPA(Joint-Embedding Predictive Architectures)
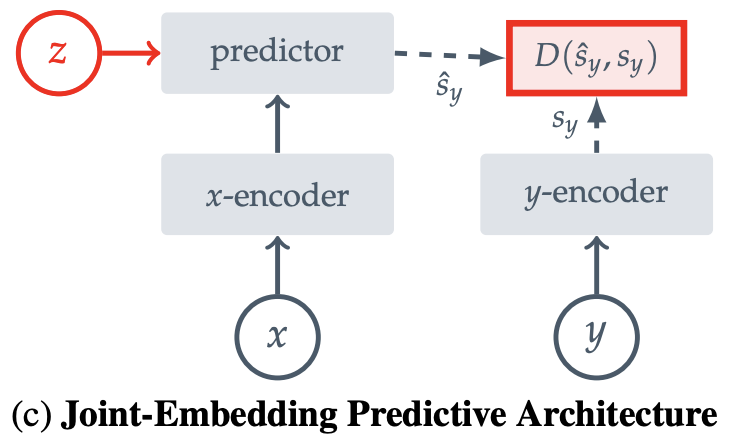
Figure 2의 오른쪽 그림이다.
JEPA는 개념적으로는 GA와 유사하다.
주요한 차이점은 인풋 스페이스가 아니라 임베딩 스페이스에서 loss를 계산하는 것이다.
JEPA는 호환가능한 x에서 임베딩을 추출하고 그걸로 y가 아니라 'y의 임베딩'을 예측한다.
또한 디코더가 아닌 예측 네트워크를 사용한다.
(픽셀으로 복구할 필요가 없고 임베딩을 예측한다는 말)
I-JEPA는 이 아키텍쳐를 인스턴스하며, 이미지와 미스킹 기법을 사용한다.
JEA와 다른점은 추가적인 정보 z가 hand-craft 증강 기법이 아니다.
JEA와 유사한 원인으로 차원 붕괴의 문제를 야기할 수 있는데(에너지 면이 평평함),
이를 피하기 위해 x인코더 y인코더에 비대칭 아키텍처를 적용했다.
(x인코더와 y인코더의 종류가 다름. 파라미터 업데이트 방식도 다름.)
3. Method
여기서 사용하는 인코더들의 종류가 궁금할 수 있다.
저자들은 ViT 아키텍처를 활용해 context 인코더, target 인코더, predictor를 만들었다.

3-1. Targets

타겟(=아웃풋)은 특정 이미지 블럭의 representation 이다.
이미지 y가 주어지면 겹치지 않게 N개 패치로 잘 쪼갠다.
이를 타겟 인코더 f에 넣고 패치 레벨의 representation s_y를 구한다.
패치 1개는 s 1개와 1대1 대응된다.
loss 계산을 위한 타겟을 얻기 위해 랜덤하게 블럭 M을 4개 샘플링한다.
(위 그림은 3갠데 실제는 4개다. Fig 4 처럼)
이 블럭의 종횡비는 랜덤(0.75~1.5), 스케일도 랜덤(0.15~0.2) 이다.
3-2. Context

컨텍스트(=인풋)은 이미지에서 단일 블럭 x를 샘플링한다.
이 블럭의 종횡비는 고정, 스케일은 랜덤(0.85~1.0) 이다.
(Fig 4를 보면 이해하기 쉽다)
여기에 타겟의 영역과 동일한 영역, 타겟 마스크, B로 마스킹 한다.
컨텍스트 인코더 f에 넣고 패치 레벨의 representation s_x를 구한다.
3-3. Prediction
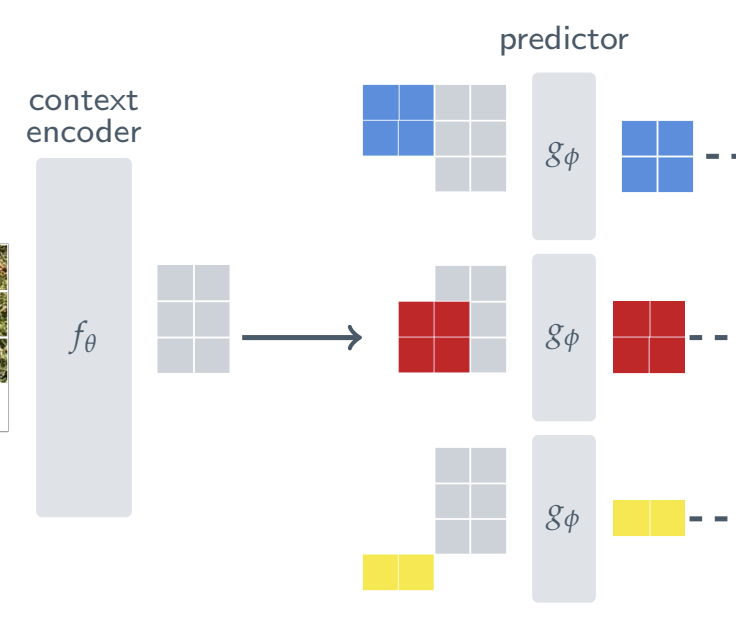
predictor g는 마스킹된 컨텍스트 인코더의 결과(s_x)를 인풋으로 받는다.
타겟 블럭 M의 패치레벨 representation(s_y)를 예측해야한다.
마스크 토큰은 파라미터화 되어 있다.
3-4. Loss
loss는 L2를 평균해서 사용한다.
블럭 당 L2를 구하고 4개의 평균값을 구한다.
predictor가 예측한 s_y와 타겟 인코더의 s_y로 loss를 계산한다.
predictor와 컨텍스트 인코더는 기존 방식(gradient)으로 업데이트 한다.
그냥 Adam, SGD 같은 optimizer을 쓴다는 이야기다.
타겟 인코더는 기존 방식을 사용하지 않고 다르게 업데이트 한다.
컨텍스트 인코더 파라미터의 exponential moving average를 계산하여 업데이트 하는데,
이것은 JEA 다른 논문에서 증명한 기법이다.
직접적으로 업데이트 하는 것이 아니라 간접적인 방법으로 업데이트한다.
결과 분석
1. Classification
자세한 조건은 논문 아래 부분 Appendix A 에 적혀있다.
1-1. ImageNet-1K
linear evaluation(=linear probing)방법으로 SSL 모델과 비교한다.
linear evaluation이란 SSL 후 인코더 블럭은 고정(frozen)하고 classification head만 학습하는 것이다.
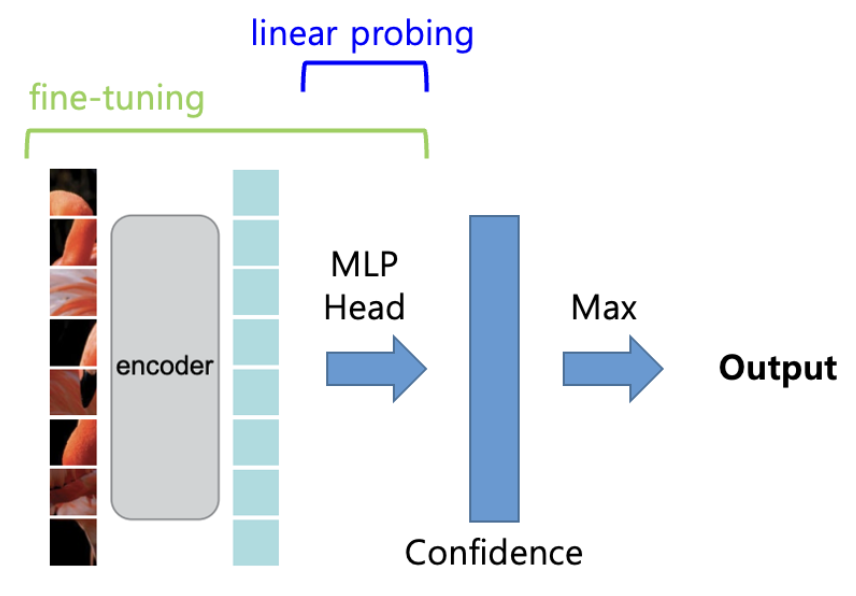
더 쉽게 설명하기 위해 MAE의 예시 그림을 보자.
fine-tuning은 사전 학습된 인코더와 MLP 헤드를 모두 학습하는 것이고,
linear probing은 사전 학습된 인코더의 웨이트는 고정하고 MLP 헤드만 학습하는 것이다.
이렇게 하는 이유가 뭘까.
SSL(자기지도학습)은 task가 classification이 아니다.
다시 말해 인코더 이후 부분을 떼고 MLP 헤드를 강제로 달아야 classification이 가능하다.
근데 이걸 달면 MLP 헤드 값은 뭘로 해야하냐는 것이다.
0으로 하면 당연히 다 틀린다. 랜덤한 값도 다 틀린다.
공평하게 평가하기 위해서 인코더는 더이상 학습을 하지 않고 MLP 헤드만 학습한다.
이게 linear probing 이다.

대표적인 모델(generative methods)인 data2vec, MAE, CAE 보다 좋은 성능이다.
또한 에포크 수가 크게 감소했는데, 약간의 트릭이 가미되었다고 생각할 수 있다.
다른 task는 1 iter에 1번 학습하는데 I-JEPA는 1 iter에 4번 학습한다.
이 부분은 뒷부분에 GPU 사용 시간이 적다는 점이 나온다.
추가 기법을 사용한 모델(invariance-based methods) iBOT 과 비교도 해보자.
I-JEPA Huge 448 모델과 iBOT ViT-L/16이 유사한 성능으로 나왔다.
1-2. Low-Shot ImageNet-1K

Low-Shot 기법이란 전체 이미지 중 1%(클래스 당 12~13 이미지)만 지도 학습하는 것이다.
표에 나온 값은 fine-tuning이든 linear probing이든 best 값을 표기했다.
마찬가지로 더 적은 에포크 수에서 더 좋은 성능을 보인다.
1-3. Transfer learning
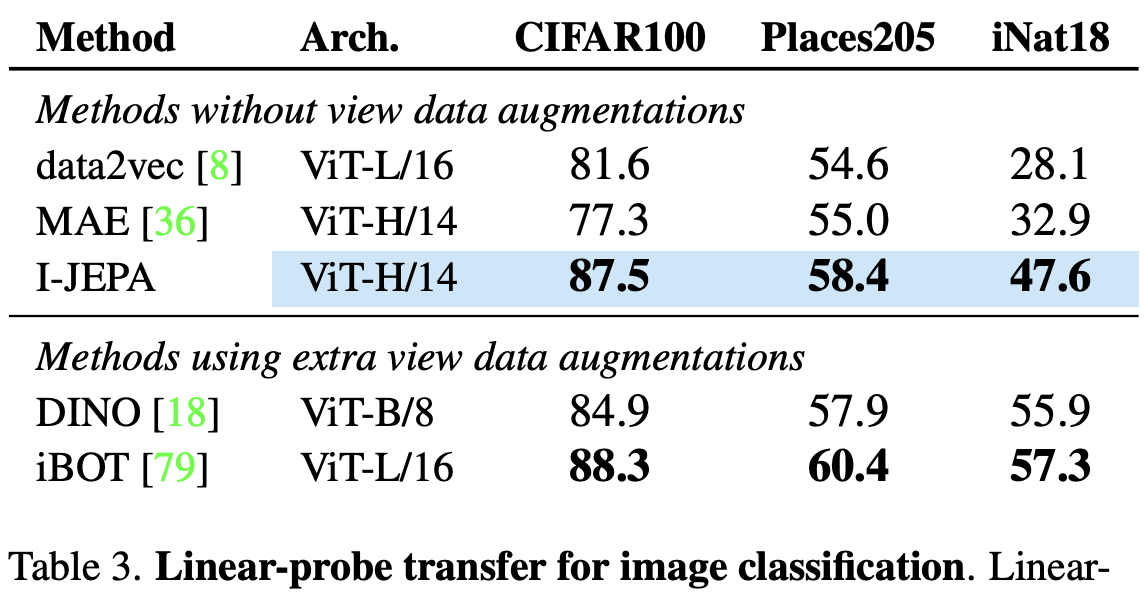
linear probing 방법 사용했다.
데이터셋 Cifar100, places205, iNat18 3가지를 평가한다.
마찬가지로 generative methods 중에서는 가장 좋은 성능을 보여줬다.
2. Local prediction tasks
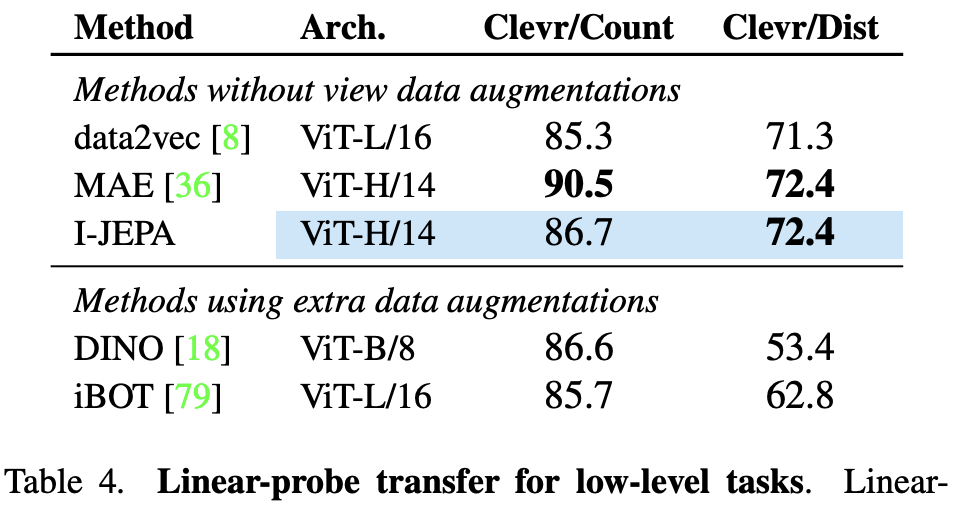
상대적으로 low level의 feature를 사용하여 처리하는 task 2가지다.
(object counting 와 depth prediction)
I-JEPA도 좋은 성능이나 MAE가 더 좋다.
3. Scalability
3-1. Model efficiency
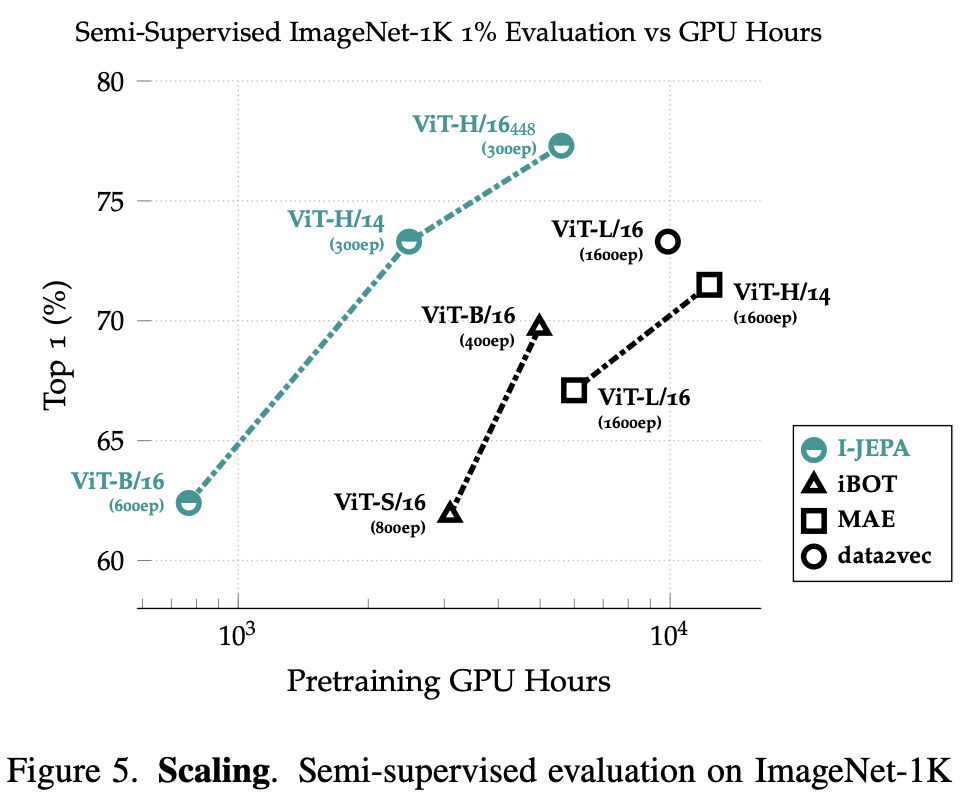
위에서 말했던 그래프다.
GPU hours를 보면 epochs 만 작은게 아니라 빠르다.
특히 generative methods 와 비교하면 차이가 크다.
3-2. Scaling data size

큰 프리트레이닝 dataset을 사용하면 더 성능이 좋았다.
ImageNet-1K 와 ImageNet-22K는 용량 차이가 진짜 엄청나게 난다.
근데 위 테이블의 결과를 보면 조금 이상한 부분이 있다.
ViT의 크기가 커지면 local prediction tasks이 오히려 낮아진다.
4. Ablation studies
4-1. Predicting in representation space

이 테이블이 논문 전체 논리를 대변하는 상당히 중요한 결과라고 생각했다.
픽셀 스페이스보다 추상 스페이스로 추론하는게 좋다.
에포크 수도 300이나 낮고 accuracy도 26%나 차이난다.
4-2. Masking strategy

다양한 마스킹 전략을 시도했다.
처음부터 논문에서 제시한 전략을 사용한 것은 아닌거 같다.
총 4가지 전략이 나온다.
multi-block : 논문의 전략
rasterized : 4분면으로 나누고 1개는 컨텍스트, 3개는 타겟.
block : 1개 불럭, 크기가 큰 블럭(0.6)
random : 랜덤한 패치, 합치면 크기가 큼(0.6)
미천한 신분이지만 내 생각을 말해보면,
이미지의 모든 부분을 다 넣을 필요도 없고, 이미지가 클 필요도 없다.
적당한 크기가 중요한 것으로 보인다.
0.2 정도 크기의 블럭이 이 학습 알고리즘에서 크리티컬 했던 것이다.
그리고 1개의 이미지를 여러번 사용하면 효율적이다.
즉 같은 이미지에서 여러개의 블럭을 뽑으면 좋다.
한 이미지에 대한 representation 이해를 같은 이미지 블럭에서 4번 학습한다.
그리고 그 학습들 중에서 오버피팅을 유발하는 것들은 평균내서 날려버린다.
속도 말고도 이런 이득이 있다.
코드 및 구현
'논문리뷰' 카테고리의 다른 글
| [논문 리뷰] DeiT 요약, 코드, 구현 (0) | 2024.05.13 |
|---|---|
| [논문 리뷰] V-JEPA 요약, 코드, 구현 (0) | 2024.04.30 |
| [논문 리뷰] Vision Mamba(Vim) 요약, 코드, 구현 (0) | 2024.04.17 |
| [논문 리뷰] Swin Transformer 요약, 코드, 구현 (0) | 2024.04.09 |
| [논문 리뷰] DenseNet 요약, 코드, 구현 (0) | 2024.04.05 |



