논문을 상세히 번역하고 한단어씩 해석해주는 포스팅은 많다.
나는 논문을 누구나 알아듣도록 쉽고 간결하게 전달하고자 한다.
MAE(Masked Autoencoders)
저자의 의도
MAE는 CV 분야의 scalable한 self-supervised 모델이다.
큰 모델을 효율적이고 효과적으로 학습해보자.
generalize가 잘 되는 높은 capacity를 가진 모델에 대하여 접근해보자.
기존 문제점
NLP의 BERT 모델에서 masked autoencoder 메서드를 잘 사용하고 있으나, CV에는 비교적 성능이 떨어진다.
BERT와 같은 transformer 모델은 실제로 NLP task를 위해 만들었다. 그래서 언어 특성을 잘 반영하고 있다.
하지만 CV에서 transformer를 꾸역꾸역 적용하고 있다. 이는 정밀한 치환 작업을 해줘야 한다.
NLP와 CV의 어떤점이 MAE에 차이점을 야기하는지 생각해보자.

1. CNN과 BERT의 architecture 차이
: CNN은 convolution network 기반이고, BERT는 attention network 기반이다.
하지만 이 부분은 ViT가 등장하며 어느정도 해결됐다.
2. Information density
3. Autoencoer의 Decoder 부분
해결 아이디어
1. Masking a high portion
언어는 인간이 만든 시그널이고, 이미지는 자연이 만든 시그널이다.
언어는 이미지에 비해서 높은 밀도의 정보를 가지고 있다. (단어는 문법, 의미, 맥락 등 다양한 정보를 포함한다.)
분명히 두 시그널은 다른 것이란 점을 인지하고 생각해야한다.
NLP 모델은 오직 적은 수의 단어만 예측하는데(BERT의 MAE),
그렇다고 해서 CV에서 적은 양의 mask를 해선 안된다.
정보 밀도의 수준이 다르기 때문이다.
따라서 저자들은 더 높은 portion의 마스킹을 해줬다.
이 전략은 정보 과잉을 해결해주고, 이미지 전체를 보는 능력을 요구한다.
2. Masking a random patches

pixel reconstruction task : 모르는 픽셀의 값(R, G, B)을 예측하는 것.
recognition task : 이미지를 이해하고 class(종류)를 맞추는 것.
CV에서는 디코더가 pixel reconstruction 작업을 하는데 이것은 recognition에 비해 low semantic level의 작업이다.
반면에, NLP에서는 디코더가 missing word 재구성 작업을 하는데 이것은 high semantic level의 작업이다.
따라서, pixel이 아닌 patches를 재구성 하게 만들고, token(=포지션)을 가려주어야 비슷한 수준의 작업이 된다.
그래서 저자들은 'patches'를 랜덤하게 가려줬다.
3. Approach
이 부분에서는 approach로 architecture와 training 디테일에 대하여 설명한다.
3-1. Masking
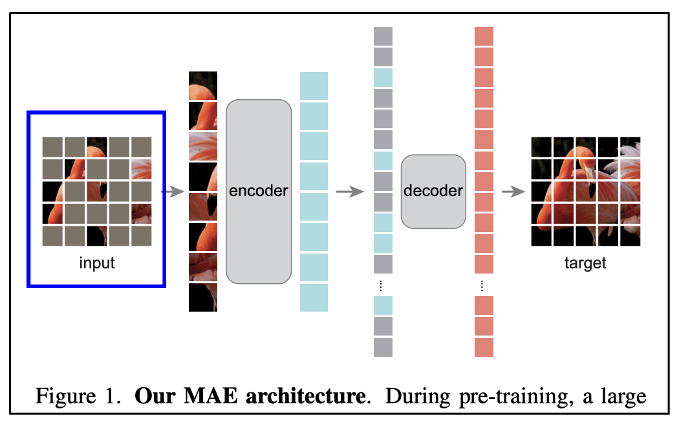
ViT는 이미지 전체를 패치로 쪼개서 넣게 되는데, MAE도 동일한 프로세스를 따른다.
이렇게 넣기 전에 높은 비율로 랜덤 샘플링해서 마스킹(회색으로 지워버림)을 해버린다.
이 방법을 통해 정보 과잉을 줄일 수 있다.
또한, 작업이 주변 패치에 의해 너무 손쉽게 풀리는 경우를 방지한다.
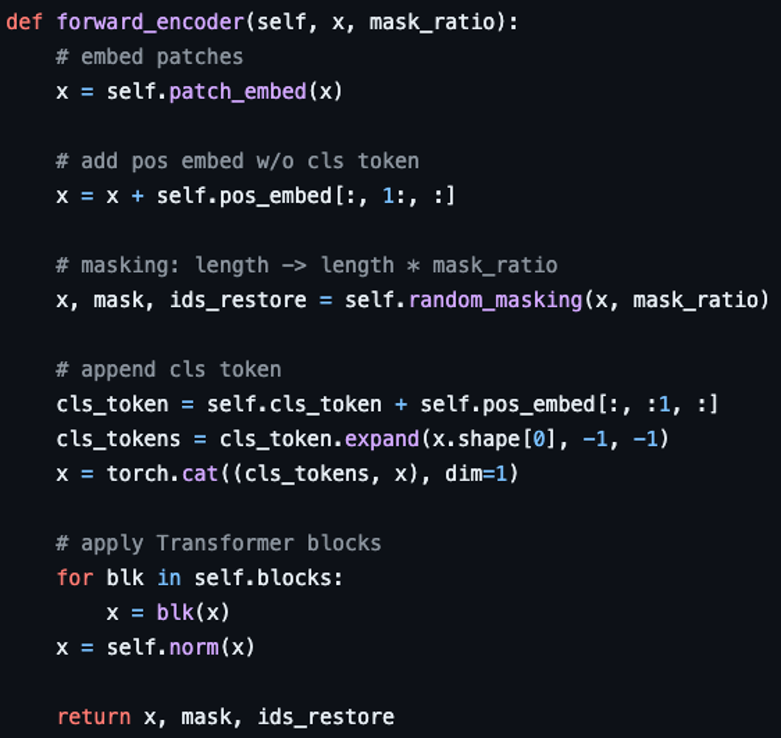
3-2. MAE encoder
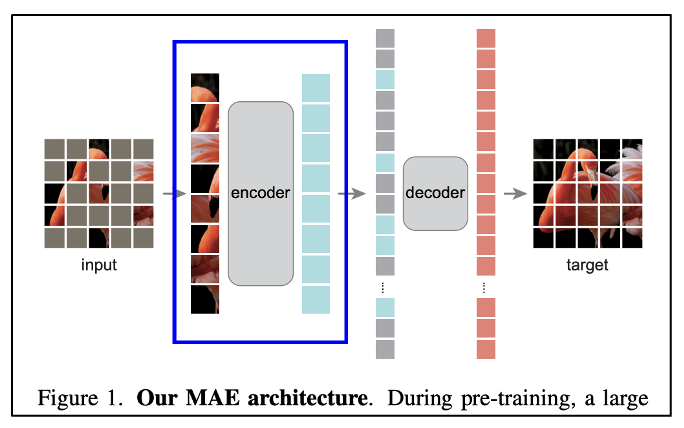
MAE의 인코더에는 ViT와 동일하지만 오직 마스킹되지 않은 패치 'sub set'만 인풋된다.
인풋과 아웃풋 모두 전체 사진에서 작은 포션(약 25%)의 패치 세트로 구성된다.
위 사진을 보면 총 25개의 인풋 패치 중에서 8개만 인코더로 들어간다.
이로써 계산량과 메모리의 일부만 사용하면서 매우 큰 크기의 인코더를 학습시킬 수 있다.
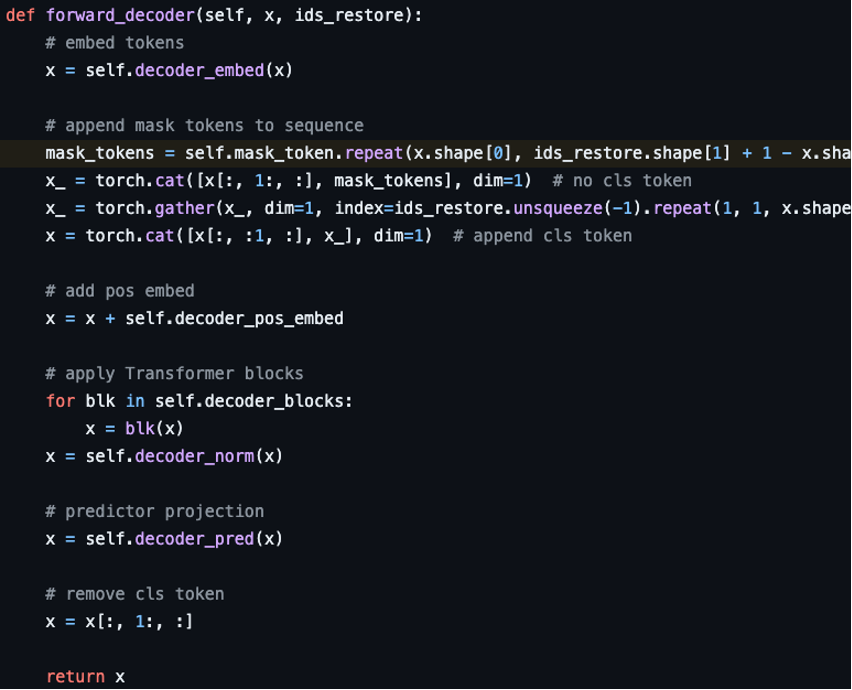
3-3. MAE decoder

MAE 디코더에는 마스킹되지 않은 패치와 마스킹된 패치 'full set' 모두 인풋된다.
위 사진에서 보면 인코더의 아웃풋 8개에서 다시 25개로 바꾸는 것을 볼 수 있다.
full set 모든 패치(=토큰)에 포지셔널 임베딩을 더해준다.
위 사진에서 보면 인풋에 있던 원래 자리로 돌려놓은 것을 볼 수 있다.
MAE의 디코더는 오직 pixel reconstruction task를 하는 pre-training에서만 사용된다.
인코더보다 작고 가볍고 얕게 설계하여 실험한다. (lightweight decoder)
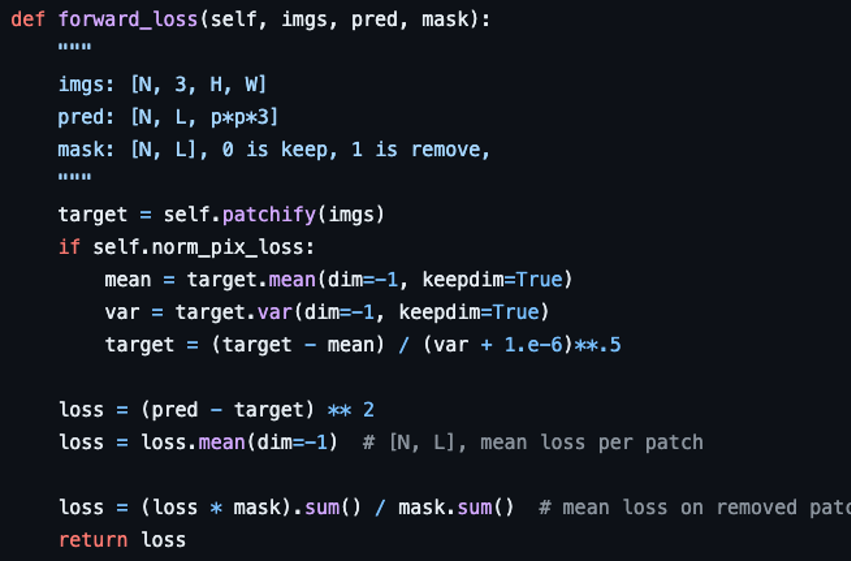
3-4. Reconstruction target
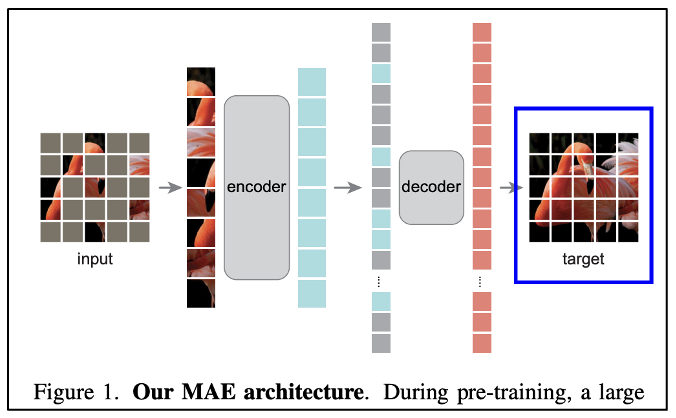
각 마스크 패치의 pixel value를 예측한다.
디코더의 아웃풋은 이미지의 형태를 재구성한다.
loss function으로는 pixel space에서 MSE를 계산했다.
BERT처럼 loss를 계산할 때 오직 마스킹된 패치만 계산했다.
(마스킹 안된 패치는 loss 계산 시 사용 안했다는 뜻)
결과 분석
1. ImageNet Experiments
1-1. Baseline: ViT-L/16

저자들의 강력한 regularization recipe로 기존 논문보다 좋은 결과가 나왔다.

pre-training은 ImageNet-1K로 reconstruction task를 self-supervised learning 했고,
fine-tuning은 ImageNet-1K로 recognition task를 supervised learning 했다.
MAE는 오직 50 epochs만 fine-tuning 했다. (반면에 ViT-L/16은 200 epochs를 진행함.)

fine-tuning과 linear probing은 별도의 레시피를 사용한다.
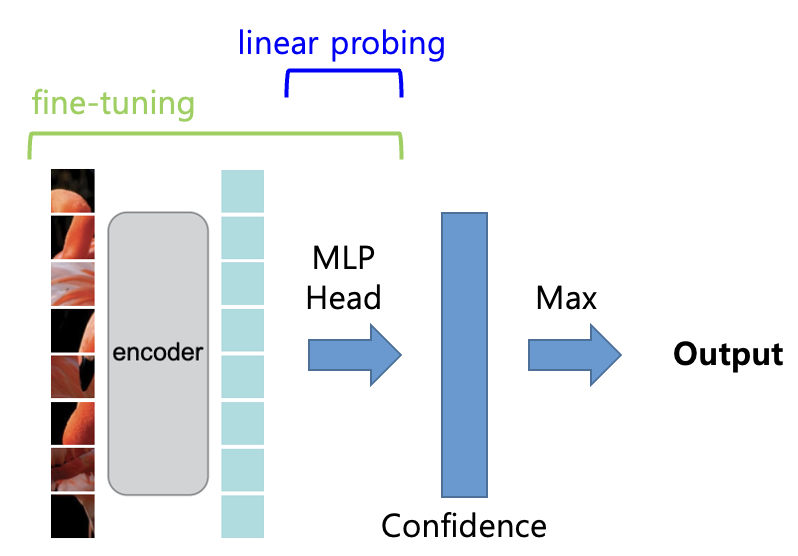
MAE로 fine-tuning과 linear probing의 차이를 알아보자.
fine-tuning은 사전 학습된 인코더와 MLP 헤드를 모두 학습하는 것이고,
linear probing은 사전 학습된 인코더의 웨이트는 고정하고 MLP 헤드만 학습하는 것이다.
1-2. Masking ratio

마스킹 비율은 75%가 fine-tuning과 linear probing 모두에서 가장 좋았다.
이는 BERT의 전형적인 비율인 15%와 크게 대조된다.
앞서 설명한 것처럼 언어와 이미지의 정보 밀도가 다르기 때문으로 해석할 수 있다.
fine-tuning과 linear probing는 비율에 따라 다른 트렌드를 보인다.
이는 pre-training이 pixel reconstruction으로 더 낮은 수준의 task였기 때문이다.
1-3. Decoder design
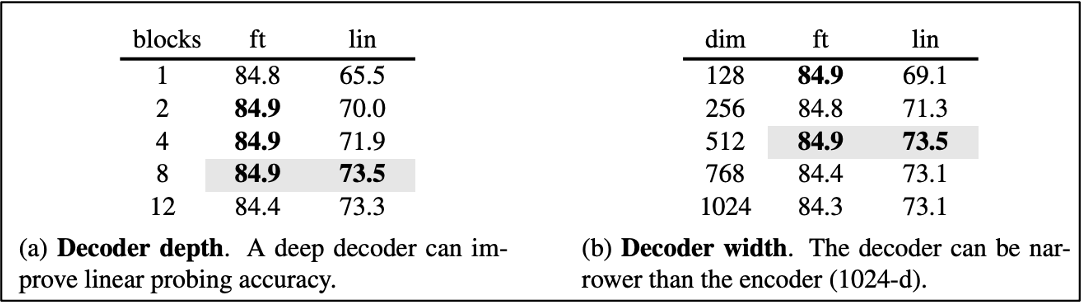
디코더의 depth와 width는 fine-tuning에서는 크게 중요하지 않았다.
이는 test 순간에는 디코더를 떼고 인코더만 사용하기 때문으로 해석할 수 있다.
따라서 가볍게 만들수록 이득이고 저자들은 최대한 가볍게 만들었다. (light weight)
디코더의 depth가 얕아질수록 인코더는 reconstruction task에 더 특화되는 경향을 보이고 recognition은 영향이 없다.
1-4. Mask token

인코더에 마스크 토큰을 넣냐 안넣냐에 따라서 약 3.3배의 FLOPs 차이가 있다.
(75%를 마스킹 하기 때문이다. 단순 암산으로도 이해 가능.)
따라서 저자들은 마스크 토큰을 인코더에서는 안넣고 효율적으로 학습했다.
이상한 점은 linear probing의 accuracy가 크게 좋아졌다는 점이다.
이건 뭔지 잘 모르겠다...
1-5. Augmentation, Schedule

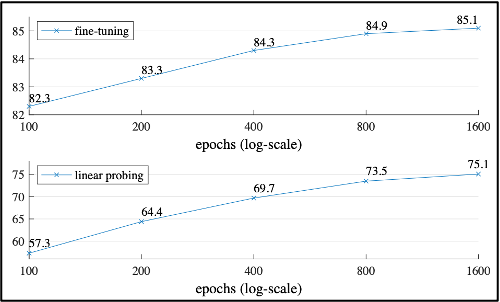
augmentation의 경우 crop과 random-size를 통해 accuracy가 조금 올라갔지만 안써도 크게 차이가 없다.
schedule의 경우 이 논문에 나온 결과는 기본적으로 800 epochs 까지 진행한 결과이다.
하지만 1600 epochs 까지 진행해도 saturation이 되지 않는 특징을 보인다.
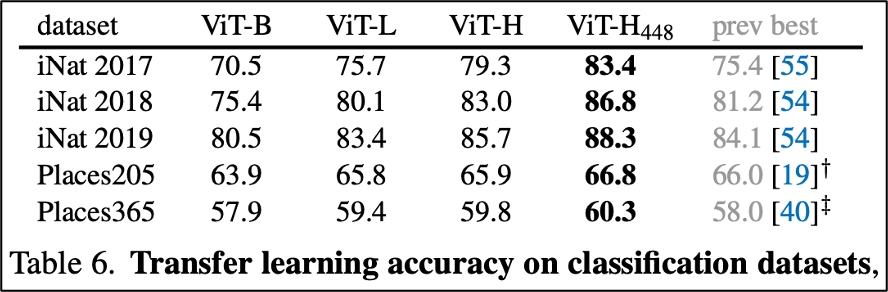
1-6. Compare with previous results
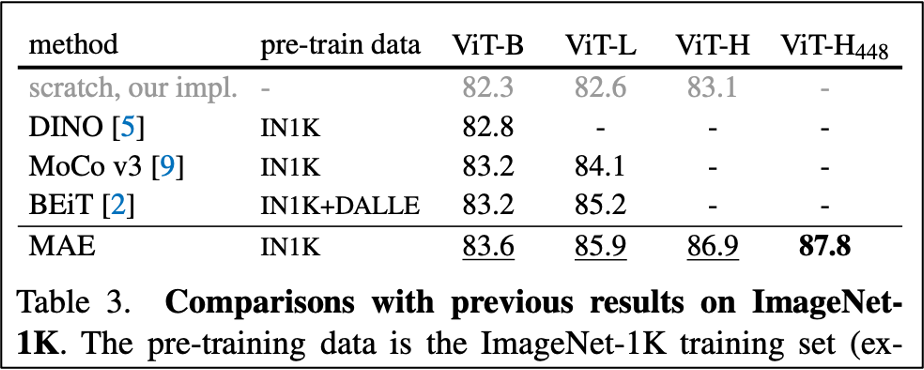
MAE(fine-tuning)과 다른 self-supervised ViT 모델들의 결과를 비교했다.
MAE는 448 size로 fine-tuning 시 87.8% 의 결과가 나왔다. (best)
기존 모델들에 비해서 근소하게 앞서는 결과가 나왔다.
이 모델은 오직 바닐라 ViT에 기반한 것이며, 더 발전된 모델은 더 좋은 결과를 얻을 수도 있다. (ex. BEiT, DeiT, DaViT, etc.)
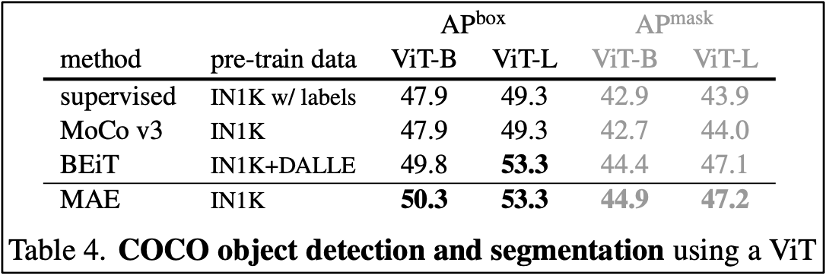
2. Transfer Learning Experiments

코드 및 구현
들어가서 보면 된다.
특징은 ViT의 메서드나 블럭들을 그대로 사용하는 편이다.
끝.
'논문리뷰' 카테고리의 다른 글
| [논문 리뷰] Swin Transformer 요약, 코드, 구현 (0) | 2024.04.09 |
|---|---|
| [논문 리뷰] DenseNet 요약, 코드, 구현 (0) | 2024.04.05 |
| [논문 리뷰] SAM(Segment Anything) 요약, 코드, 구현 (6) | 2023.09.13 |
| [논문 리뷰] MLP mixer 요약, 코드, 구현 (0) | 2023.07.15 |
| [논문 구현] ImageNet 다운로드 및 학습하는 방법 (0) | 2023.06.08 |



