논문을 상세히 번역하고 한단어씩 해석해주는 포스팅은 많다.
나는 논문을 누구나 알아듣도록 쉽고 간결하게 전달하고자 한다.
Vision Mamba
저자의 의도
최근 효율적인 디자인의 state space model(SSM) Mamba가 긴 시퀸스 모델링에 큰 가능성을 보여줬다.
하지만 SSM 에게도 비전 문제는 어려운 문제다.
비주얼 데이터의 위치 민감도와 이미지 전체 맥락에 대한 이해가 필요하다.
고해상도 이미지 처리가 가능한 고효율 비전 맘바 모델을 제시한다.
기존 문제점
Transformer는 속도와 메모리 문제가 크다.
Mamba를 사용하려고 해도 2가지 문제점이 있다.
이미지의 단방향성과 포지션에 대한 인식 부족이다.
비전 트랜스포머도 이 두가지 문제를 겪었다.
NLP 모델에 CV 데이터를 어떻게 적용할지 고민하면
이 2가지 문제를 해결할 필요가 있다.
배경 지식
1. SSM
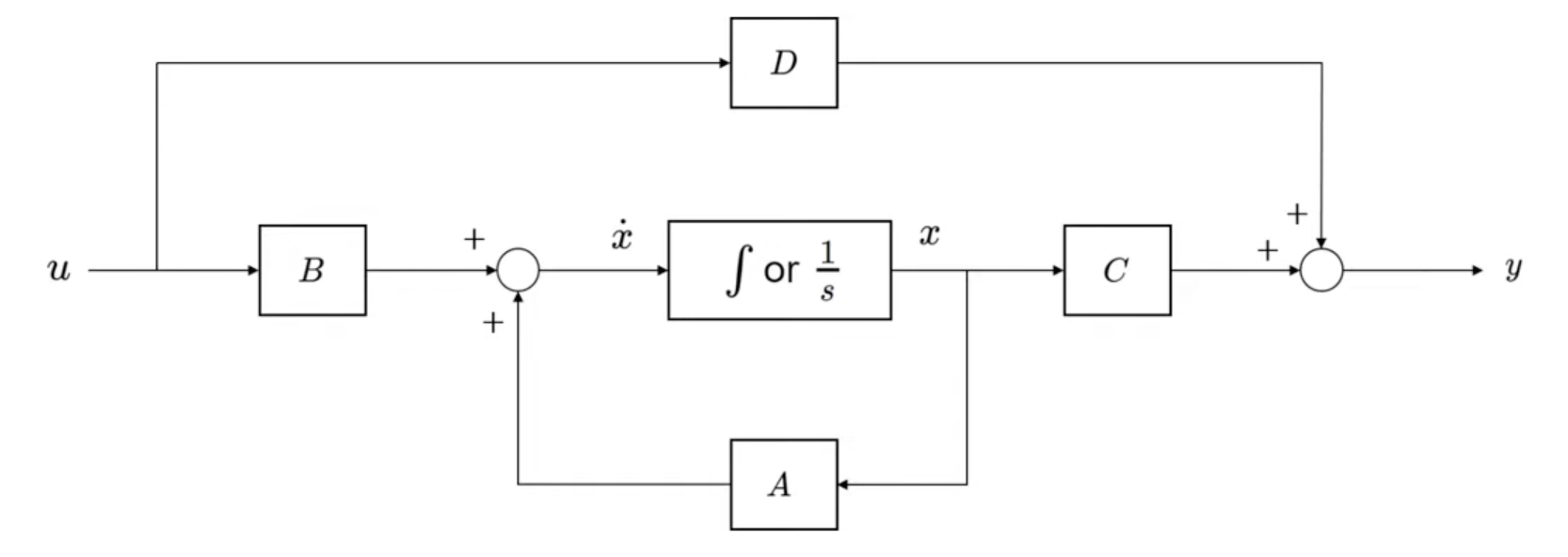
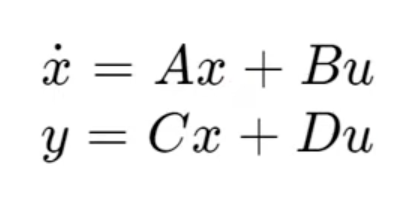
SSM은 NLP에서 제시된 모델으로,
시퀸스의 현재 상태를 입력해 미래 상태를 예측하는 모델이다.
트랜스포머와 하고자 하는 task는 동일하다.
그러나 RNN 처럼 장기기억, 단기기억, 게이트 개념이 들어간다.
여기서 State, 상태가 무엇인지 잘 알아야한다.
입력이 주어졌을 때, 전체 시스템과 출력을 완전히 describe 할 수 있는 최소 변수의 집합 이다.
공학 계열을 나온 사람은 단번에 이해했을거다.
미분 방정식을 푸는 알고리즘을 NLP에 맞게 모델링한 것이다.
(이해가 안되면 대충 넘어가자.)
2. Mamba
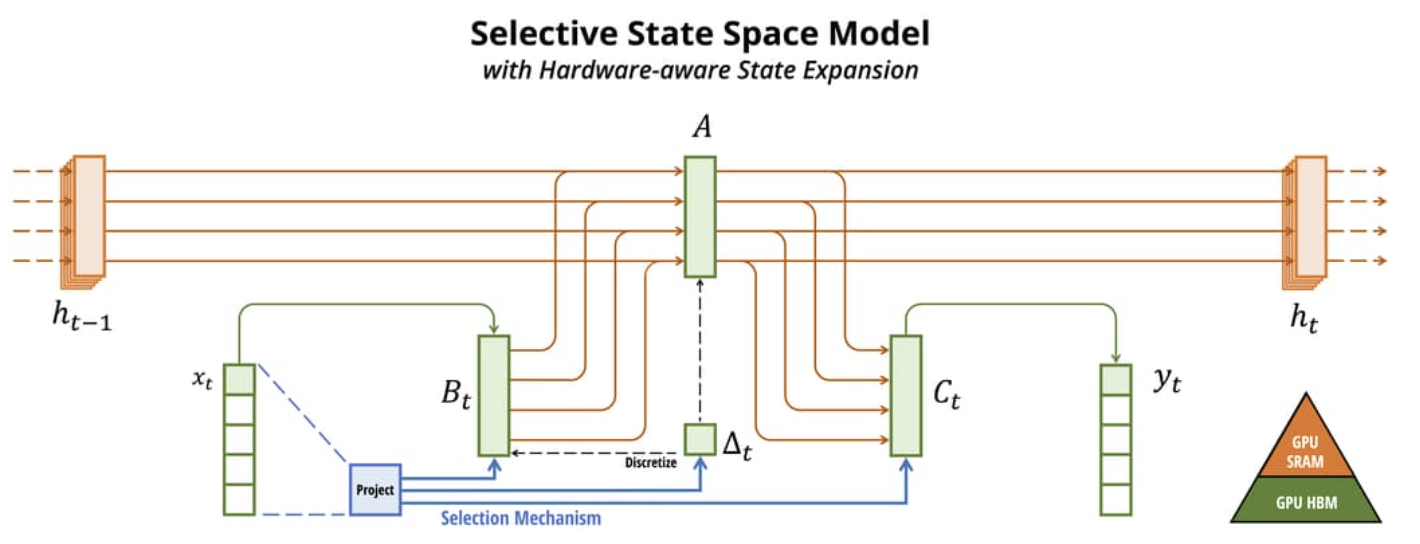
맘바는 이 SSM에 2가지 기법을 추가했다.
Hardware-aware, 하드웨어에 맞춤형으로 동작한다.
GPU를 자세히 보면 SRAM과 HBM이 있다. (요즘 하이닉스랑 연관된 그 HBM 맞음)
SRAM이 유리한 연산은 SRAM에 시키고
HBM이 유리한 연산은 HBM에 시킨다.
메모리를 극도로 절약할 수 있다.
SSM의 아키텍처는 계승하면서 트랜스포머의 MLP를 사용한다.
단순화된 아키텍처를 완성하였고 효율적인 연산을 한다.
(이해가 안되면 대충 넘어가자.)
해결 아이디어
1. S4 and Mamba
S4랑 Mamba 이 두 모델은 continuous system의 discrete system 버전이라고 할 수 있다.
(S4는 structured state space sequence model의 약어, 그냥 SSM 모델 중 하나)
discrete는 연속형 이산형 할때 이산형을 말한다. 끊겨 있는 자료형이다.
(미적분을 잘 모른다면 이 부분은 스킵하자.)
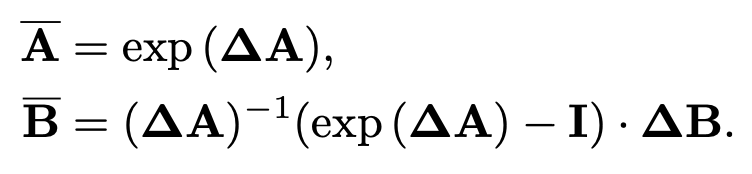
타임스케일 파라미터 Δ가 연속형 파라미터 A, B를 이산형 파라미터 A바, B바로 만든다.
여기서 사용하는 메서드가 zero order hold(ZOH), (2)이다.


(1)식을 타임스케일 Δ에서 (3)으로 나타낼 수 있다.

마지막으로 글로벌 합성곱을 통해 (4)으로 나타낼 수 있다.
여기서 M은 인풋 시퀸스 x의 길이 이고, K는 커널이다.
2. Vision Mamba
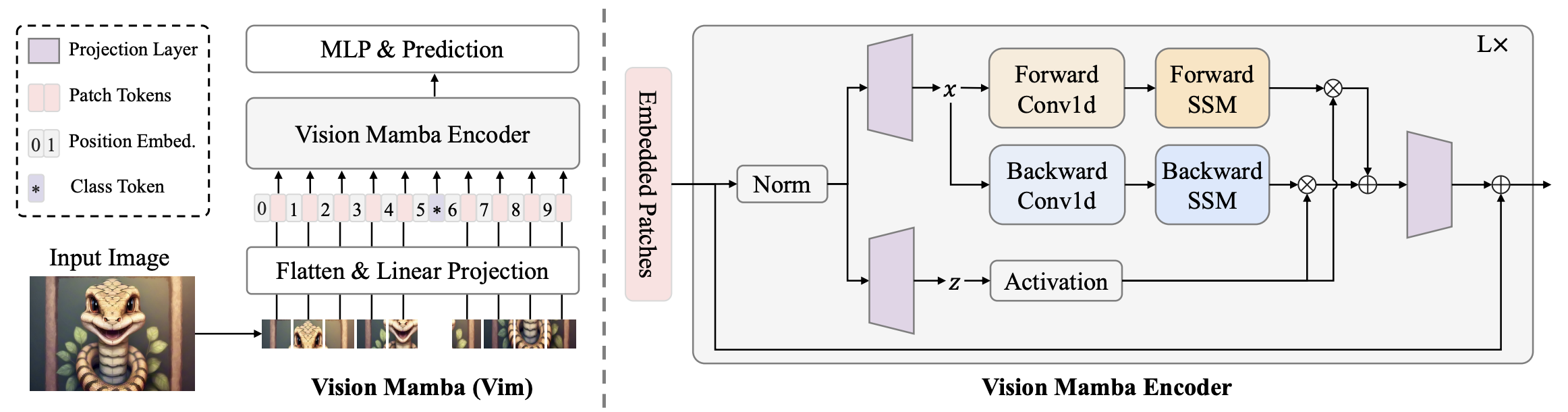
왼쪽 그림부터 보자.
스탠다드 맘바는 1차원 시퀸스 인풋으로 디자인 되어 있다.
비전에서 사용하기 위해 2차원 이미지를 플래튼된 2차원 패치로 만든다.
각 패치를 벡터 스페이스에 리니어 프로젝션 한다.
ViT와 BERT처럼 전체 시퀸스를 대변하는 클래스 토큰을 추가한다.
포지션 임베딩을 더해준다.
완성된 전체 시퀸스를 Vim 인코더 블럭에 넣는다.
노멀라이즈 와 MLP 헤드를 거쳐 최종 결과를 얻는다.
3. Vim block
이제 오른쪽 그림을 보자.
비전 task를 위한 bidirectional sequence modeling을 했다.
아까 위에서 SSM과 Mamba를 이해 못했더라도 여기만 알면 된다.
인풋을 노멀리제이션 뒤 리니어 프로젝션 한다.
dim 사이즈에 맞게 차원을 키운다.
이때 1개가 아니라 2개(x, z)를 만든다.
x는 포워드 방향, 백워드 방향 2가지로 진행된다.
1차원 Conv -> 리니어 프로젝션한다.
B, C Δ 3개로 만들어준다.
Δ는 A와 B를 A바와 B바로 만드는데 사용한다.
A바와 B바는 SSM을 사용해 y_forward와 y_backward를 계산한다.
z를 게이트로 사용하여 y_forward와 y_backward를 선택적으로 추출한다. (RNN methods)
두 결과를 더하면 최종 아웃풋 시퀸스 T_l가 나온다.
4. Architecture details
아키텍처의 상세한 값이다.
L(블럭 수), D(히든 스테이트 디멘션), E(익스펜디드 스테이트 디멘션), N(SSM 디멘션)
스탠다드 모델의 경우 (L=24, D=192, E=384, N=16) 를 갖는다.
16x16 패치, dim=384 인 DeiT가 비교 대상이다.
최대한 비슷하게 만든게 스탠다드 모델이다.
5. 효율성 분석
Vim은 하드웨어 친화적인 방법을 사용한다.
핵심 아이디어는 GPU의 IO 바운드와 메모리 바운드를 피하는 것이다.
5-1. IO Efficiency
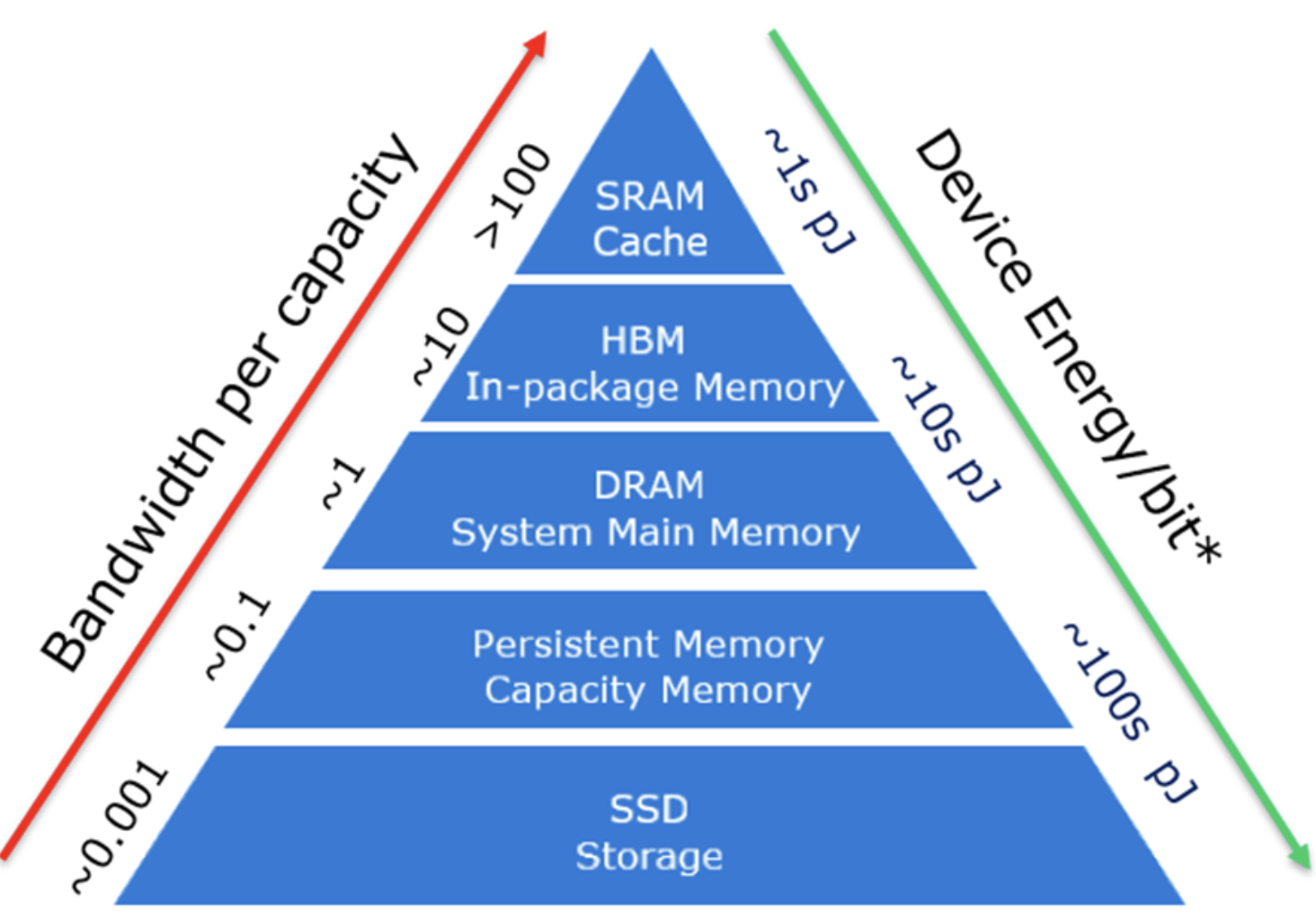
high bandwidth memory(HBM)과 SRAM이 중요하다.
보통 SRAM은 larger bandwidth, HBM은 bigger memory를 갖는다.
HBM을 사용한 Vim의 SSM 연산은 O(BMEN)차 메모리 수를 요구한다.
Mamba에서 사용한 방법을 Vim도 차용한다.
HBM이 아니라 더 빠른 SRAM을 사용한다.
SRAM을 사용하면 SSM 연산은 O(BME+EN)차 메모리 수를 요구한다.
SRAM의 연산이 끝나면 이를 HBM으로 전달한다.
더 빠른 SRAM을 사용했고, 연산에 사용된 메모리 수도 줄었다.
5-2. Memory Efficiency
긴 시퀸스가 들어오면 메모리가 부족해 멈추는 일이 많다.
(실제로 트랜스포머를 다루는 사람은 미친듯이 공감한다............)
이는 근본적으로 모든 양의 데이터를 '동시'에 계산해야 하기 때문이다.
Vim은 Mamba에서 사용한 recomputation method를 차용한다.
backward에서 gradient를 계산하려면 활성화 값을 계산해야 한다.
이 활성화 값은 저장할 경우 메모리를 크게 차지하지만,
다시 계산하면 빠르게 얻어낼 수 있는 특징을 가지고 있다.
따라서 'recomputation', '재계산' 전략을 이용해 메모리를 절약한다.
5-2. Computation Efficiency
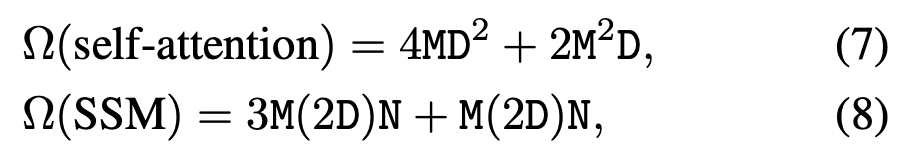
셀프 어텐션 레이어와 SSM의 계산 복잡도는 (7), (8) 이다.
셀프 어텐션 레이어는 시퀸스 길이 M에 대하여 2차함수 이다.
SSM은 시퀸스 길이 M에 대하여 1차함수 이다.
결과 분석
1. Classification
디테일 :
ImageNet 1K, input size=224,
(랜덤 크롭, 랜덤 플립, 라벨 스무딩, 믹스업),
AdamW, cosine annealing,
batch size=1024, epochs=300, lr=1e-03
추가로 long sequence fine-tuning 이란걸 한다.
기존의 패치 사이즈 (224/4 = 56) 에서 8으로 대폭 줄여서 훨씬 긴 시퀸스를 만든다.
여기에 30 에포크 만큼 학습한다.
성능 최적화, 더 복잡한 디테일을 캡쳐하는 능력 향상 효과를 얻는다.

CNN과 비교 : 비슷한 사이즈 Res50과 Vim-S 4.3% 높다.
ViT의 최적화 모델인 DeiT와 비교 : Ti와 S 모두 높다.
SSM 기반 모델인 S4ND-ViT와 비교 : 크기는 3배 적지만 비슷한 성능.
추가로, 앞서 말한 추가 기법 long sequence fine-tuning 를 진행하면 더 좋아진다.
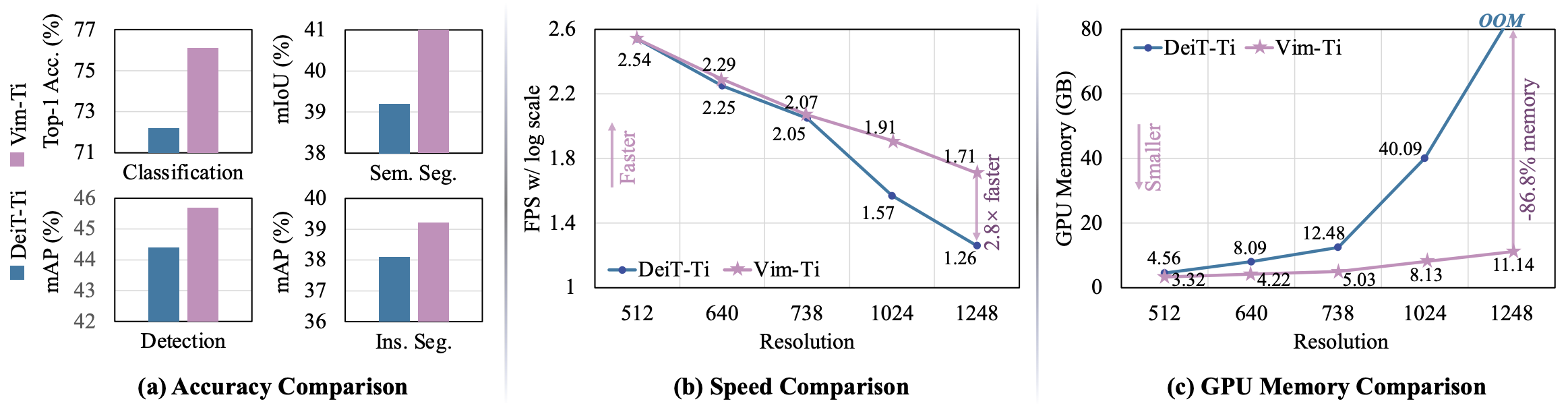
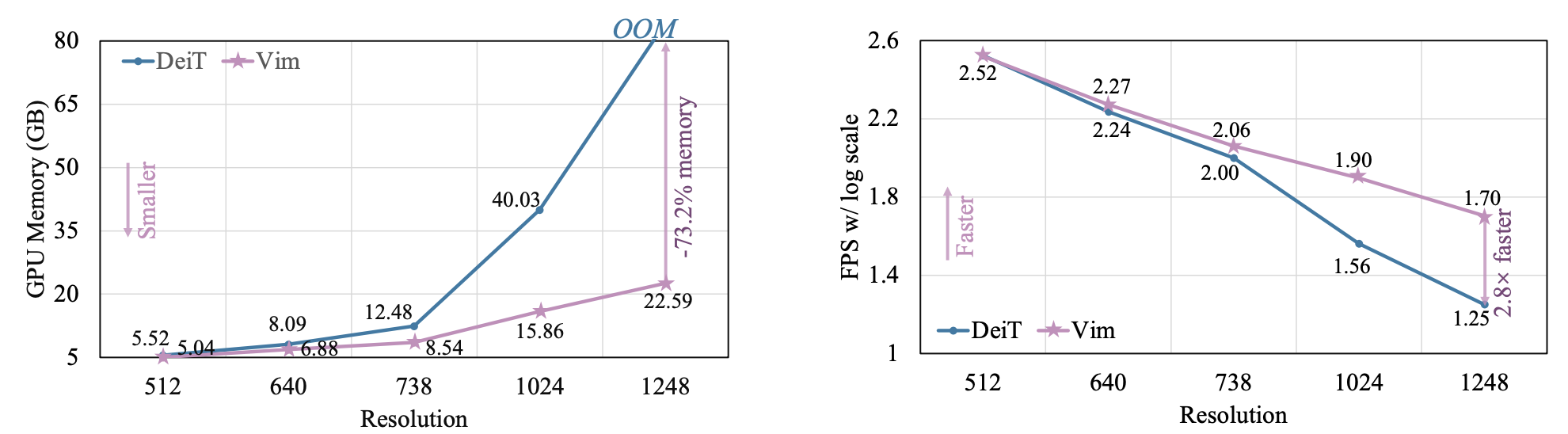
FPS와 GPU 메모리 사용량 비교.
일단 Vim의 성능이 더 좋은데 이미지 사이즈가 커지면 커질수록 격차가 벌어진다.
더 긴 시퀸스 일수록 메모리와 연산을 덜 사용하면서도 성능은 좋다.
2. Semantic segmentation
디테일 : ADE20K, UperNet framework

DeiT와 비교 : Ti와 S 모두 높다.
CNN과 비교 : 큰 사이즈의 ResNet101과 같은 성능.
다운 스트림을 효율적으로 평가하기 위해 FPN 모듈 적용했다.
마찬가지로 기존 백본들에 비해 이미지가 커질수록 효율성 격차가 크다.
3. Object detection, Instance segmentation
디테일 : COCO 2017, ViTDet framework
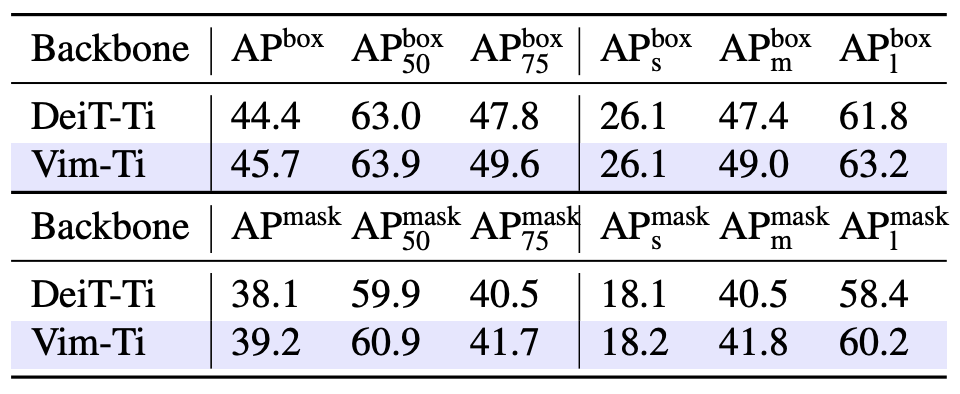
DeiT와 비교 : AP box와 AP mask 모두 좋은 성능.
4. Ablation study
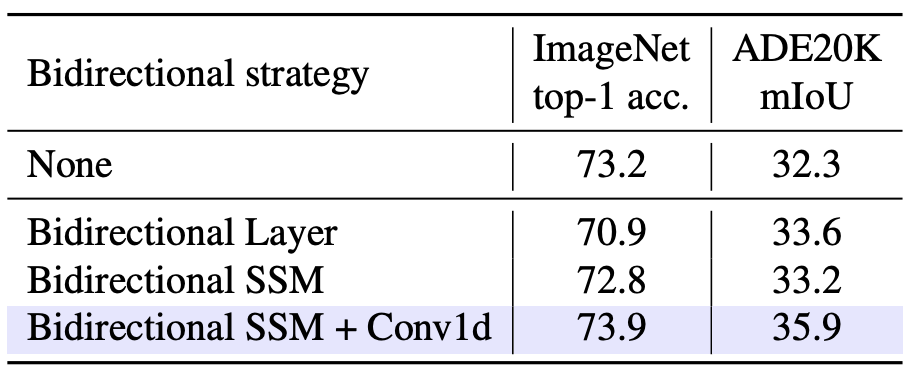
Bidirectional SSM 빼면 성능이 드랍된다.
다만 SSM과 Conv1D 결합하여 사용해야만 한다.
코드 및 구현
'논문리뷰' 카테고리의 다른 글
| [논문 리뷰] V-JEPA 요약, 코드, 구현 (0) | 2024.04.30 |
|---|---|
| [논문 리뷰] I-JEPA 요약, 코드, 구현 (0) | 2024.04.22 |
| [논문 리뷰] Swin Transformer 요약, 코드, 구현 (0) | 2024.04.09 |
| [논문 리뷰] DenseNet 요약, 코드, 구현 (0) | 2024.04.05 |
| [논문 리뷰] MAE(Masked Autoencoders) 요약, 코드, 구현 (4) | 2023.10.12 |



