논문을 상세히 번역하고 한단어씩 해석해주는 포스팅은 많다.
나는 논문을 누구나 알아듣도록 쉽고 간결하게 전달하고자 한다.
DeiT
저자의 의도
convolution layer가 없으면서도 경쟁력 있는 트랜스포머를 만들어보자.
1개의 컴퓨터에서 3일 이내에 학습해보자.
디스틸레이션 토큰과 teacher-student 전략을 활용한 트랜스포머를 만들어보자.
기존 문제점
ViT는 매우 크게 만들고 사람이 레이블링한 데이터셋을 사용하는게 트렌드다.
ViT/G-14 같은 논문을 보면 스케일링을 엄청나게 늘려서 초거대 모델로 만든다.
그런데 이 연구들의 결론이 큰 데이터셋을 사용하면 generalize가 잘 되지 않는다는 것이다.
그리고 이런 모델들은 막대한 컴퓨팅 리소스(GPU, 시간, 전력)을 요구한다.
다시 말해 퍼포먼스는 올라가지만 실용 불가능할 정도로 느리고 무거워지고 있다.
해결 아이디어
1. Knowledge distillation

이 논문에서는 teacher-student 전략을 '트랜스포머'에 적용한다.
그 teacher-student 전략의 레퍼런스에 해당하는 이론을 먼저 보자.
스튜던트 모델(더 작은 모델)과 티처 모델(더 큰 모델)이 있다.
스튜던트 모델이 티처 모델의 소프트 레이블으로 학습한다.
하드 레이블 : 티처 모델의 소프트맥스 함수의 결과로 원핫 인코딩된 레이블.
소프트 레이블 : 티처 모델의 소프트맥스 바로 직전 확률분포 레이블.
스튜던트 모델 : 대규모 모델인 티처의 성능을 복제를 목표로 하는 작은 모델.
티처 모델 : 스튜던트 모델이 계승할 지식의 원천이 되는 잘 훈련된 모델.
이 전략으로 학습하면 모델 크기를 줄이면서도 generalization이 더 잘된다.
이 논문에서는 T 스튜던트와 C 티처 혹은 T 티처 조합을 사용할 예정이다.
2. Distillation through attention
이 메서드는 아주 명확한 목적을 가진다.
강력한 이미지 classifier를 가진 티처 모델을 착취하여 트랜스포머를 학습한다.
2가지 주제 (soft vs hard), (classical vs token) 에 대하여 알아보자.
2-1. Soft vs hard

soft distillation을 먼저 알아보자.
이 방법은 스튜던트와 티처의 확률분포 간의 kullback-leibler 차이를 loss로 취급하여 반영한다.
(kullback-leibler는 확률 분포 간의 다름을 나타내는 척도이다.)
티처와 스튜던트의 예측 확률 분포를 Z_t, Z_s라고 하자.
τ는 디스틸레이션에 대한 temperature 이고, λ는 KL loss와 CE loss 간의 비율이다.
이때 전체 디스틸레이션의 loss는 Equation 2 이다.
간결하게 설명하면 그냥 확률분포 간의 차이를 loss에 넣고, 기존 loss와 비율을 정해주자는 것이다.

이제 hard-label distillation을 보자.
기존 distillation의 변형으로 저자들이 제시한 방법이다.
티처의 hard decision을 마치 true label 처럼 사용한다.
y_t를 티처의 예측 확률 분포의 최대값(=그냥 레이블)이라 하자.
이때 디스틸레이션의 loss를 Equation 3로 한다.
잘 보면 loss를 1대1 비율로 나눠서 반영하는 것이다.
기존 방법보다 더 간단하며, 티처의 결정이 마치 레이블처럼 사용된다.
확률분포를 사용한게 아니라 label을 사용한다.
(참고)
여기서 label smoothing 기법을 사용하면 hard label이 soft label이 될 수 있다.
label smoothing은 true label의 확률을 1-ε 으로 두고 ε은 모든 다른 레이블에 균등 분배한다.
이러면 예측에 대하여 지나치게 신뢰하지 않는다.
hard label을 사용함으로써 생길 수 있는 지나친 확신에 대한 bias를 제어해줄 수 있다.
2-1. Classical vs token

distillation token을 알아보자.
초기 임베딩에 distillation token을 넣고 학습할 것이다.
디스틸레이션 토큰은 클래스 토큰과 유사한 역할을 부여 받는다.
티처의 아웃풋을 주로 학습하는 전용 토큰이다.
MLP head를 사용하지 않고 선형 classifier를 사용한다. (FC레이어가 2~3개가 아니라 1개)
그리고 토큰이 2개니까 선형 classifier를 2개를 사용한다. (클래스, 디스틸레이션)
타 토큰이 직접적으로 영향을 받지 않으면서도 상호보완적으로 티처 모델의 아웃풋을 활용할 수 있다.
실제로 클래스 토큰과 디스틸레이션 토큰의 시작값은 서로 다른 벡터로 수렴한다.
그런데 레이어가 진행되면서 임베딩은 점점 유사해진다.
2개의 클래스 토큰을 가진 모델인데 1개는 티처의 수도 레이블인 것이다.
결과 분석
1. Transformer models
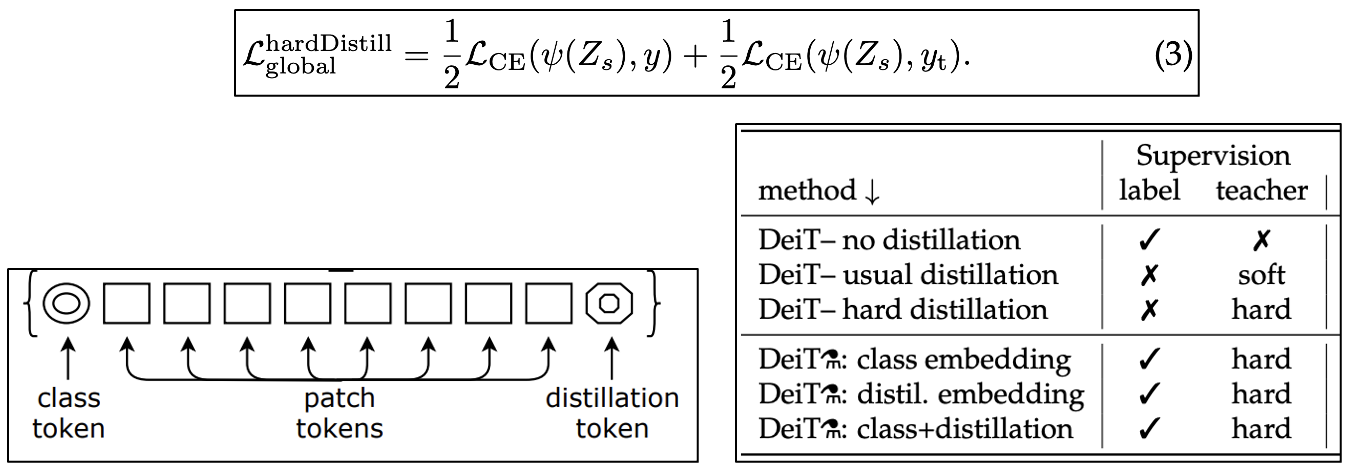
ViT와 다른 점은 트레이닝 전략과 디스틸레이션 토큰 딱 2개다.
ViT와 최대한 잘 비교하기 위해서 Base 모델의 디멘션이나 어텐션 헤드수 같은 하이퍼 파라미터를 모두 동일하게 했다.
여기 용어가 헷갈리는게 나온다.
DeiT가 있고 DeiT⚗가 있는데 조건은 아래와 같다.
DeiT: 디스틸레이션 토큰 O, 디스틸레이션 트레이닝 전략 X
DeiT⚗: 디스틸레이션 토큰 O, 새로운(label+hard) 디스틸레이션 트레이닝 전략 O
2. Distillation
2-1. ImageNet
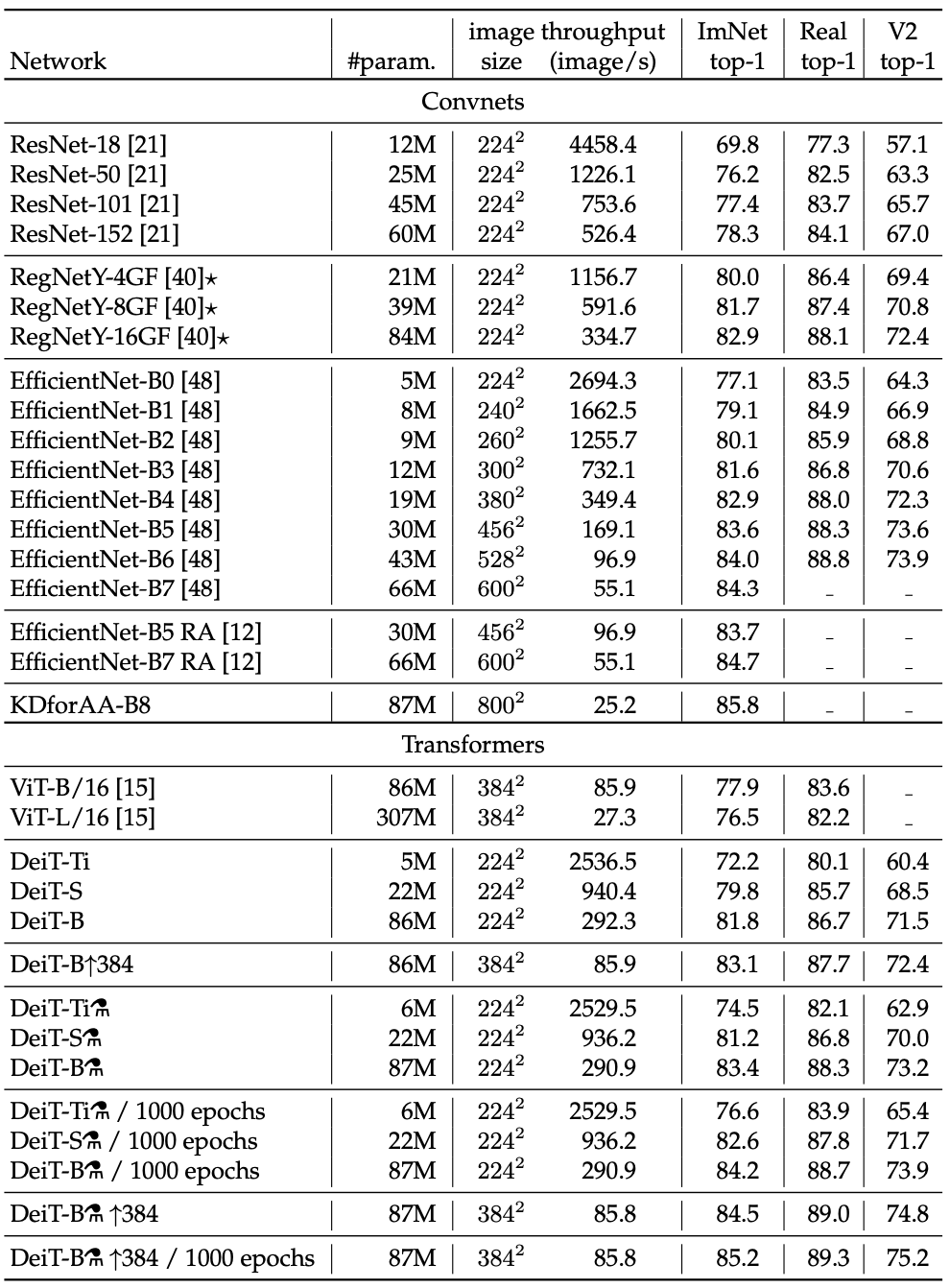
디스틸레이션 모델이 교사 모델들 보다 좋은 점은 accuracy 와 throughput 간의 트레이드오프 측면이다.
DeiT 베스트 모델은 ViT의 초대형 데이터셋(JFT-300M) 프리트레이닝 모델보다 뛰어나다. (85.2% vs 84.15%)
2-2. CNN teachers

실험 결과 트랜스포머 티처보다 CNN 티처가 더 좋은 퍼포먼스가 나온다.
트랜스포머 디스틸레이션 간에 inductive bias가 상속되기 때문이다.
그래서 이 논문의 디폴트 티처는 RegNetY-16GF 이다.
2-3. Comparision of distillation methods

지도방식을 기존, soft 티처, hard 티처로 했을때 hard 티처가 좋다.
하지만 그 보다도 label과 hard를 같이 사용하는 경우가 제일 좋았다.
클래스 토큰만, 디스틸레이션 토큰만, 두 토큰 모두 했을때 두 토큰이 미세하게 높다.
2-4. Ablation studies

코드 및 구현
'논문리뷰' 카테고리의 다른 글
| [논문 리뷰] MoCo v2 요약, 코드, 구현 (0) | 2024.05.27 |
|---|---|
| [논문 리뷰] MoCo v1 요약, 코드, 구현 (0) | 2024.05.22 |
| [논문 리뷰] V-JEPA 요약, 코드, 구현 (0) | 2024.04.30 |
| [논문 리뷰] I-JEPA 요약, 코드, 구현 (0) | 2024.04.22 |
| [논문 리뷰] Vision Mamba(Vim) 요약, 코드, 구현 (0) | 2024.04.17 |



