논문을 상세히 번역하고 한단어씩 해석해주는 포스팅은 많다.
나는 논문을 누구나 알아듣도록 쉽고 간결하게 전달하고자 한다.
Swin Transformer
Swin transformer: Hierarchical vision transformer using shifted windows.
이 논문은 MS에서 작성했다. (Microsoft Research Asia)
따라서 많은 사람들이 GPT와 DALL-E 후속 모델의 backbone으로 지속 사용하고 있다고 추측하고 있다.
저자의 의도
transformer를 language 도메인에서 vision 도메인으로 최적화 시켜보자.
Swin(shifted window)로 representation을 연산하는 계층 구조(hierarchical)의 transformer를 제안한다.
이 hierarchical 구조는 다양한 스케일(이미지 사이즈)에 모델이 유연하게 해준다.
vision 도메인에서 transformer 기반 모델의 잠재성을 확인해보자.
기존 문제점
1. Scale of tokens
NLP 쪽에서 단어 토큰은 기본 구성요소로써 합당하다.
그런데 CV 쪽에서 비주얼 토큰은 스케일이 자꾸 변한다.

예를 들어 이미지넷 안에 새와 같은 데이터에서
아주 꽉차게 사진이 찍힌 객체가 있는 반면,
새가 2마리 이상 있는 경우 아주 작게 찍혔다.
그런데 이건 둘다 새다. 구분은 없다. 그냥 새다.
어떤 새는 (200x200) 사이즈고 어떤 새는 (30x30) 사이즈다.
스케일이 자꾸 변한다.
그런데 기존에 있던 transformer 모델은 이 토큰의 크기를 고정해놨다.
이 문제를 해결하는 아이디어가 필요하다.
2. Computational complexity
NLP에 비해 CV는 기본적으로 데이터가 크다.
고해상도 이미지를 처리해야 한다.
사실 이미지넷 데이터셋 (224x224) 이것도 작다.
우리가 아주 보편적으로 사용하는 (1920x1080) 이것에 비해 작다.
그런데 더 최악인 점은 computational complexity(연산 복잡도)의 트렌드다.
복잡도는 이미지 사이즈에 대하여 2차 함수로 증가한다.
쉽게 말해서 이미지가 커지면 연산량도 무한대로 발산한다.
해결 아이디어
1. Shifted windows
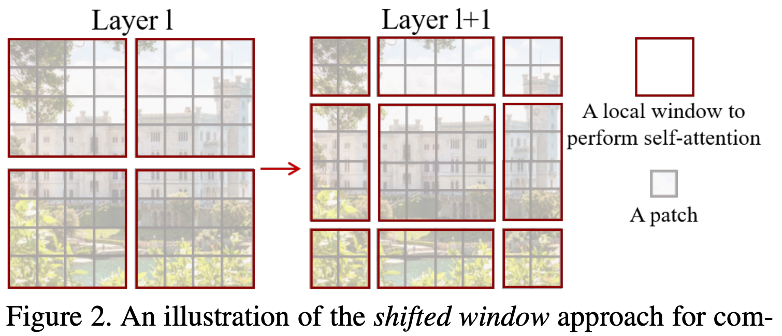
핵심 아이디어 중 하나가 바로 이 쉬프트 윈도우다.
레이어1에서 왼쪽과 같은 윈도우 구성을 했다면,
레이어2에서 오른쪽과 같은 윈도우 구성을 한다.
기존의 CV 분야의 transformer 와는 다르게 직전의 윈도우의 경계를 넘어서는 연산을 한다.
이 과정은 윈도우들을 연결시켜주고 모델의 퍼포먼스를 올려준다.
또한 윈도우 내에서 모든 패치의 쿼리는 같은 키 셋을 사용한다.
Q, K, V 중에 K가 같다는 말이다.
따라서 더 효율적으로 연산하고 지연시간이 적어진다.
2. Overall architecture
모델의 전체적인 구조를 살펴보자. 총 4~5 단계를 진행한다.
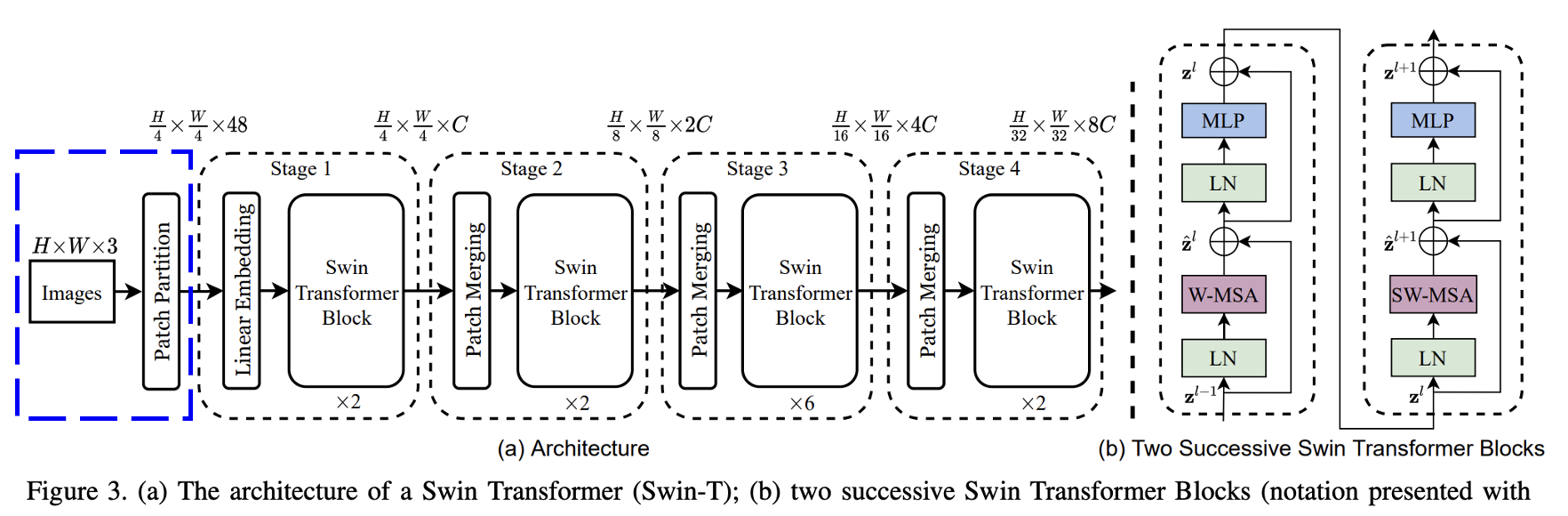
stage 0 이다.
RGB 이미지가 인풋되면 이를 겹치지 않는 패치로 조각조각 자른다.
각 패치는 (4x4) 크기 이다.
그리고 이 패치는 당연하게 (4x4 픽셀) x (RGB 3채널) 이므로,
(4x4x3=48)의 디멘션을 갖는다.
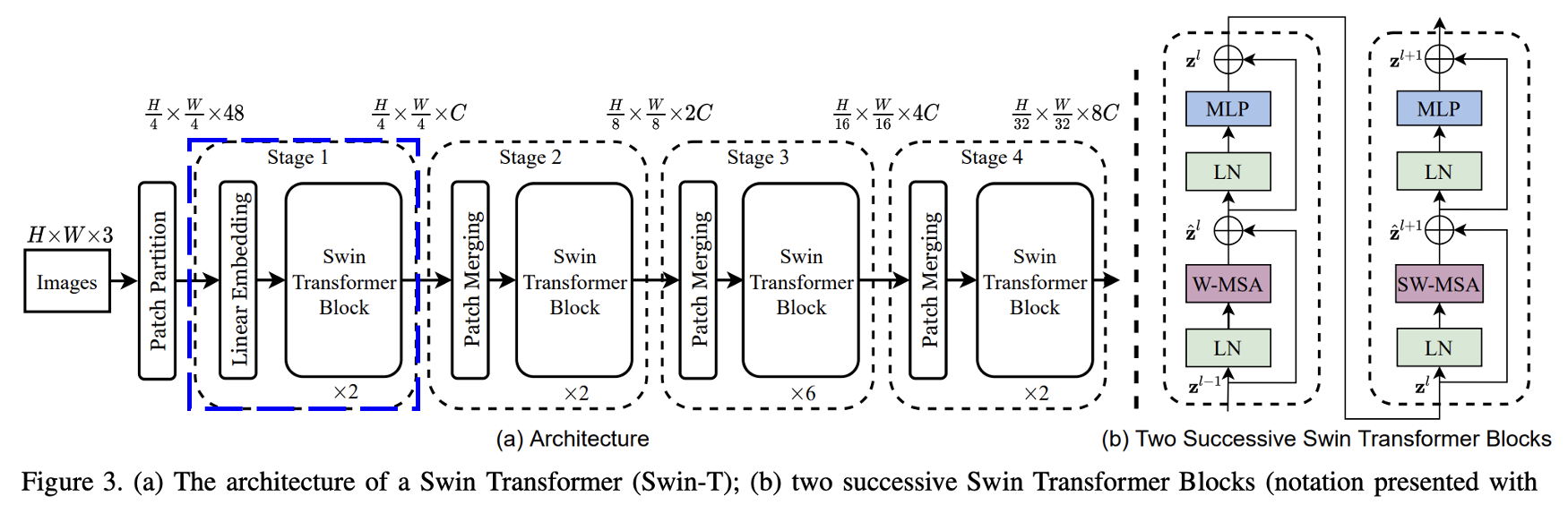
stage 1 이다.
먼저 리니어 임베딩 레이어를 통과한다.
앞선 토큰들의 feature 들이 디멘션 C로 project, 프로젝션, 전사 된다. (48 -> C)
swin transformer block은 토큰의 갯수에는 영향을 주지 않는다. (H/4 x W/4 유지)
그래서 아웃풋의 shape는 (H/4 x W/4 x C)가 된다.

stage 2 이다.
여기서는 패치 머징 레이어를 통과한다.
모델을 더 깊게 만들고 더 복잡한 추론을 하게 하기 위함이다.
이 머징을 통해서 패치의 갯수는 줄어든다. ((H/4 x W/4) -> (H/8 x W/8))
머징 레이어는 (2x2)만큼 주변 패치의 feature를 concatnate로 합쳐버린다.
즉 (C 4개 concatenate -> 4C) 이다.
그리고 머징 레이어 내부에는 리덕션 레이어가 있어서 이를 절반으로 전사한다.
즉 (4C -> 2C) 이다.
결론적으로 (C -> 4C -> 2C)로 최종 결과는 2C 이다.

stage 3과 4 이다.
stage 2를 2번 더 반복한다.
내부 알고리즘은 동일하다.
따라서 패치의 갯수는 줄어든다. ((H/8 x W/8) -> (H/16 x W/16) -> (H/32 x W/32))
또한 패치의 디멘션은 늘어난다. ( 2C -> 4C -> 8C)
이러고 MLP로 들어간다. 끝이다.
패치의 크기, 갯수, 윈도우 크기, 갯수 등이 너무 많다.
뒤에 나오는 설명이 헷갈릴 수 있다.
그래서 실제 예를들어 정리한 자료다.
이걸 이해해야 나중에 복잡도가 줄어드는게 이해되는데.....
이해가 안되면 그냥 대충 넘어가자.

3. Shifted window based self-attention

그림처럼 MSA는 W-MSA와 SW-MSA 2개가 있다.
MSA는 multi-head self-attention의 약자다.
W는 window, SW는 shifted window의 약자다.
MSA 모듈은 (MSA 레이어) + (2개의 MLP 레이어) + (중간에 gelu 활성화 함수)를 포함한다.
layer normalization은 각 모든 MSA와 MLP 전에 진행된다.
shift 한다는건 아까 위에서 말한 내용이다.
그림처럼 레이어가 진행되면 윈도우를 이동시킨다는 거다.
저자들은 이 구조의 장점을 총 3가지로 설명한다.
3-1. Non-overlapped windows

swin transformer는 전체 이미지에 self-attention을 하는게 아니다.
각 로컬 윈도우 1개 내에서만 self-attention을 진행한다.
이 윈도우들은 서로 겹치지 않는 규칙을 가진다.
이런 특징은 인풋 이미지가 커지더라도 큰 문제가 없도록 만들어준다.
그 이유를 이제 설명하겠다. 여기 MSA는 multi-head self attention의 약자다.
일반적인 MSA, 이미지 전체를 글로벌하게 보는 MSA는 이미지 크기에 대하여 2차 함수다.
h x w에서 h는 이미지 전체에서 height 방향의 패치의 갯수다. (w는 width)
패치의 갯수는 곧 시퀸스의 길이다. 입력의 길이라는 말이다.
따라서 셀프 어텐션에서는 레이어가 1개니 1차 함수, MLP에서는 리니어 레이어가 2개니 2차 함수다.
반면에 W-MSA, 윈도우 내에서만 보는 MSA는 이미지 크기에 대하여 1차 함수다.
윈도우 한 변의 패치 갯수가 M이라고 한다면 M에 대하여만 2차함수다. (hw에는 1차 함수)
그런데 이 M은 고정된 값으로 변하지 않는다.
위 패치 머징 슬라이드에서 말했던 것인데, 윈도우가 커지면 패치의 크기가 커진다.
즉 패치의 갯수는 고정되어 있고 크기만 커지는 것이다.
따라서 MLP 단계의 연산량이 1차 함수로 고정된다.
일반적인 MSA는 큰 hw에 매우 취약하다.
GPT에 수많은 양의 텍스트를 막은 이유도 이것이고
이미지 모델에 크기를 제한하는 이유도 이것이다.
그런데 W-MSA를 사용하면 상대적으로 scalable 하다.
3-2. Shifted window partitioning

윈도우를 기반으로 하는 MSA 모듈은 윈도우 간의 연결이 부족하다.
이는 모델이 이미지의 일부만을 보고 전체를 보지 못하는 약점을 야기할 수 있다.
저자들은 이런 문제를 해결하기 위해 특이한 파티셔닝 알고리즘을 사용했다.
위 그림처럼 L번째 레이어 다음 L+1번째 레이어는 아래 규칙을 따른다.
전체 윈도우를 ([M/2], [M/2]) 위치만큼 이동한다.
생성된 윈도우들 간에는 서로 겹쳐서는 안된다.
이 어프로치는 주변 윈도우들과의 연결을 만들어준다.
3-3. Efficient batch computation

여기까지 들으면 좋은 생각이긴 한데 어떻게? 엥? 그게 가능해? 라는 생각이 든다.
특히 당신이 코딩까지 해야한다면 더 그렇게 생각이 들 것이다.
왼쪽 그림을 보자.
기존에는 2x2=4개 였던 윈도우가 3x3=9개가 된다.
또 각 윈도우가 크기가 제 각각이 되었다.
정 중앙의 윈도우는 크기가 그 전과 같다.
하지만 팔방향의 다른 윈도우는 크기가... 이상하다.
여기서 네이브한(응용이 없는) 솔루션은 이렇다.
작아진 윈도우에 패딩을 넣고 9개 윈도우를 억지로 사용한다.
컴퓨팅 과정에서 패딩을 넣은 것을 마스킹한다.
하지만 저자들의 솔루션은 이렇다.
오른쪽 그림을 보자.
9개의 영역 중에서 정중앙, 그 오른쪽, 그 밑, 그 오른쪽 밑 4개만 사용한다.
기존보다 작은 영역만 사용할거다. 그럼 나머지는 버려? 그렇다.
이를 cyclic-shifting 이라고 하며 작은 윈도우는 패딩 후 마스킹 과정을 거친다.
이 부분은 상당히 이상한데 라고 생각했다.
저자 깃허브 코드 전문을 봤더니
한번은 오른쪽밑 한번은 왼쪽위 이런식으로 하는 거 같은데,
동적인 코드가 너무 많아서 나는 잘 해석을 못했다.
(그냥 내 뇌피셜이다. 궁금하면 깃허브를 보고 분석해보자.)
결과 분석
1. Architecture variants

총 4개의 모델이 있고 그 디테일이다.
base 모델인 Swin-B는 ViT-B와 비슷한 크기로 맞췄다.
T는 그 1/4배, S는 그 1/2배, L은 그 2배 크기다.
모든 윈도우의 M은 7로 고정이다.
2. Image classification on ImageNet

학습 디테일

가장 좋은 성능이 나왔다.
3. Object detection on COCO

학습 디테일
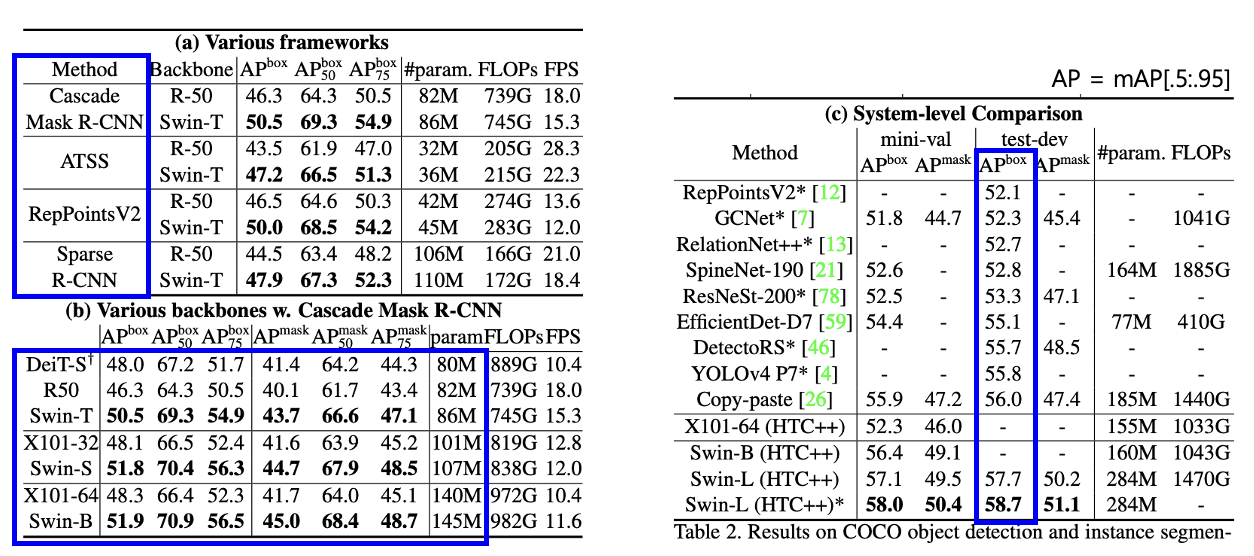
가장 좋은 성능이 나왔다.
4. Semantic segmentation on ADE20K

가장 좋은 성능이 나왔다.
코드 및 구현
끝.
'논문리뷰' 카테고리의 다른 글
| [논문 리뷰] I-JEPA 요약, 코드, 구현 (0) | 2024.04.22 |
|---|---|
| [논문 리뷰] Vision Mamba(Vim) 요약, 코드, 구현 (0) | 2024.04.17 |
| [논문 리뷰] DenseNet 요약, 코드, 구현 (0) | 2024.04.05 |
| [논문 리뷰] MAE(Masked Autoencoders) 요약, 코드, 구현 (4) | 2023.10.12 |
| [논문 리뷰] SAM(Segment Anything) 요약, 코드, 구현 (6) | 2023.09.13 |



