논문을 상세히 번역하고 한단어씩 해석해주는 포스팅은 많다.
나는 논문을 누구나 알아듣도록 쉽고 간결하게 전달하고자 한다.
DenseNet
HUANG, Gao, et al. Densely connected convolutional networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2017. p. 4700-4708.
저자의 의도
숏 커넥션이 포함된 경우 CNN은 훨씬 더 깊고 정확하게 만들 수 있다.
DenseNet은 피드 포워드 방식으로 각 레이어를 다른 모든 레이어에 연결한다.
기존의 CNN보다 더 많은 연결로 밀도 높은, Dense한 CNN을 만들어보자.
기존 문제점
정보들은 여러 레이어를 통과하면서 희석되고 사라질 수 있다. (gradient vanish)
ResNet은 각 레이어와 바로 뒤 레이어만 연결한다.
ResNet은 feature를 결합할때 element-wise summation을 사용한다.
이 element-wise 연산보다 더 복잡한 규칙을 찾을 수 있는 다른 연산을 사용할 필요가 있다.
배경 지식
이 모델은 기본적으로 ResNet의 문제점을 해결한다.
전체를 다 알 필요는 없으므로 필요한 부분만 보자.

ResNet의 핵심 아이디어는 skip-connection 이다.
이를 통해서 레이어를 지나면서 생기는 비선형 변환을 우회한다.
비선형 변환을 하면 좋은점이 많지만, gradient vanish 현상이 발생한다.
앞서 말한 정보의 희석과 사라짐 현상이다.
이 skip-connection을 통해서 identity(원천 정보)가 직접 뒤로 전달된다.
그런데. 이 identity와 뒷 레이어의 output이 단순 덧셈으로 결합된다.
이 덧셈 연산은 정보의 흐름을 방해할 여지가 있다.
(ResNet 포스팅 전문을 보고싶다면 여기)
[논문 리뷰] ResNet 요약, 코드, 구현
논문을 상세히 번역하고 한단어씩 해석해주는 포스팅은 많다. 나는 논문을 누구나 알아듣도록 쉽고 간결하게 전달하고자 한다. ResNet Deep Residual Learning for Image Recognition Kaiming He, Xiangyu Zhang, Shaoqin
davidlds.tistory.com
해결 아이디어
1. Dense Connectivity
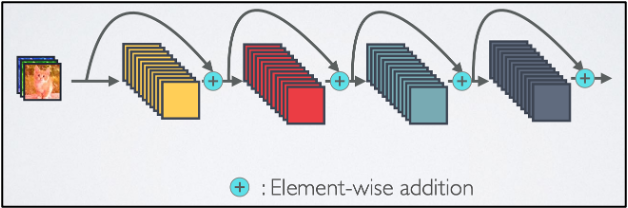

레이어간 정보 흐름을 향상시키기 위해서 단순 덧셈이 아닌 다른 방법을 사용하자.
그 방법은 바로 concatnate이다.
concatnate는 특정 방향으로(차원으로) feature를 쌓는 것이다.
따라서 덧셈이 정보의 흐름을 방해할 여지가 있는 반면 concatenate는 그럴 걱정이 없다.
2. Growth rate

ResNet과 중요한 차이점은 DenseNet이 더 narrow한 레이어를 가질 수 있다.
shallow(얕은)게 아니라 narrow(좁은) 것이다. 즉 더 효율적이다.
저자들은 하이퍼파라미터 k를 growth rate로 설정했다.
위 그림의 최종 output을 global state 혹은 collective knowledge 라고 말할 수 있다.
feature를 추출하고 거기서 또 추출하고 반복해서 그걸 쌓은 것이기 때문이다.
k는 각 레이어가 global state에 얼마나 기여를 했는지 라고 생각할 수 있다.
3. Bottleneck layers

ResNet은 bottleneck layer를 제안하며 input의 수를 줄이고 효율성을 증가시켰다.
저자들은 DenseNet에 적합한 bottleneck으로 기존의 레이어를 변형했다.
총 2개의 레이어로 이루어져 있다.
1번 레이어 : batch normalization -> ReLU -> (1x1 Conv, 4*k)
2번 레이어 : batch normalization -> ReLU -> (3x3 Conv, k)
이는 목적성에 따른 결과라고 볼 수 있다.
ResNet은 덧셈을 하므로 입력과 출력의 shape가 같아야 한다.
반면 DenseNet은 Concat을 하므로 shape 중 가로 세로만 같으면 되고 채널은 달라도 된다.
따라서 그에 따라 변형한 것이라 볼 수 있다.
4. Pooling layers

CNN에서 가장 중요한 파트는 feature를 작은 사이즈로 바꾸는 'down-sampling layer'이다.
덴스 블럭 사이에 둬서 transition layer로 사용했다.
이 transition layer는 3개로 구성되어 있다.
(batch normalization) -> (1x1 Conv) -> (2x2 average pooling)
5. Compression
위에서 말한 transition layer를 통해서 피쳐맵을 줄일 수 있다. (=압축)
피쳐맵은 이 트랜지션 레이어를 지나면서 절반으로 줄어든다.
이 절반은 실험을 해봤을때 가장 좋은 퍼포먼스가 나왔던 값이다.
Architecture
정리해서 아키텍쳐에 대한 전체적인 흐름을 보자.
인풋은 128x128 사이즈의 RGB 3채널 이미지다.

인풋이 들어오면 일단 채널이 뻥튀기가 필요하다.
(256, 7x7 Conv)로 해준다.
그 다음 dense 블럭으로 들어간다.
블럭은 작은 블럭 3개로 이루어져 있다.
작은블럭은 (128, 1x1 Conv), (32, 3x3 Conv), concatenate 이다.
인풋을 보면 작은 블럭이 한번 끝날 때마다 채널이 점점 커지는 것을 볼 수 있다.
그 다음 transition 레이어로 들어간다.
채널을 한번 압축하고 (=Conv), 가로세로를 한번 압축한다. (=AVG pool)
이해를 했다면 실제 모델을 보자.
실제 이미지넷 같은 이미지는 보통 인풋이 224x224 사이즈다.
각 타입의 모델은 아래와 같은 구조를 따른다.
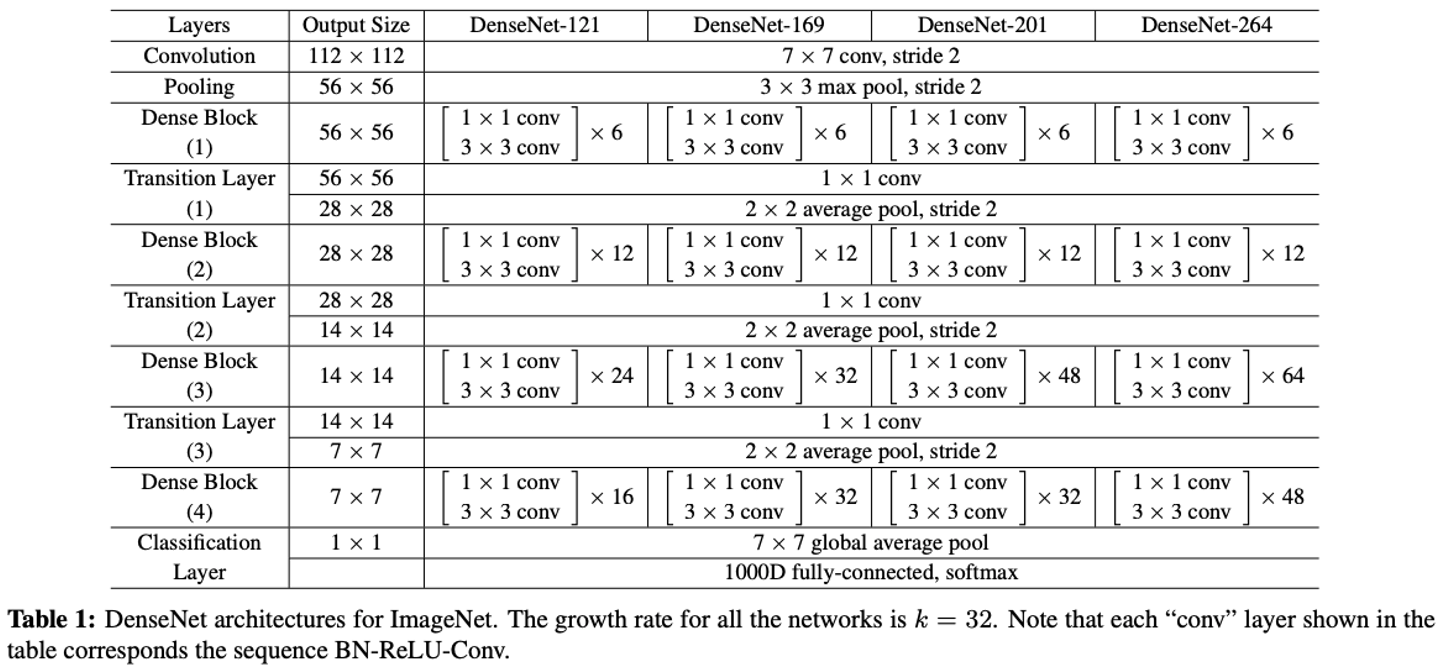
결과 분석
트레이닝 디테일은 아래 정리를 참고하자.
[CIFAR and SVHN]
- SGD
- Batch size = 64
- Epochs = 300 and 40
- Learning rate = [0.1, 0.01, 0.001] at epochs [0%, 50%, 75%]
[ImageNet]
- SGD
- Batch size = 256
- Epochs = 90
- Learning rate = [0.1, 0.01, 0.001] at epochs [0, 30, 60]
추가 기법 : (weight decay of 10-4), (Nesterov momentum of 0.9), (dropout rate to 0.2)
1. CIFAR and SVHN

ResNet에 비해 정확도가 높다.
Cifar10과 Cifar10+를 비교해보면 ResNet에 비해 차이가 작다. (Capacity가 좋다)
FractalNet과 비교하면 파라미터 수에 비해 정확도가 높다. (효율적이다)
2. ImageNet

DenseNet은 ResNet에 비해 파라미터수도 적고 연산량도 적은데 성능도 좋다.
DenseNet-201은 20M 정도의 파라미터고, ResNet-101은 40M 정도의 파라미터로 절반 정도다.
그러나 우측 그래프를 보면 에러가 거의 비슷하다.
코드 및 구현
timm 라이브러리 발췌
class DenseNet(nn.Module):
r"""Densenet-BC model class, based on
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
Args:
growth_rate (int) - how many filters to add each layer (`k` in paper)
block_config (list of 4 ints) - how many layers in each pooling block
bn_size (int) - multiplicative factor for number of bottle neck layers
(i.e. bn_size * k features in the bottleneck layer)
drop_rate (float) - dropout rate after each dense layer
num_classes (int) - number of classification classes
memory_efficient (bool) - If True, uses checkpointing. Much more memory efficient,
but slower. Default: *False*. See `"paper" <https://arxiv.org/pdf/1707.06990.pdf>`_
"""
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16), bn_size=4, stem_type='',
num_classes=1000, in_chans=3, global_pool='avg',
norm_layer=BatchNormAct2d, aa_layer=None, drop_rate=0, memory_efficient=False,
aa_stem_only=True):
self.num_classes = num_classes
self.drop_rate = drop_rate
super(DenseNet, self).__init__()
# Stem
deep_stem = 'deep' in stem_type # 3x3 deep stem
num_init_features = growth_rate * 2
if aa_layer is None:
stem_pool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
else:
stem_pool = nn.Sequential(*[
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
aa_layer(channels=num_init_features, stride=2)])
if deep_stem:
stem_chs_1 = stem_chs_2 = growth_rate
if 'tiered' in stem_type:
stem_chs_1 = 3 * (growth_rate // 4)
stem_chs_2 = num_init_features if 'narrow' in stem_type else 6 * (growth_rate // 4)
self.features = nn.Sequential(OrderedDict([
('conv0', nn.Conv2d(in_chans, stem_chs_1, 3, stride=2, padding=1, bias=False)),
('norm0', norm_layer(stem_chs_1)),
('conv1', nn.Conv2d(stem_chs_1, stem_chs_2, 3, stride=1, padding=1, bias=False)),
('norm1', norm_layer(stem_chs_2)),
('conv2', nn.Conv2d(stem_chs_2, num_init_features, 3, stride=1, padding=1, bias=False)),
('norm2', norm_layer(num_init_features)),
('pool0', stem_pool),
]))
else:
self.features = nn.Sequential(OrderedDict([
('conv0', nn.Conv2d(in_chans, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),
('norm0', norm_layer(num_init_features)),
('pool0', stem_pool),
]))
self.feature_info = [
dict(num_chs=num_init_features, reduction=2, module=f'features.norm{2 if deep_stem else 0}')]
current_stride = 4
# DenseBlocks
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = DenseBlock(
num_layers=num_layers,
num_input_features=num_features,
bn_size=bn_size,
growth_rate=growth_rate,
norm_layer=norm_layer,
drop_rate=drop_rate,
memory_efficient=memory_efficient
)
module_name = f'denseblock{(i + 1)}'
self.features.add_module(module_name, block)
num_features = num_features + num_layers * growth_rate
transition_aa_layer = None if aa_stem_only else aa_layer
if i != len(block_config) - 1:
self.feature_info += [
dict(num_chs=num_features, reduction=current_stride, module='features.' + module_name)]
current_stride *= 2
trans = DenseTransition(
num_input_features=num_features, num_output_features=num_features // 2,
norm_layer=norm_layer, aa_layer=transition_aa_layer)
self.features.add_module(f'transition{i + 1}', trans)
num_features = num_features // 2
# Final batch norm
self.features.add_module('norm5', norm_layer(num_features))
self.feature_info += [dict(num_chs=num_features, reduction=current_stride, module='features.norm5')]
self.num_features = num_features
# Linear layer
self.global_pool, self.classifier = create_classifier(
self.num_features, self.num_classes, pool_type=global_pool)
# Official init from torch repo.
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def get_classifier(self):
return self.classifier
def reset_classifier(self, num_classes, global_pool='avg'):
self.num_classes = num_classes
self.global_pool, self.classifier = create_classifier(
self.num_features, self.num_classes, pool_type=global_pool)
def forward_features(self, x):
return self.features(x)
def forward(self, x):
x = self.forward_features(x)
x = self.global_pool(x)
# both classifier and block drop?
# if self.drop_rate > 0.:
# x = F.dropout(x, p=self.drop_rate, training=self.training)
x = self.classifier(x)
return x
class DenseLayer(nn.Module):
def __init__(self, num_input_features, growth_rate, bn_size, norm_layer=BatchNormAct2d,
drop_rate=0., memory_efficient=False):
super(DenseLayer, self).__init__()
self.add_module('norm1', norm_layer(num_input_features)),
self.add_module('conv1', nn.Conv2d(
num_input_features, bn_size * growth_rate, kernel_size=1, stride=1, bias=False)),
self.add_module('norm2', norm_layer(bn_size * growth_rate)),
self.add_module('conv2', nn.Conv2d(
bn_size * growth_rate, growth_rate, kernel_size=3, stride=1, padding=1, bias=False)),
self.drop_rate = float(drop_rate)
self.memory_efficient = memory_efficient
def bottleneck_fn(self, xs):
# type: (List[torch.Tensor]) -> torch.Tensor
concated_features = torch.cat(xs, 1)
bottleneck_output = self.conv1(self.norm1(concated_features)) # noqa: T484
return bottleneck_output
# todo: rewrite when torchscript supports any
def any_requires_grad(self, x):
# type: (List[torch.Tensor]) -> bool
for tensor in x:
if tensor.requires_grad:
return True
return False
@torch.jit.unused # noqa: T484
def call_checkpoint_bottleneck(self, x):
# type: (List[torch.Tensor]) -> torch.Tensor
def closure(*xs):
return self.bottleneck_fn(xs)
return cp.checkpoint(closure, *x)
@torch.jit._overload_method # noqa: F811
def forward(self, x):
# type: (List[torch.Tensor]) -> (torch.Tensor)
pass
@torch.jit._overload_method # noqa: F811
def forward(self, x):
# type: (torch.Tensor) -> (torch.Tensor)
pass
# torchscript does not yet support *args, so we overload method
# allowing it to take either a List[Tensor] or single Tensor
def forward(self, x): # noqa: F811
if isinstance(x, torch.Tensor):
prev_features = [x]
else:
prev_features = x
if self.memory_efficient and self.any_requires_grad(prev_features):
if torch.jit.is_scripting():
raise Exception("Memory Efficient not supported in JIT")
bottleneck_output = self.call_checkpoint_bottleneck(prev_features)
else:
bottleneck_output = self.bottleneck_fn(prev_features)
new_features = self.conv2(self.norm2(bottleneck_output))
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return new_features
class DenseBlock(nn.ModuleDict):
_version = 2
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, norm_layer=nn.ReLU,
drop_rate=0., memory_efficient=False):
super(DenseBlock, self).__init__()
for i in range(num_layers):
layer = DenseLayer(
num_input_features + i * growth_rate,
growth_rate=growth_rate,
bn_size=bn_size,
norm_layer=norm_layer,
drop_rate=drop_rate,
memory_efficient=memory_efficient,
)
self.add_module('denselayer%d' % (i + 1), layer)
def forward(self, init_features):
features = [init_features]
for name, layer in self.items():
new_features = layer(features)
features.append(new_features)
return torch.cat(features, 1)
class DenseTransition(nn.Sequential):
def __init__(self, num_input_features, num_output_features, norm_layer=nn.BatchNorm2d, aa_layer=None):
super(DenseTransition, self).__init__()
self.add_module('norm', norm_layer(num_input_features))
self.add_module('conv', nn.Conv2d(
num_input_features, num_output_features, kernel_size=1, stride=1, bias=False))
if aa_layer is not None:
self.add_module('pool', aa_layer(num_output_features, stride=2))
else:
self.add_module('pool', nn.AvgPool2d(kernel_size=2, stride=2))
끝.
'논문리뷰' 카테고리의 다른 글
| [논문 리뷰] Vision Mamba(Vim) 요약, 코드, 구현 (0) | 2024.04.17 |
|---|---|
| [논문 리뷰] Swin Transformer 요약, 코드, 구현 (0) | 2024.04.09 |
| [논문 리뷰] MAE(Masked Autoencoders) 요약, 코드, 구현 (4) | 2023.10.12 |
| [논문 리뷰] SAM(Segment Anything) 요약, 코드, 구현 (6) | 2023.09.13 |
| [논문 리뷰] MLP mixer 요약, 코드, 구현 (0) | 2023.07.15 |



