논문을 상세히 번역하고 한단어씩 해석해주는 포스팅은 많다.
나는 논문을 누구나 알아듣도록 쉽고 간결하게 전달하고자 한다.
SAM(Segment Anything)
저자의 의도
NLP에는 GPT같은 패러다임을 바꾸는 혁신적인 모델이 있다.
그러나 CV에는 여전히 그런 모델이 등장하지 않고 있다.
CV의 Foundation Model을 디자인 해보자. (zero-shot transfer)
이 모델을 학습시키기 위한 초거대 segmentation dataset을 만들어보자.
기존 문제점
NLP의 거대한 capability는 prompt engineering으로 구현되는 편이다.
하지만 CV에는 다양한 문제점이 있고, 특히 풍부한 train dataset이 부족하다.
NLP와 CV는 확실히 다르다.
해결 아이디어
promptable 모델을 설계하여 광범위한 dataset으로 pre-training 하자.
promptable 모델 설계를 위해서 3가지 메인 구성요소 정의가 필요하다. (task, model, data)
3가지는 다음과 같이 정의된다.
- 충분히 보편적인 task
- flexible prompting을 지원하는 model
- 거대한 원천 data
1. Task
1.1. Task

NLP의 prompt 아이디어를 segmentation의 상황에 맞게 해석 하자.
NLP와 유사하게 어떤 prompt가 주어져도 valid한 segmentation mask를 리턴해야한다.
Valid란 prompt가 여러가지로 해석될 수 있더라도 output 중 1개는 반드시 타당해야 한다.
예를 들어, 위 그림에서 green point가 유저가 클릭한 곳이다.
이때 저 green point에 대한 의도, 답(output)은 (벽 전체, zurich, z) 세가지 정도로 유추할 수 있다.
이처럼 여러가지로 해석할 수 있지만 이 중에서 1개는 반드시 실제 유저의 의도와 일치해야 한다.
LLM이 다중의미의 prompt에도 일관성 있는 대답을 하는 것처럼,
SAM 모델도 일관된 답을 해야하기 때문에 이러한 task 정의가 필요하다.
이런 task가 자연스러운 pre-training 알고리즘으로 이끌고, downstream에 대하여 보편적으로 작용하게 한다.
1.2. Pre-training

Task를 정의했으니 pre-training하는 방법에 대하여 정의하자.
먼저, 각 샘플에 대하여 prompt의 시퀸스가 주어진다. (points, boxes, masks)
다음으로 prompt에 대한 모델의 예측 마스크와 ground truths 마스크를 비교한다.
이 방법을 interactive segmentation에 적용한다.
interactive segmentation는 사용자 클릭을 사용하여 CNN을 트레이닝 시키는 방법을 말한다.
즉 사람이 'green point'와 'red point'를 사용해서 특정 부분을 마스크가 맞다 아니다를 알려준다.
일단 여기서는 거시적으로 이렇게 pre-training 한다고 넘어가고
뒤에서 자세한 트레이닝 알고리즘이 소개된다.
1.3. Discussion
Prompting and composition은 모델이 확장하는 방법에 있어 매우 파워풀한 툴이다.
복합적인 시스템 설계가 더 다양한 downstream 작업을 가능하게 할 것으로 기대할 수 있다.
2. Model
2.1. Overview

아키텍쳐는 크게 3가지로 나눌 수 있다.
image encoder + flexible prompt encoder + fast mask decoder
2.2. Image encoder
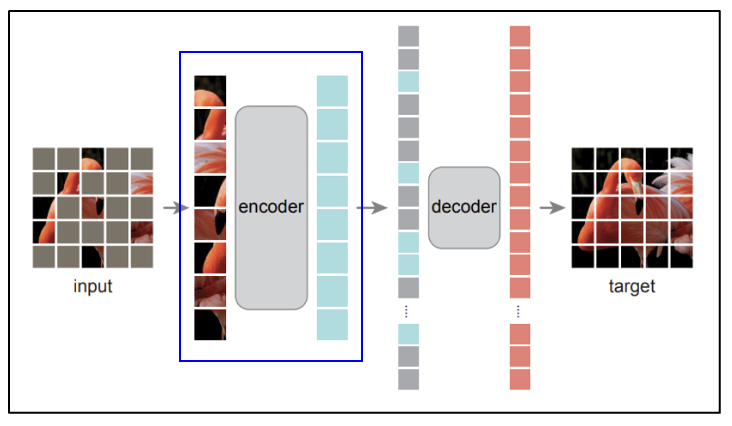
이미지에서 임베딩을 추출한다.
사용되는 인코더는 MAE로 프리 트레이닝된 ViT-H/16 이다.
MAE(Masked AutoEncoder)는 높은 scalability와 강력한 pre-training이 가능하게 해준다.
기존에 학습된 MAE에서 encoder 부분만 떼어서 image embedding을 만드는데 활용한다.

전체 SAM 아키텍쳐에서 봤을때 image encoder는 위 그림과 같이 image embedding을 만드는 부분이다.
인풋 이미지를 받아서 아웃풋 임베딩을 만드는 과정은 아래와 같다.
인풋 이미지 : (1024 * 1024) size * (16 * 16 * 3) channels
패치 사이즈 = 16이며, 채널에 (1x1 Conv) (3x3 Conv) (Norm) 진행한다.
아웃풋 임베딩 : (64 * 64) patches * 256 dimensions
2.3. Prompt encoder

프롬프트에서 임베딩을 추출한다.
프롬프트는 (sparse, dense) 2가지가 있다.
Sparse는 (점을 찍어서 명령하는 points, 박스를 그려 명령하는 boxes, 단어로 명령하는 text) 3가지가 있다.
Dense는 (직접 마스크를 제공하는 masks) 1가지가 있다.
모든 케이스는 기존에 있는 임베딩을 추출하는 기존의 알고리즘을 활용한다.
points, boxes는 positional encoding(해당 점의 위치 + 피사체와 배경을 구별하게 학습된 임베딩)를 추출
(논문명 : Fourier features let networks learn high frequency functions in low dimensional domains)
free-form text는 off-the-shelf text encoder로 추출
(CLIP 모델, 논문명 : Learning transferable visual models from natural language supervision)
masks는 보편적인 segmentation 메서드로 추출
convolution 레이어를 통과시켜 16배 작게 만들고 이미지 임베딩과 element-wise로 더함
2.4. Mask decoder

이미지 임베딩과 프롬프트 임베딩을 효율적으로 매핑해 아웃풋 마스크를 만든다.
총 2번의 디코딩(self-attn, cross-attn, MLP, corss-attn)이 이루어진다.
마스크 디코딩 되는 프로세스는 다음과 같으며, 그림과 같이 보면 도움이 된다.
0: 프롬프트 임베딩에 output token embedding을 부착한다. (클래스 토큰 개념)
그리고 지금부터 프롬프트 임베딩을 토큰이라 부른다.
1: self-attention 레이어를 통해 토큰에서 representation을 추출한다.
2: cross-attention 레이어를 통해 토큰(=Q)에서 이미지 임베딩(=K, V)을 사용해 representation을 추출한다. (토큰 like)
3: point-wise MLP가 토큰 즉 프롬프트를 각 토큰에 대해 차원 간 업데이트를 한다.
(GAP 레이어와 비슷한 역할이나 차원을 줄이진 않음. 더 복잡한 임베딩을 계산.)
4: cross-attention 레이어를 통해 이미지 임베딩(=Q)에서 토큰(=K, V)을 사용해 representation을 추출한다. (이미지 임베딩 like)
이걸 2번 반복한다.

5: 2개의 transposed Conv layer를 사용해서 이미지 임베딩을 4배로 키운다.
6-1: cross-attention 레이어를 통해 토큰(=Q)에서 이미지 임베딩(=K, V)을 사용해 representation을 추출한다. (토큰 like)
여기에 들어가는 토큰은 최종 크로스 어텐션 직전의 토큰이고, 이미지 임베딩은 최종 이미지 임베딩이다.
6-2: 6-1의 output을 small 3-layer MLP에 통과시킨다.
(업스케일링된 이미지 임베딩과 채널 디멘션 매칭을 위함)
7: 5의 결과와 6의 결과를 spatially point-wise product하여 최종 마스크를 예측한다.
(5는 업스케일링된 이미지 임베딩, 6은 dimension이 매칭된 토큰)
여기서 조금 애매한 용어 2가지가 있는데 실제 코드를 보면 다음과 같으니 참고하면 된다.


point-wise MLP는 리니어 2개로 구성되어 있어서 차원을 2048로 뻥튀기한 다음 다시 줄인다.
즉 256에서 찾지 못하는 복잡한 임베딩을 모든 노드를 한번 연결해줘서 업데이트 하는 것이다.
small 3-layer MLP는 디멘션을 줄이면서 사이즈를 늘리려는 의도다.
5에서 이미지 임베딩을 4배로 키웠기 때문에 사이즈를 매칭하려고 사용한다.
2.5. Ambiguity-aware

single input prompt는 이 상황에서 ambiguous를 일으킬 수 있다.
ambiguous의 의미는 prompt의 정확한 의도가 모호하여 일관적인 답을 못낼 가능성이 있다는 말이다.
저자들은 3개의 output tokens를 사용하여 multiple masks를 예측하게 했다. (Whole, part, subpart)
학습하는 동안에 3개의 loss를 항상 계산하되, backpropagation은 가장 낮은 loss로만 진행한다.
small head 1개가 masks의 랭킹을 계산한다.
각 마스크가 object를 얼마나 커버하는지 IoU를 계산한다.
2.6. Losses
focal loss와 dice loss에 weight를 줘서 20:1 비율로 더한다.
focal loss는 각 픽셀이 segmentation의 클래스를 맞췄는지 classification과 관련되어 있고,
dice loss는 segmentation의 영역이 overlaping된 양과 관련되어 있다.
2.7. Training algorithm
Interactive segmentation으로 셋업 되었다.
유저가 모델에 feedback을 주는 작업을 자동화 설계 했다.
용어로 사용하는 foreground는 피사체이고, background는 배경 영역이다.
1: 전체 이미지에서 랜덤하게 foreground point가 선택된다.
2: 모델이 첫 prompt(=point)에 대하여 mask를 예측한다.
3: error region에서 균일하게 후속 point가 선택된다.
4-1: 새 point가 foreground 위에 있으면 false negative 다.
4-2: 새 point가 background 위에 있으면 false positive 다.
5: 새 point가 1의 foreground point이며 이 작업을 자동으로 반복한다.
3. Data
학습에 사용될 데이터(이미지, 레이블 마스크)를 만드는 데이터 엔진이 구동된다.
3가지 스테이지의 데이터 엔진이 구동되며, 최종 목표는 완전 자동화된 데이터 엔진이다.
3.1. Assisted-manual stage

Annotator들은 foreground/background 포인트 클릭을 통해 마스크를 레이블링 한다.
SAM로 구동되는 브라우저 형태의 툴을 사용할 수 있다. 마스크를 브러쉬와 지우개 툴으로 더 섬세하게 보정한다.
SAM은 해당 컨셉으로 6번 학습된다.
3.2. Semi-automatic stage

마스크의 다양성을 향상시키기 위해 반자동으로 구동하는 스테이지.
모델은 자동으로 confident 마스크를 감지하고 마스크 밑작업을 한다.
Annotator들은 결과를 보고 추가로 마스크를 칠한다.
3.3. Fully automatic stage

데이터셋의 양을 폭발적으로 늘리기 위해 완전 자동화한다.
이를 위해서 2가지 주요 성능향상이 필요하다.
- 충분한 양의 마스크 -> 모델이 valid mask를 예측할 수 있게 한다.
- 모호성 인지(ambiguity-aware) -> 모델이 mask 세트(서브파트, 파트, 전체)를 예측할 수 있게 한다.
이미지에 32x32개의 포인트를 뿌리고 각 포인트에 대한 마스크를 모델이 예측하도록 한다.
IoU 모듈이 마스크의 confident와 stable을 계산한다.
NMS를 이용해 중복된 마스크를 제거한다.
4. Zero-Shot Transfer Experiments
총 6가지 종류의 downstream을 zero-shot으로 실험했다.
(작업 설명, 알고리즘 설명, 기존 모델과 비교)
4.1. Single point segmentation

모델과 동일한 작업
모델과 동일한 알고리즘
기존의 모델(RITM)보다 좋은 성능
4.2. Edge detection

경계선 검출
16x16개의 포인트 -> 포인트에 대한 마스크 예측 -> NMS -> Sobel
기존의 모델(EDETR)보다 약간 낮은 성능
4.3. Object proposals

가능성이 높은 일부 객체의 위치 제안
1000개 이상의 마스크 생성 -> IoU와 stability를 기준으로 선택
기존의 모델(ViTDet-H)과 유사한 성능
4.4. Instance segmentation

object detection 후 해당 object를 segmentation
ViTDet로 object detection -> box를 prompt로 SAM 구동
기존의 모델(ViTDet-H)보다 약간 낮은 성능
4.5. Text-to-mask

텍스트를 입력하면 해당 텍스트의 객체를 segmentation
CLIP으로 text 임베딩 생성 -> text를 prompt로 SAM 구동
기존 모델 없음
4.6. Ablations(생략)
(생략)
논문 구현
(일부 발췌)
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
import torch
from torch import nn
from torch.nn import functional as F
from typing import Any, Dict, List, Tuple
from .image_encoder import ImageEncoderViT
from .mask_decoder import MaskDecoder
from .prompt_encoder import PromptEncoder
class Sam(nn.Module):
mask_threshold: float = 0.0
image_format: str = "RGB"
def __init__(
self,
image_encoder: ImageEncoderViT,
prompt_encoder: PromptEncoder,
mask_decoder: MaskDecoder,
pixel_mean: List[float] = [123.675, 116.28, 103.53],
pixel_std: List[float] = [58.395, 57.12, 57.375],
) -> None:
"""
SAM predicts object masks from an image and input prompts.
Arguments:
image_encoder (ImageEncoderViT): The backbone used to encode the
image into image embeddings that allow for efficient mask prediction.
prompt_encoder (PromptEncoder): Encodes various types of input prompts.
mask_decoder (MaskDecoder): Predicts masks from the image embeddings
and encoded prompts.
pixel_mean (list(float)): Mean values for normalizing pixels in the input image.
pixel_std (list(float)): Std values for normalizing pixels in the input image.
"""
super().__init__()
self.image_encoder = image_encoder
self.prompt_encoder = prompt_encoder
self.mask_decoder = mask_decoder
self.register_buffer("pixel_mean", torch.Tensor(pixel_mean).view(-1, 1, 1), False)
self.register_buffer("pixel_std", torch.Tensor(pixel_std).view(-1, 1, 1), False)
@property
def device(self) -> Any:
return self.pixel_mean.device
@torch.no_grad()
def forward(
self,
batched_input: List[Dict[str, Any]],
multimask_output: bool,
) -> List[Dict[str, torch.Tensor]]:
"""
Predicts masks end-to-end from provided images and prompts.
If prompts are not known in advance, using SamPredictor is
recommended over calling the model directly.
Arguments:
batched_input (list(dict)): A list over input images, each a
dictionary with the following keys. A prompt key can be
excluded if it is not present.
'image': The image as a torch tensor in 3xHxW format,
already transformed for input to the model.
'original_size': (tuple(int, int)) The original size of
the image before transformation, as (H, W).
'point_coords': (torch.Tensor) Batched point prompts for
this image, with shape BxNx2. Already transformed to the
input frame of the model.
'point_labels': (torch.Tensor) Batched labels for point prompts,
with shape BxN.
'boxes': (torch.Tensor) Batched box inputs, with shape Bx4.
Already transformed to the input frame of the model.
'mask_inputs': (torch.Tensor) Batched mask inputs to the model,
in the form Bx1xHxW.
multimask_output (bool): Whether the model should predict multiple
disambiguating masks, or return a single mask.
Returns:
(list(dict)): A list over input images, where each element is
as dictionary with the following keys.
'masks': (torch.Tensor) Batched binary mask predictions,
with shape BxCxHxW, where B is the number of input prompts,
C is determined by multimask_output, and (H, W) is the
original size of the image.
'iou_predictions': (torch.Tensor) The model's predictions
of mask quality, in shape BxC.
'low_res_logits': (torch.Tensor) Low resolution logits with
shape BxCxHxW, where H=W=256. Can be passed as mask input
to subsequent iterations of prediction.
"""
input_images = torch.stack([self.preprocess(x["image"]) for x in batched_input], dim=0)
image_embeddings = self.image_encoder(input_images)
outputs = []
for image_record, curr_embedding in zip(batched_input, image_embeddings):
if "point_coords" in image_record:
points = (image_record["point_coords"], image_record["point_labels"])
else:
points = None
sparse_embeddings, dense_embeddings = self.prompt_encoder(
points=points,
boxes=image_record.get("boxes", None),
masks=image_record.get("mask_inputs", None),
)
low_res_masks, iou_predictions = self.mask_decoder(
image_embeddings=curr_embedding.unsqueeze(0),
image_pe=self.prompt_encoder.get_dense_pe(),
sparse_prompt_embeddings=sparse_embeddings,
dense_prompt_embeddings=dense_embeddings,
multimask_output=multimask_output,
)
masks = self.postprocess_masks(
low_res_masks,
input_size=image_record["image"].shape[-2:],
original_size=image_record["original_size"],
)
masks = masks > self.mask_threshold
outputs.append(
{
"masks": masks,
"iou_predictions": iou_predictions,
"low_res_logits": low_res_masks,
}
)
return outputs
def postprocess_masks(
self,
masks: torch.Tensor,
input_size: Tuple[int, ...],
original_size: Tuple[int, ...],
) -> torch.Tensor:
"""
Remove padding and upscale masks to the original image size.
Arguments:
masks (torch.Tensor): Batched masks from the mask_decoder,
in BxCxHxW format.
input_size (tuple(int, int)): The size of the image input to the
model, in (H, W) format. Used to remove padding.
original_size (tuple(int, int)): The original size of the image
before resizing for input to the model, in (H, W) format.
Returns:
(torch.Tensor): Batched masks in BxCxHxW format, where (H, W)
is given by original_size.
"""
masks = F.interpolate(
masks,
(self.image_encoder.img_size, self.image_encoder.img_size),
mode="bilinear",
align_corners=False,
)
masks = masks[..., : input_size[0], : input_size[1]]
masks = F.interpolate(masks, original_size, mode="bilinear", align_corners=False)
return masks
def preprocess(self, x: torch.Tensor) -> torch.Tensor:
"""Normalize pixel values and pad to a square input."""
# Normalize colors
x = (x - self.pixel_mean) / self.pixel_std
# Pad
h, w = x.shape[-2:]
padh = self.image_encoder.img_size - h
padw = self.image_encoder.img_size - w
x = F.pad(x, (0, padw, 0, padh))
return x
'논문리뷰' 카테고리의 다른 글
| [논문 리뷰] DenseNet 요약, 코드, 구현 (0) | 2024.04.05 |
|---|---|
| [논문 리뷰] MAE(Masked Autoencoders) 요약, 코드, 구현 (4) | 2023.10.12 |
| [논문 리뷰] MLP mixer 요약, 코드, 구현 (0) | 2023.07.15 |
| [논문 구현] ViT ImageNet 학습하는 방법 (0) | 2023.06.08 |
| [논문 구현] ImageNet-21k 데이터셋 pre-training 방법 (2) | 2023.06.08 |



