논문을 상세히 번역하고 한단어씩 해석해주는 포스팅은 많다.
나는 논문을 누구나 알아듣도록 쉽고 간결하게 전달하고자 한다.
CoAtNet
저자의 의도
효율적으로 CNN과 Self-attention의 장점만 결합해보자.
Depth-wise Conv와 relative attention을 활용하면 두 구조를 합칠 수 있다.
generalization, capacity, efficiency 3가지를 향상 시키자.
JFT와 같은 추가적인 데이터셋 없이 SOTA 퍼포먼스를 달성해보자.
기존 문제점
ViT의 퍼포먼스는 작은 데이터셋에서 CNN을 넘지 못한다.
ViT의 초강력 퍼포먼스는 대부분 추가 데이터셋이 필요하다.
트랜스포머 특성상 pre-training이 동반되어야만 하기 때문이다.
바닐라 ViT는 여전히 유용한 inductive bias가 부족하다고 봤다.
NLP를 위해 설계된 모델이라 여전히 CV를 처리하기에는 부족한 것이다.
저자는 CNN과 비교 분석을 통해 이런 inductive bias를 주입시켰다.
배경 지식
논문에서 Conv 레이어로는 MobileNet-v2의 Depth-wise separabale Conv 레이어를 사용했고,
Self-attention 레이어로는 Relative attention레이어를 사용했다.
따라서 두가지 개념을 먼저 간단하게 이해하고 넘어가자.
1. MobileNet-v2

Depth-wise separable Conv레이어는 기존 Conv레이어를 2번에 나눠서 진행한다.
(3D -> 1D) 대신에 (2D -> 1D, 2D -> 1D)을 하는 것이다.
이렇게 하는 이유는 빠르고 효율적이기 때문이다. (약 1/9의 계산량 절약)
? 전혀 이해가 안될거다. 나도 그랬다. 이건 수식을 풀어서 계산해봐야만 보인다.
간단하게 1개 차원을 줄이는 것이 2개 차원을 줄이는 것보다 빠르다고 이해하고 넘어가자.
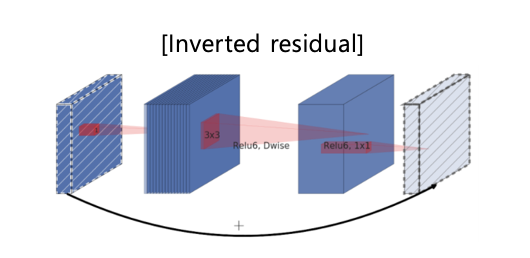
논문이 이 블럭을 사용한 가장 중요한 이유는 Inverted residual 형태이기 때문이다.
Residual은 wide -> narrow -> wide 과정에서 wide를 연결하고,
Inverted residual은 narrow -> wide -> narrow 과정에서 narrow를 연결한다.
이 인버티드 구조는 어탠션 레이어가 동작하는 것과 매우 유사하다.
어탠션 레이어도 임베딩을 만들면 차원이 늘어나 wide하게 만들기 때문이다.
1. Relative attention

Relative attention은 진짜 별거 아니다. 공식보고 쫄지 말자.
standard attention은 시퀀스 내에서 토큰 사이의 거리를 고려하지 않고 같은 웨이트를 부여한다.
relative attention은 시퀀스 내에서 토큰 사이의 거리가 가까우면 더 큰 웨이트를 부여한다.
그림을 보면 각 토큰 사이마다 relative distance인 a가 따로 있고 어탠션 스코어 계산에서 활용된다.
자 이제 다시 논문으로 돌아가자.
해결 아이디어
일단 가장 큰 개념은 이 두가지다.
Conv 레이어는 generalization이 더 빠르게 되는 특징이 있다.
어탠션 레이어는 capacity가 높아서 더 많은 dataset에서 유리한 특징이 있다.
따라서 generalization, capacity 2가지를 중점으로 생각하자.
1. 3가지 특징 분석
1. Input-adaptive weighting
self-attention 레이어는 서로 멀리 떨어진 위치에 있더라도 복잡한 관계를 잘 캐치한다.
트랜스포머의 가장 큰 특징은 전체의 맥락(context)를 읽을 수 있는 것이다.
CNN과 달리 위치가 멀리 있어도 그 관계를 파악할 수 있으며 복잡한 관계라도 상관없다.
이 특징은 높은 수준의 개념을 처리하는데 가장 필요한 특징이다.
2. Translation equivariance
Conv 레이어의 weight는 주어진 포지션 사이의 '상대적인 거리'를 주로 고려한다.
배경지식에서 말한 것처럼 self-attention(standard attention)은 토큰 사이의 거리에 가중치가 없다.
물론 ViT에서는 포지셔널 임베딩을 통해 위치가 다른 것을 구현하지만,
이게 '상대적인 거리'를 고려하는 것은 아니다. (심지어 sinusoidal한 함수를 활용)
반면에 Conv 레이어는 기본적으로 포지션 사이의 상대적인 거리를 고려한다.
이 특징은 크지 않은 데이터셋에 빠른 속도로 generalizaiton하는데 핵심 특징이다.
3. Global receptive field
self-attention 레이어는 글로벌 사이즈의 receptive field를 가진다.
receptive field는 레이어가 수용하는 크기다. 고려할 수 있는 최대 사이즈의 크기인 것.
CNN은 (3x3)사이즈로 주변의 픽셀을 탐색하고 이걸 쌓기 때문에 receptive field의 한계가 있다.
반면에 self-attention은 이미지의 전체를 보고 판단한다.
이 특징은 더 맥락적인 정보(contextual information)를 제공받고 큰 capacity를 갖는 핵심 특징이다.
2. Conv와 Self-attention의 결합
배경지식에서 말한 두가지 레이어를 통해 결합했다.
인버티드 보틀넥 구조를 사용하기 위해 MBConv(MobileNet Conv) 블럭을 사용했다.
상대적인 거리를 고려하기 위해 relative attention을 사용했다.
(여기서 갑자기 포지셔널 임베딩이 등장하면 결합하는데 복잡하기 때문)
위에서 분석한 3가지 특징을 모두 커버하는 모델을 수립하기 위해 노력했다.
3. Architecture
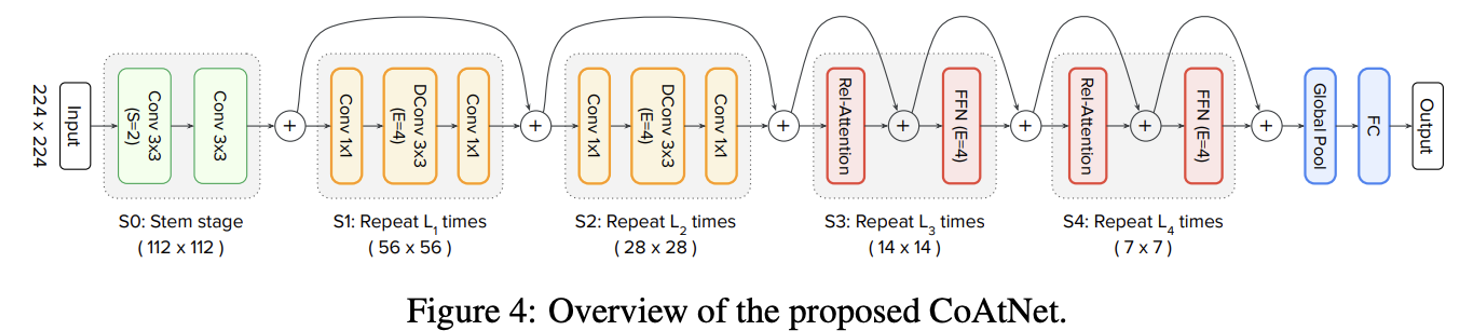
다운 샘플링을 통해 spatial size를 줄이고, 그 상태로 global relative attention을 진행하는 큰그림.
spatial size는 공간적 사이즈로 쉽게 가로세로 크기라고 생각하면 된다.
이게 줄어들면 당연하게 다른 차원 (3번째 차원인 깊이)가 늘어나게 될거다.
S0 : stem stage, (3x3) 커널을 사용해 spatial size를 절반으로 줄인다.
S1 : Always MBConv block, Conv 블럭이 앞쪽 스테이지에 있는 것이 퍼포먼스에 유리하다. (실험적 결과)
S2~S4 : (MBConv block) or (relative attention block)
이렇게 구성해서 총 4가지의 모델이 나온다. (CCCC, CCCT, CCTT, CTTT)
(C는 MBConv block, Conv 줄임말 / T는 relative attention block, Transformer 줄임말)
4. Generalization 분석

generalization 평가에서는 𝐶𝐶𝐶𝐶 ≈𝐶𝐶𝐶𝑇 ≥𝐶𝐶𝑇𝑇 >𝐶𝑇𝑇𝑇 ≫〖𝑉𝑖𝑇〗_𝑅𝐸𝐿 의 결과가 나왔다.
이는 예상한 결과와 일치한다. Conv 레이어의 특징이 generalization이 빠르게 되는 것 이었다.
예상한대로 Conv 레이어가 많을수록 generalization이 빠르게 잘 된다.
5. Model Capacity

Model capacity 평가에서는 𝐶𝐶𝑇𝑇 ≈𝐶𝑇𝑇𝑇 >〖 𝑉𝑖𝑇〗_𝑅𝐸𝐿>𝐶𝐶𝐶𝑇>𝐶𝐶𝐶𝐶 의 결과가 나왔다.
특이하게 attention 레이어가 많다고 capacity가 반드시 높은 것은 아니다.
저자는 stem stage에서 ViT가 너무 많은 정보 손실을 당하고, capacity가 오히려 제한된다고 해석했다.
6. Transferability Test (CCTT vs CTTT)

트랜스포머에서 few shot transfer라는 개념이 있다.
pre-training한 뒤에 적은 횟수의 fine-tuning으로 새로운 데이터셋에 generalization하는 것이다.
저자는 JFT에서 pre-training하고, ImageNet-1K에서 30 에포크로 fine-tuning 테스트를 했다.
이 테스트에서 CCTT가 CTTT보다 더 좋은 성능을 발휘했다. (당연하다)
따라서 최종적으로 CoAtNet의 구조를 CCTT로 확정했다.
실험 결과

실험결과 ImageNet-21K로 pre-training 했는데,
초거대 데이터셋 JFT으로 pre-training한 모델들과 견줄 정도의 높은 퍼포먼스가 나왔다.
이 모델의 핵심은 '작은 데이터셋' 에서도 높은 퍼포먼스를 보인다는 것이다.
관련 논문 리스트 (스크롤 내려서 Paper List 참고)
끝.
'논문리뷰' 카테고리의 다른 글
| [논문 구현] ImageNet 다운로드 및 학습하는 방법 (0) | 2023.06.08 |
|---|---|
| [논문 구현] ImageNet-21k 데이터셋 다운로드 및 pre-training 방법, 이미지넷 데이터셋 다운로드 및 사전학습 방법 (2) | 2023.06.08 |
| [논문 리뷰] ViT Robustness 요약, 코드, 구현 (1) | 2023.05.08 |
| [논문 리뷰] ViT-G/14 요약, 코드, 구현 (0) | 2023.04.10 |
| [논문 구현] ImageNet 다운로드 방법, ViT 체크포인트 평가 방법, 이미지넷 다운로드 방법, ViT 체크포인트 평가 방법 (0) | 2023.03.28 |



