ImageNet 다운로드
먼저 ImageNet 데이터셋을 받아야 한다.
(이게 진짜 킹받는다 ^^)
ImageNet 오피셜 홈페이지
https://image-net.org/download-images
ImageNet
Download ImageNet Data ImageNet does not own the copyright of the images. For researchers and educators who wish to use the images for non-commercial research and/or educational purposes, we can provide access through our site under certain conditions and
image-net.org
선수입장
회원가입
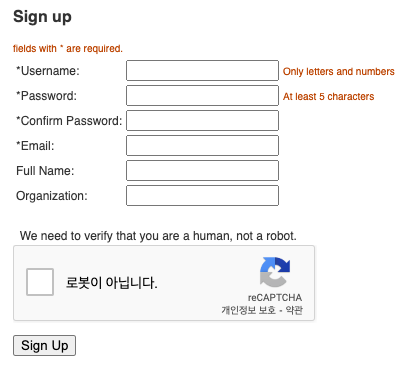
이메일은 학교메일(마지막에 ac.kr로 끝나는거) 권장한다.
별표 없는 것도 다 채워야한다.
신청버튼이 나오면 클릭하고, 메일가서 인증한다.
이제 다운가능.

여기서 제일 밑에 Validation Images 받으면 된다.
다운로드한 파일(tar 확장자)을 ./data/ImageNet/ 폴더에 넣는다.
./data/ImageNet/ 폴더에서 터미널을 켠다.
mkdir val && mv ILSVRC2012_img_val.tar val/ && cd val && tar -xvf ILSVRC2012_img_val.tar
wget -qO- https://raw.githubusercontent.com/soumith/imagenetloader.torch/master/valprep.sh | bash입력하면 압축 알아서 풀리고 val 폴더가 생긴다.
tar 확장자 파일은 지워도 된다.
아래는 train 이미지 푸는 코드.
mkdir train && mv ILSVRC2012_img_train.tar train/ && cd train
tar -xvf ILSVRC2012_img_train.tar && rm -f ILSVRC2012_img_train.tar
find . -name "*.tar" | while read NAME ; do mkdir -p "${NAME%.tar}"; tar -xvf "${NAME}" -C "${NAME%.tar}"; rm -f "${NAME}"; done
cd ..
ViT 체크포인트 평가
ViT는 트랜스포머 중에서 그나마 간단한 형태이다.
실제로 구현하는게 그리 어렵지는 않다.
하지만..........
논문에서 '대용량 pre-training'이 안된 ViT는 퍼포먼스가 상당히 떨어진다고 나온다.
다시 말해서 학습하는데 시간도 오래 걸리고 귀찮다.................................
사전학습된 체크포인트를 쓰고싶은데.... 라는 생각이 든다.
다행히 나만 귀찮은게 아니라 천조국 형들도 귀찮았나 보다.
누군가 이미 라이브러리로 만들어놨다.

이걸로 모델을 만들어보자.
일단 설치
pip install timm
그리고 OOP로 작성된 코드는 다음과 같다.
(device는 맥북이면 mps, 윈도우면 cuda)
import timm
import torch
import torchvision
import torch.utils.data as data
import torchvision.transforms as transforms
device = 'mps'
# device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
BATCH_SIZE = 100
NUM_WORKERS = 2
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
test_set = torchvision.datasets.ImageFolder('./data/ImageNet/val', transform=transform)
test_loader = data.DataLoader(test_set, batch_size=BATCH_SIZE, shuffle=True, num_workers=NUM_WORKERS)
class ViTImageNet21k(object):
def __init__(self):
self.model = None
def process(self):
self.build_modeL()
self.eval_model()
def build_modeL(self):
self.model = timm.models.vit_base_patch16_224(pretrained=True).to(device)
# self.model = timm.models.vit_large_patch16_224(pretrained=True).to(device)
print(f'Parameter : {sum(p.numel() for p in self.model.parameters() if p.requires_grad)}')
def eval_model(self):
model = self.model
model.to(device).eval()
correct_top1 = 0
correct_top5 = 0
total = 0
with torch.no_grad():
for idx, (images, labels) in enumerate(test_loader):
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, pred = torch.max(outputs, 1)
total += labels.size(0)
correct_top1 += (pred == labels).sum().item()
_, rank5 = outputs.topk(5, 1, True, True)
rank5 = rank5.t()
correct = rank5.eq(labels.view(1, -1).expand_as(rank5))
for k in range(6):
correct_k = correct[:k].reshape(-1).float().sum(0, keepdim=True)
correct_top5 += correct_k.item()
print(f"Step : {idx + 1} / {int(len(test_set) / int(labels.size(0)))}")
print(f"top-1 Accuracy : {correct_top1 / total * 100:0.2f}%")
print(f"top-5 Accuracy : {correct_top5 / total * 100:0.2f}%")
print(f"top-1 Accuracy : {correct_top1 / total * 100:0.2f}%")
print(f"top-5 Accuracy : {correct_top5 / total * 100:0.2f}%")
if __name__ == "__main__":
ViTImageNet21k().process()
이제 위에 코드 실행하면 돌아간다.
배치(100개 이미지)에 대하여 정확도가 나오는 것을 확인할 수 있다.

논문에서 Top-1 : 84.44%, Top-5 : 97.25 가 나온다고 되어 있다.
50000개를 다 돌리면 그쯤 나올거 같다.
끝.
'논문리뷰' 카테고리의 다른 글
| [논문 리뷰] ViT Robustness 요약, 코드, 구현 (1) | 2023.05.08 |
|---|---|
| [논문 리뷰] ViT-G/14 요약, 코드, 구현 (0) | 2023.04.10 |
| [논문 리뷰] Vision Transformer(ViT) 요약, 코드, 구현 (0) | 2023.03.22 |
| [논문 리뷰] UNet 요약, 코드, 구현 (0) | 2023.03.20 |
| [논문 리뷰] Inception v1 요약, 코드, 구현 (0) | 2023.03.16 |



