논문을 상세히 번역하고 한단어씩 해석해주는 포스팅은 많다.
나는 논문을 누구나 알아듣도록 쉽고 간결하게 전달하고자 한다.
ViT
AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
ViT를 보기 전에 standard transformer를 이해하길 바란다.
Transformer 논문 리뷰, 논문 원문, 논문 요약, 논문 구현, Attention Is All You Need
논문을 번역하고 자세히 한단어씩 해석해주는 포스팅은 널리고 널렸다. 나는 논문을 쉽고 간결하게 전달하고자 한다. Transformer Attention Is All You Need VASWANI, Ashish, et al. Attention is all you need. Advances i
davidlds.tistory.com
저자의 의도
CNN arhitecture에 의존하지 않는 pure transformer로 이미지 분류를 해보자.
기존 문제점
이미지 분류 문제에서 transformer는 CNN을 넘어서지 못했다.
NLP는 잘만 되는데 CV는 안된다.
특히 generalize가 안되는데 이 문제가 가장 심각하다.
해결 아이디어
1. Patch

큰 이미지를 작은 패치로 쪼개서 인풋 시퀀스의 토큰으로 생각하고 사용한다.
(H, W, C) -> N * (P, P, C) 하는 것. 위 그림에서는 N = 9 이다.
그다음 패치를 flatten하여 2D를 1D로 펼쳐준다.
2D self attention은 memory expensive하여 비효율적이기 때문이다.
2. Embedding

learnable embedding과 position embedding 2가지를 임베딩 한다.
learnable embedding
위 그림에 * 표시가 된 걸 달아주는 작업이다. BERT의 기법과 동일하다.
[class] embedding token 이라는 것인데, 패치 시퀀스 가장 앞에 달아준다.
이 토큰은 클래스 길이의 벡터로, 랜덤숫자로 시작해서 학습하며 업데이트된다.
position embedding
스탠다드 트랜스포머와 같은 방식으로 임베딩 해준다.
대신 [class] embedding token이 앞에 붙었기 때문에
패치의 갯수 + 1개의 포지션인 점을 기억하자.
3. MLP Head

마지막 classification 하는 부분은 MLP Head가 처리한다.
MLP Head는 FC layer 2개와 softmax layer 1개로 구성된다.
representation vector만 이용해서 classification을 한다.
이때 representation vector는 임베딩에서 나온 [class] embedding token만 사용한다.
학습하는 과정에서 모든 패치들의 정보가 이 토큰에도 반영되기 때문에 이것만 써도 된다.
4. Inductive Bias
inductive bias 개념은 모델의 특화 성향이다.
트랜스포머는 RNN처럼 NLP에 특화된 모델이다.
CV에 대한 inductive bias를 추가로 부여할 필요가 있다.
CV 작업을 위해서는 '픽셀 간 상호작용'을 이해해야한다.
근데 픽셀 하나하나를 냅다 넣는게 아니라,
패치 단위로 쪼개서 넣으면 상호작용을 이해할 수 있게 된다.
그래서 ViT가 큰 이미지를 작은 패치의 시퀀스로 보도록 설계한 것이다.
5. Self-Supervised Pre-Training
GPT나 BERT에서 사용하는 pre-training을 차용한다.
비지도학습으로 레이블이 없는 대용량 데이터셋에서 복합적인 '특징 추출법'만 학습힌다.
실전에서도 이 특징 추출법을 사용하도록 유도하는 것인데,
실전 데이터도 레이블이 없으니 이 방법이 매우 효과적이다.
반드시 '대용량' 데이터셋에서 진행을 해야 성능이 향상된다.
6. Hybrid Architecture
논문은 raw image가 아니라 CNN 피쳐맵으로 패치를 쪼개 넣는 것도 소개한다.
2가지(트랜스포머 + CNN)가 하이브리드 된 것으로 장점만 취하려는 의도다.
추가 고찰
이 논문은 3대 거장의 논문처럼 양질의 실험 데이터와 내부 자료를 공유한다.
다음 자료는 한번씩 보고 가는걸 추천.

어텐션의 representation 예시. input space로 복원한 것.

임베딩된 패치 중에 분산이 가장 높은 28개의 필터를 RGB로 복원한 것.
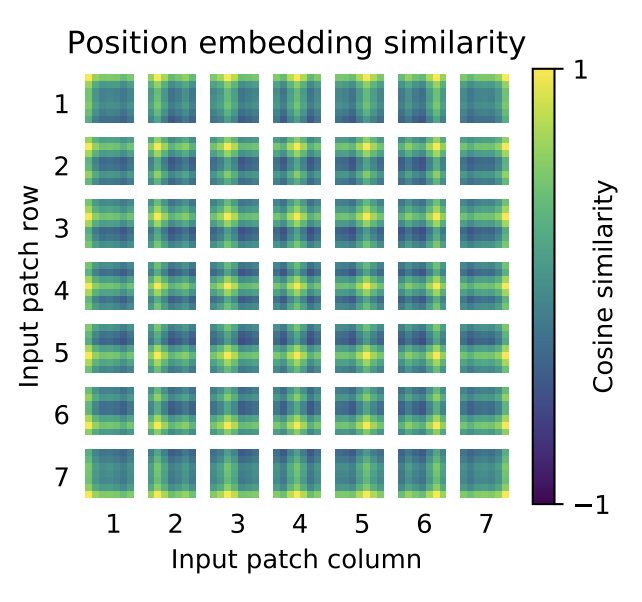
포지션 임베딩을 시각화 한 것.
1D로 포지션 임베딩을 했는데....
2D 입장에서도 겹치는 값도 없고 편차도 크지 않다.
논문 구현
import torch
import torch.nn as nn
import torch.nn.functional as F
'''
image_size: 이미지의 크기
patch_size: 이미지를 패치로 나눌 크기
in_channels: 입력 이미지의 채널 수
num_classes: 분류해야 하는 클래스 수
embed_dim: 패치 임베딩의 차원
depth: 인코더 블록의 수
num_heads: 멀티 헤드 어텐션의 헤드 수
mlp_ratio: MLP 모듈에서 첫 번째 FC 레이어와 두 번째 FC 레이어의 차원 비율 (기본값은 4.0)
qkv_bias: 어텐션의 행렬 연산에서 Q, K, V 행렬에 대한 바이어스 사용 여부 (기본값은 False)
attn_drop: 어텐션 드롭아웃 비율 (기본값은 0.0)
proj_drop: 어텐션 이후 프로젝션 드롭아웃 비율 (기본값은 0.0)
'''
class PatchEmbedding(nn.Module):
def __init__(self, image_size, patch_size, in_channels, embed_dim):
super(PatchEmbedding, self).__init__()
self.image_size = image_size
self.patch_size = patch_size
self.in_channels = in_channels
self.embed_dim = embed_dim
self.num_patches = (image_size // patch_size) ** 2
self.projection = nn.Conv2d(
in_channels=in_channels,
out_channels=embed_dim,
kernel_size=patch_size,
stride=patch_size
)
def forward(self, x):
x = self.projection(x)
x = x.flatten(2)
x = x.transpose(1, 2)
return x
class MLP(nn.Module):
def __init__(self, in_features, hidden_features, out_features, mlp_drop=0.):
super().__init__()
self.fc1 = nn.Linear(in_features, hidden_features)
self.fc2 = nn.Linear(hidden_features, out_features)
self.dropout = nn.Dropout(mlp_drop)
def forward(self, x):
x = self.fc1(x)
x = F.gelu(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.dropout(x)
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads, qkv_bias=False, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
x = (q @ k.transpose(-2, -1)) * self.scale
x = x.softmax(dim=-1)
x = self.attn_drop(x)
x = (x @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class EncoderBlock(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4.0, qkv_bias=False, attn_drop=0.0, proj_drop=0.0):
super().__init__()
self.norm1 = nn.LayerNorm(dim)
self.norm2 = nn.LayerNorm(dim)
self.attn = Attention(dim=dim, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=proj_drop)
self.mlp = MLP(in_features=dim, hidden_features=int(dim * mlp_ratio), out_features=dim)
def forward(self, x):
x = x + self.attn(self.norm1(x))
x = x + self.mlp(self.norm2(x))
return x
class MLPHead(nn.Module):
def __init__(self, embed_dim, mlp_hidden_dim, num_classes):
super(MLPHead, self).__init__()
self.embed_dim = embed_dim
self.mlp_hidden_dim = mlp_hidden_dim
self.num_classes = num_classes
self.fc1 = nn.Linear(embed_dim, mlp_hidden_dim)
self.fc2 = nn.Linear(mlp_hidden_dim, mlp_hidden_dim)
self.fc3 = nn.Linear(mlp_hidden_dim, num_classes)
self.activation = nn.GELU()
self.dropout = nn.Dropout(0.1)
def forward(self, x):
x = self.fc1(x)
x = self.activation(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.activation(x)
x = self.dropout(x)
x = self.fc3(x)
return x
class ViT(nn.Module):
def __init__(self, image_size, patch_size, in_channels, num_classes, embed_dim, depth, num_heads, mlp_ratio=4.0, qkv_bias=False, attn_drop=0.0, proj_drop=0.0):
super().__init__()
self.patch_embed = PatchEmbedding(image_size=image_size, patch_size=patch_size, in_channels=in_channels, embed_dim=embed_dim)
self.num_patches = self.patch_embed.num_patches
self.cls_token = nn.Parameter(torch.randn(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.randn(1, self.num_patches + 1, embed_dim))
self.pos_drop = nn.Dropout(p=proj_drop)
self.encoder_blocks = nn.ModuleList([
EncoderBlock(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=proj_drop)
for _ in range(depth)
])
self.mlp_head = MLPHead(embed_dim=embed_dim, mlp_hidden_dim=embed_dim * 4, num_classes=num_classes)
def forward(self, x):
x = self.patch_embed(x)
cls_token = self.cls_token.expand(x.shape[0], -1, -1)
x = torch.cat((cls_token, x), dim=1)
x = x + self.pos_embed
x = self.pos_drop(x)
for encoder_block in self.encoder_blocks:
x = encoder_block(x)
x = x[:, 0]
x = self.mlp_head(x)
return x패치 임베딩, 인코더블럭, MLP 헤드 3가지를 구현하면 된다.
인코더 블럭은 기존의 트랜스포머 인코더에서 마지막 레이어만 MLP로 바꿔주면 된다.
MLP의 구성은 논문에도 나와 있는데, 간단히 FC 레이어 2개로 구성되어 있다.
MLP 헤드는 잘 몰라서 찾아봤는데 3개 레이어로 구성하면 된다.
끝.
'논문리뷰' 카테고리의 다른 글
| [논문 리뷰] ViT-G/14 요약, 코드, 구현 (0) | 2023.04.10 |
|---|---|
| [논문 구현] ViT ImageNet 평가 방법 (0) | 2023.03.28 |
| [논문 리뷰] UNet 요약, 코드, 구현 (0) | 2023.03.20 |
| [논문 리뷰] Inception v1 요약, 코드, 구현 (0) | 2023.03.16 |
| [논문 리뷰] VGGNet 요약, 코드, 구현 (0) | 2023.03.15 |



