처음 대학원에 가거나 연구 직무를 맡으면 답답한 점이 있다.
뭘 어디서부터 어떻게 찾고 뭘 어떻게 공부해야하지?
진짜 눈앞이 막막하다.
선배들에게 물어보면 그 뭐 그냥 대충 논문 찾아서 읽으면 된다고 한다.
그... 그러면.... 논문을 어떻게 찾는데요...? ㅎㅁㅎ?

이 글에서는 논문 탐색 로드맵을 알려주고자 한다.
물론 이 방법에는 정답이 없다.
내가 제시하는 방법이 마스터 알고리즘이 아닐 수 있다.
하지만 나같은 경우에는 이렇게 찾는게 가장 빨랐다.
그리고 답답해하는 연구자들에게 이 방법을 공유한다.
3가지만 기억하면 된다.
벤치마크와 데이터셋 -> SOTA 모델 -> Citation (참 쉽죠?)
(보고 있나 과거의 나?)

1. 벤치마크와 데이터셋
가장 먼저 해야할 일은 데이터셋을 찾는 것이다.
모든 AI 모델은 데이터를 먹고 무럭무럭 자란다.
따라서 본질에 해당하는 데이터가 가장 먼저 찾아야 하는 지점이다.
각 AI 분야는 분명한 목적이 존재하고 이걸 Task 라고 부른다.
그리고 이 Task를 학습하기 위한 데이터셋이 존재한다.
그리고 이런 데이터셋 중에는 표준이 되는 벤치마크가 존재한다.
이제부터 구체적은 예를들어 설명하겠다.
팀장님이 내일까지 self-supervised learning (SSL)에 대하여 알아오라고 한다.
그럼 먼저 구글에 SSL 데이터셋, SSL 벤치마크 를 검색한다. (LLM을 시켜도 좋다.)
SSL의 데이터셋으로는 ImageNet, CIFAR-10, iNaturalist19 등이 있다고 나온다.
그리고 이 중에서 표준 벤치마크는 ImageNet을 한다는 것을 찾을 수 있다.
비전분야 self-supervised learning 벤치마크랑 데이터셋들 알려줘

2. SOTA 모델
벤치마크를 찾았다면 이 벤치마크의 SOTA를 찾으면 된다.
SOTA 모델은 해당 벤치마크의 1등 (or 준하는) 성적을 낸 모델이다.
과거에는 paperswithcode라는 사이트가 있어서 거기서 찾을 수 있었다.
그런데 허깅페이스가 이 부서를 사내에서 합병 하면서 사이트가 사라졌다.
(왜그랬어. 왜그랬냐고!!!!!!!!!!!)

그래서 이제는 예전처럼 사이트에서 손쉽게 찾는 방법이 없다.
하지만? 이제 딸깍 하면 찾을 수 있는 시대가 왔다. (with 채찍)
구글이나 LLM에게 해당 벤치마크의 SOTA 모델을 찾아달라고 하면 된다.
주의할 점은 당해 년도는 춘추전국시대이고 검증이 안된 경우가 많다.
따라서 직전 년도까지를 조회하고 당해년도는 스스로 찾는게 좋다.
ImageNet 특히 SSL 분야의 2024년 SOTA 모델 찾아줘.

여러개를 찾아도 좋지만, 사실 2~3개만 찾아도 충분하다.
어짜피 LLM 이놈은 그닥 믿을게 못된다. 2~3개만 찾도록 하자.
(검색 결과 텍스트나 논문 내의 텍스트에 영향이 심한데 그 텍스트가 뻥일 확률이 높음.)
3. Citation
SOTA 모델을 찾았으니 이 모델을 숙주삼아 찾는다.
이 모델을 중심으로 앞뒤 citation을 쭉쭉 보면 된다.
3.1. 직전 SOTA 모델
먼저 직전 SOTA들을 탐색해보자.
위에서 찾은 SOTA 모델은 자신이 최강임을 증명해야한다.
따라서 직전의 최고 성능 모델들을 모두 가져와서 평가했을 것이다.
즉, 내가 안찾아도 이 직전까지의 모델은 이 연구자가 대신 찾아놨다.
그리고 그 결과는 보통 메인이 되는 result table에서 한눈에 볼 수 있다.
따라서 위에서 찾은 SOTA 모델 논문에 들어가 테이블을 찾는다.
DINO v2의 메인 result table

와자뵤~~! 여기서 다 볼 수 있다.
MAE, DINO, SEER v2, MSN, EsViT, Mugs, iBOT 이렇게다.
이게 직전 시대의 SOTA 모델이고 동료들의 검증까지 끝난 모델들이다.
추가적으로 저 모델들로 들어가면 해당 논문 이전 시대의 SOTA들도 만날 수 있다.
이렇게 쭉쭉 찾아나가면 된다.
MAE의 메인 result table
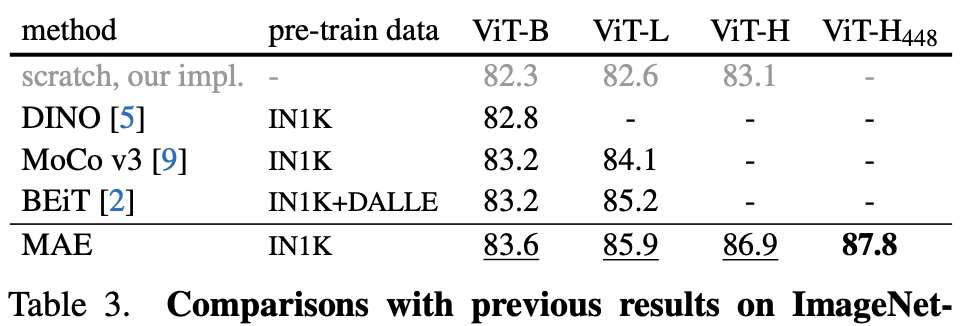
(MAE 논문에서 더 이전의 SOTA 모델 파밍 가능. BEiT, MoCo v3 등)
3.2. 이후의 SOTA 모델
이제 이후의 SOTA 모델들을 탐색해보자.
아까 찾은 DINO v2 이 모델은 2024 SOTA 모델이다.
(물론 LLM 피셜이라 의심은 필요함. 작년 기준이니 대체로 맞을거다.)
그럼 이후의 SOTA 모델은 어떻게 자신을 증명할까?
당연히 DINO v2 모델과 자신의 결과를 비교하는 작업을 한다.
(그래서 그걸 내가 어떻게 알 수 있는데...? 그건 미래잔하...)

이 작업은 구글 스칼라라는 곳에서 가능하다.
Google 학술 검색
거인의 어깨에 올라서서 더 넓은 세상을 바라보라 - 아이작 뉴턴 죄송합니다. 자바스크립트를 사용하도록 설정하지 않으면 일부 기능이 작동하지 않을 수 있습니다. 최적의 상태로 사용하려면
scholar.google.co.kr
구글 스칼라에 아까 찾은 SOTA 모델을 검색한다.
대충 검색해도 대충 나오는데 웬만하면 논문의 제목을 검색하자.
그러면 이 논문을 citation한 논문 목록을 전부 다 볼 수 있다.
아래 그림에서 보라색으로 0000회 인용 이라고 되어있는 부분을 클릭하자.

그리고 왼쪽에서 올해 년도를 클릭한다.

그럼 이렇게 동일한 분야의 최신 논문들이 나온다.
(후속 논문이 나온건 우연의 일치 이다. 일까? 푸하하)

이제 이 논문에 대하여 동일한 방법의 논문 탐색을 하면 된다.
(메인 result table 찾기, 이전 SOTA 모델 찾기)
하지만 이 방법에는 살짝 주의할 점이 있다.
이 논문과 완벽하게 같은 방향이 아니어도 citation을 한다는 것이다.
따라서 논문의 제목을 보고 1차 회피를 하고, 내용을 읽어 2차 회피를 해야한다.
논문을 읽고 우리가 찾고자 하는 SSL 분야가 아니면 걸러내야 한다는 것이다.

4. Next
이제 우리는 벤치마크, 데이터셋, SOTA 모델들 을 찾았다.
이제 뭘 하면 될까?

목적에 따라 다르겠지만 보통 이런 작업을 하는 이유는 다음과 같다.
연구 동향과 기술의 장단점을 파악하고 다음 논문을 준비한다.
연구 동향과 기술의 장단점을 파악하고 비즈니스에 적용한다.
따라서 SOTA들의 논문을 꼼꼼하게 읽으면 된다.
연구 동향은 주로 related works를 보면 나오는 편이다.
기술의 장단점은 method를 보면 나오는 편이다.
그리고 논문의 코드 구현을 찾아본 뒤 실행하보면 좋다.
(시간이 있다면 직접 구현하는 것이 베스트)
5. 치트키: 서베이 논문
지금까지 설명한 이런 작업은 사실 누가 해놨을 수도 있다.
그 분야가 핫하고 유망하다면 분명히 있다.
그게 바로 서베이 논문이다.
서베이 논문은 논문 제목에 survey나 review라는 키워드가 들어간다.
만약 이런 서베이 논문이 있다면 이걸 먼저 찾아보는 것도 하나의 방법이다.
하지만 이렇게 직접 찾는 과정에서 배울 수 있는 것이 정말 많다.
따라서 직접 실행하는 것을 더 추천한다.
그리고 어떤 분야는 이런 서베이 논문이 없을 가능성이 있다.
이럴때는 어쩔 수 없이 직접 실행해야한다.
6. 결론
이제 더 이상 "논문 뭐부터 읽죠?" 하며 눈치 보지 말자.
벤치마크 -> SOTA -> Citation
이 3단계 로드맵만 머릿속에 넣어두면 된다.
어떤 낯선 분야가 닥쳐도 이 방식대로 꼬리에 꼬리를 물고 들어가면,
금세 해당 분야의 족보가 한눈에 들어올 것이다.
많은 방황하는 연구자들에게 이 글이 도움이 됐으면 한다.
끝.
'이론' 카테고리의 다른 글
| RLHF 정리 (PPO, DPO, IPO, KTO, ORPO, GRPO), 핵심 아이디어, 차이점, 수식 분석, 데이터셋 예시 (0) | 2025.07.20 |
|---|---|
| [풀스택 딥러닝] 2번째, 딥러닝 실험 관리 방법, Weights & Biases, W&B, wandb, 텐서보드 (1) | 2025.06.22 |
| [풀스택 딥러닝] 1번째, 딥러닝 개발 인프라와 도구, 파이토치 라이트닝, 허깅페이스, ONNX, 분산 학습 DDP, ZeRO-3, 클라우드 비용, GPU 서버 구축 비용 (0) | 2025.06.16 |
| 딥러닝 공부 순서 정리 (for CV, Computer Vision) (1) | 2025.06.01 |
| FLOPs, #param, throughput 계산, 의미, 관계 (0) | 2024.03.19 |



