LLM의 가장 기본이 되는 메서드인 RLHF.
나는 비전 분야만 잘 알면 되는 줄 알았다.
그런데 슬슬 VLM에 대한 이야기가 나온다.
그리고 LLM을 모르면 뒤쳐지는 느낌이 든다.
아무튼 그래서 RLHF 기법에 대하여 조사해서 정리해봤다.
기본적인 딥러닝 지식이 있다는 가정하에 (없어도 무방, GPT와 함께라면)
최대한 쉽게 설명해보도록 하겠다.
1. LLM 최적화 기법

LLM은 사전학습 이후에 다양한 방법으로 후속 최적화를 진행한다.
대표적으로 `SFT`와 `RLHF` 2가지가 있다.
보통 학습 순서는 (사전학습 -> SFT -> RLHF) 순으로 진행된다.
최종적으로 얻은, RLHF까지 마친 모델을 policy model 혹은 align model 이라고 한다.
1.1. SFT
Supervised Fine-Tuning
사람이 작성한 고품질 데이터로 모델을 fine-tuning 한다.
instruction-following 데이터셋을 사용한다. (질문-응답, 대화, 지시사항 등)
특정 task에 대한 성능을 직접적으로 향상시킨다.
비전에서는 보통 pre-training과 fine-tuning으로 학습을 마무리한다.
이 pre-training과 fine-tuning의 특징은 모델 파라미터를 `직접` 업데이트 하는 것이다.
아래 나오는 RLHF 방법들은 보상 모델을 먼저 학습하고 `간접`적으로 업데이트 한다.
1.2. RLHF
Reinforcement Learning from Human Feedback
사람의 선호도를 반영한 피드백으로 모델을 최적화한다.
모델을 보다 자연스럽고 일관성 있게 조정한다.
`보상 모델`을 먼저 학습하고 이를 사용하여 `정책 모델`을 학습한다.
`보상 모델`은 사전학습 모델의 아웃풋 레이어를 변경하여 점수 예측을 수행한다.
(다른 레이어는 기존 LLM처럼 인코더-인코더 혹은 디코더-디코더 이다.)
(물론 학습은 모든 레이어가 다 진행한다. linear probing 방식은 아니다.)
`정책 모델`은 사전학습 모델을 RLHF로 학습한 모델을 뜻하며, 응답을 생성한다.
(RLHF의 자세한 과정은 바로 아래에 있으니 일단 학습 방법으로 생각하자.)
이 RLHF 학습 과정에서 `보상 모델`이 예측한 점수를 사용한다.
실제 서비스에서는 `정책 모델`만 사용하여 응답을 생성한다.
`보상 모델`은 학습에서만 사용된다.
2. LLM RLHF 워크플로우

총 3단계로 진행된다.
Step 0: 준비
사전학습과 SFT를 통해 초기 모델을 준비한다.
Step 1: Human 데이터 수집
초기 모델에 질문을 하여 2~5개의 응답을 생성한다.
생성된 응답에 대해 사람이 선호도를 평가한다.
이제 Human 데이터를 수집했고 이걸로 Human 데이터셋을 만들었다.
Human 데이터셋의 내용은 응답에 0점에서 5점 사이의 채점을 했다고 생각하자.
Step 2: 보상 모델 학습
사람의 피드백은 비용이 들기 때문에 계속 사용하기 힘들다.
따라서 사람의 피드백을 예측하는 보상 모델을 학습한다.
이 보상 모델은 초기 모델의 복제본인데 아웃풋 레이어만 교체한 것이다.
보상 모델은 질문과 응답 쌍을 입력으로 받아 선호도 점수를 예측한다.
쉽게 설명하면 Human 데이터셋을 활용해서 모델을 학습한다.
이 학습된 모델은 Human이라면 0점에서 5점 중에 몇점으로 채점할지 예측한다.
어라? 그럼 이제 Human이 없어도 무한하게 Human인척 채점해줄 수 있다.
이 보상 모델은 Human의 비용을 없애기 위해 나온 것이다.
모델이 학습하기 위해서는 수천억번의 질문과 답변을 해야하기 때문이다.
매번 이 답변을 채점해야한다면 비용이 엄청날건데 이것도 기계로 대체한다.
Step 3: 정책 모델 학습 (RL fine-tuning)
새로운 질문에 대해 정책 모델이 응답을 생성한다.
이 정책 모델은 초기 모델와 동일한 복제본이다.
보상 모델이 정책 모델의 응답에 대한 선호도 점수를 예측해준다.
RL 알고리즘을 사용하여 높은 선호도의 응답을 생성하도록 학습한다.
RL 알고리즘이란 보상이 많아지는 방향으로 학습하는 것이다.
쉽게 설명하면 원본 모델에 대한 진짜 학습을 시작하는 단계다.
다만 앞서 했던 과정에서 채점 기계를 만들었으니 그걸 활용한다.
채점 기계가 자동으로 채점해주면 그 점수가 높아지게끔 수학적으로 학습한다.
이때 사용하는 알고리즘이 RL 알고리즘이다.
3. RLHF 알고리즘의 종류

이제 PPO, DPO 등 각종 RLHF 알고리즘의 종류를 알아보자.
3.1. PPO
Proximal Policy Optimization, 2017, OpenAI
핵심 아이디어: 강화학습을 통한 RLHF
인간 피드백으로 `보상 모델`을 학습한 뒤 `정책 모델`을 강화학습한다.
정책 업데이트 시 클리핑을 통해 안정성을 확보한다.
SFT와 비교: 지도학습에서 강화학습으로 전환, 정책 업데이트 안정성 확보
문제점: 불안정한 학습, 높은 계산 비용, 복잡한 하이퍼파라미터 튜닝
수식 분석:
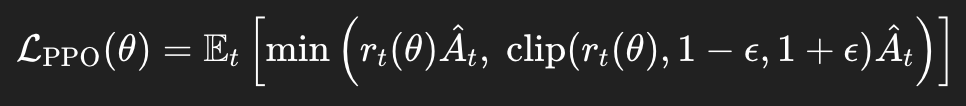
클리핑된 목적 함수 L_PPO를 최대화한다.
데이터셋 예시:
{
"prompt": "파이썬으로 피보나치 수열을 구현해줘",
"response_a": "def fib(n): return fib(n-1) + fib(n-2)",
"response_b": "def fib(n):\n if n <= 1: return n\n return fib(n-1) + fib(n-2)",
"preference": "B" // B 선호
}prompt는 초기 모델의 인풋, response_a과 response_b는 초기 모델의 아웃풋이다.
preference는 보상모델이 학습해야할 사람의 피드백이다.
3.2. DPO
Direct Preference Optimization, 2023, 스탠포드
핵심 아이디어: 강화학습 없이 직접 선호도 최적화
보상 모델 없이 선호도 데이터를 직접 손실함수로 변환한다.
수학적으로 PPO와 동일하지만 훨씬 간단하게 구현할 수 있다.
PPO와 비교: 강화학습에서 단순한 지도학습으로 전환, 안정적인 학습
문제점: 선호도 데이터의 양이 많아야 효과적
수식 분석:

주어진 답변쌍(y_+, y_-) 데이터에 대해 목적 함수 L_DPO를 최소화한다.
데이터셋 예시:
{
"prompt": "건강한 아침식사 추천해줘",
"chosen": "오트밀에 베리류와 견과류를 넣은 식단을 추천합니다. 섬유질과 단백질이 풍부해 포만감이 오래 지속됩니다.",
"rejected": "초콜릿 케이크 어때요? 달달하고 맛있어요."
}prompt는 초기 모델의 인풋, chosen과 rejected는 초기 모델의 아웃풋이다.
여기서 chosen과 rejected를 답변쌍(y_+, y_-) 이라고 한다.
PPO와 달리 보상 모델이 없다.
3.3. IPO
Identity Preference Optimization, 2024, 구글
핵심 아이디어: DPO의 길이 편향 문제 해결
DPO가 긴 응답을 선호하는 경향을 수정한다.
정규화 항 추가로 더 균형잡힌 최적화를 진행한다.
DPO와 비교: 길이 편향 문제 해결, 더 안정적인 학습
문제점: 여전히 선호도 데이터의 양이 많아야 효과적
수식 분석:

기존 DPO 손실에 정규화 항을 추가한다.
데이터셋 예시:
{
"prompt": "기후변화 해결책은?",
"chosen": "재생에너지 전환, 탄소세 도입, 개인 차원의 절약 실천이 필요합니다.",
"rejected": "기후변화 해결을 위해서는 다음과 같은 다양한 방법들이 있습니다. 첫째, 재생에너지로의 전환입니다. 태양광, 풍력, 수력 발전 등을 통해... (매우 긴 답변)",
"chosen_length": 35,
"rejected_length": 200
}DPO와 동일하지만 길이 정보만 추가된 것이다.
LLM 모델이 길이가 더 긴 답변을 더 중요하게 여기는 편향을 제거한다.
3.4. KTO
Kahneman-Tversky Optimization, 2024, 스탠포드
핵심 아이디어: 쌍별 비교 대신 개별 피드백 활용
"좋아요/싫어요"의 이진 피드백만으로 학습한다.
인간의 손실 회피 성향을 모델링한 것이다. (전망 이론 기반)
IPO와 비교: 쌍별 선호 데이터 불필요, 데이터 효율성 향상
문제점: 이진 피드백의 낮은 정보량, 불안정성 등 (연구중)
수식 분석:
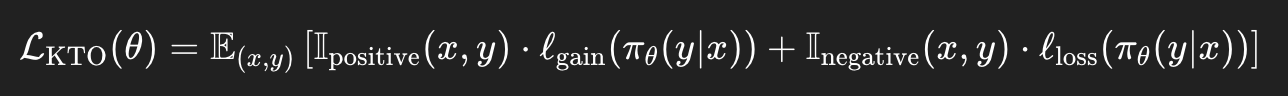
기댓값 형태의 손실 함수로 표현한다.
데이터셋 예시:
{
"prompt": "스트레스 해소 방법 알려줘",
"response": "심호흡, 명상, 운동, 충분한 수면이 도움됩니다.",
"label": "good" // good/bad 이진 분류
},
{
"prompt": "스트레스 해소 방법 알려줘",
"response": "술 마시고 담배 피우면 됩니다.",
"label": "bad"
}쌍으로 준비하는게 아니라 그냥 하나하나 이진 분류를 한다.
3.5. ORPO
Odds Ratio Preference Optimization, 2024, 카이스트
핵심 아이디어: SFT와 RLHF를 동시에 수행
별도의 SFT 단계 없이 한 번에 학습한다.
승산비(odds ratio)를 통한 선호도 모델링을 진행한다.
PPO와 비교: 2단계 학습 -> 1단계 학습, 학습 효율성 향상
(IPO와 비교 X, PPO의 근본을 뜯어 고친다.)
문제점: SFT 생략으로 초기 불안정, 복잡한 손실 함수 등 (연구중)
수식 분석:
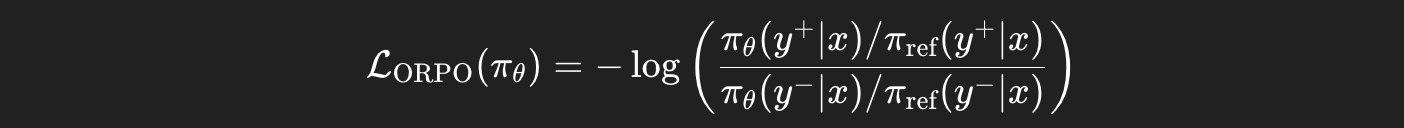
선호 응답과 SFT 응답 간의 odds ratio (로그 안에 있는 덩어리)를 활용하여 목적 함수를 최소화한다.
데이터셋 예시:
{
"prompt": "이메일 작성법 알려줘",
"chosen": "제목을 명확히 하고, 인사말로 시작하여 본문을 간결하게 작성한 후 정중한 마무리를 합니다.",
"rejected": "그냥 대충 쓰면 돼요. 제목도 '안녕'이라고 하고.",
"sft_target": "chosen" // SFT 타겟도 함께 지정
}
ORPO의 핵심은 odds ratio로 SFT를 동시에 진행하는 것이다.
기존에는 2번의 페이즈로 나눠서 학습을 진행한다.
SFT 페이즈에서는 sft_target을 사용하고,
RLHF 페이즈에서는 chosen과 rejected를 사용한다.
하지만 ORPO는 한번의 페이즈에서 두 학습을 동시에 진행한다.
(엥? 어떻게? 이래도 돼?) 라는 생각이 들 수 있지만,
수학으로 조지면 가능하다는 것을 보여준 논문이다.
3.6. GRPO
Group Relative Policy Optimization, 2024, 딥시크
핵심 아이디어: 그룹화된 상대적 순위 기반 최적화
여러 응답을 그룹으로 묶어 상대적 순위와 함께 학습한다.
리스트와이즈 학습 방식을 도입한다.
IPO와 비교: 쌍별 데이터 -> 그룹별 데이터, 더 풍부한 선호 정보 활용
문제점: 그룹 데이터 수집 난이도, 계산 비용 등 (연구중)
수식 분석:

리스트와이즈(Listwise) 손실을 활용한다.
데이터셋 예시:
{
"prompt": "효과적인 프레젠테이션 팁은?",
"responses": [
"청중을 파악하고 명확한 구조로 발표하세요.",
"슬라이드를 많이 만들고 빠르게 넘기세요.",
"시선 접촉을 유지하고 자신감 있게 발표하세요.",
"대본을 그대로 읽으면 됩니다."
],
"ranking": [1, 4, 2, 3] // 1이 가장 좋음, 4가 가장 나쁨
}기존에 2개의 답변을 사용했지만, GRPO는 2개 이상의 `답변 그룹`을 사용한다.
4. 결론
비전 모델만 알면 충분하다고 생각했던 시절이 있었다.
그러나 최근 VLM(Vision-Language Model)의 등장은
이제 LLM에 대한 이해 없이는 비전 모델만으로는 한계가 있음을 시사한다.
그리고 RLHF는 LLM의 핵심적인 기술이다.
RLHF는 단순한 모델 파라미터 조정이 아니라,
인간의 선호를 반영하여 모델을 정렬(alignment) 시키는 과정이다.
GPT나 Claude 같은 고성능 LLM을 우리가 원하는 방식으로 만드는 기술의 핵심이다.
또한, PPO, DPO, IPO, KTO 등으로 확장되는 다양한 최적화 기법들은
정렬된 AI를 만들기 위한 연구의 흐름이 단순히 성능 향상 그 이상임을 보여준다.
이는 AI가 인간과 상호작용하는 시대에 가장 중요한 영역 중 하나로 부상하고 있다.
그리고 그 중심에는 RLHF가 있다.
끝.
'이론' 카테고리의 다른 글
| 낯선 AI 분야 논문 찾는 방법, (???: 이 분야 좀 내일까지 알아봐) (2) | 2025.12.19 |
|---|---|
| [풀스택 딥러닝] 2번째, 딥러닝 실험 관리 방법, Weights & Biases, W&B, wandb, 텐서보드 (1) | 2025.06.22 |
| [풀스택 딥러닝] 1번째, 딥러닝 개발 인프라와 도구, 파이토치 라이트닝, 허깅페이스, ONNX, 분산 학습 DDP, ZeRO-3, 클라우드 비용, GPU 서버 구축 비용 (0) | 2025.06.16 |
| 딥러닝 공부 순서 정리 (for CV, Computer Vision) (1) | 2025.06.01 |
| FLOPs, #param, throughput 계산, 의미, 관계 (0) | 2024.03.19 |



