반응형
Transformer는 학습할 때 오래걸린다.
그리고 너무 복잡해서 열받을 때가 많다.
학습 과정을 보는 방법으로 하나를 제안하려고 한다.
보통 학습이 안되는 이유 중에 가장 빈번한 것은 gradient 때문이다.
gradient vanishing, gradient exploding 두개가 제일 문제다.
이걸 확인하는 방법은 생각보다 간단하다.
forward 도중에 텐서의 크기(range)를 뽑아보면 된다.
print(torch.max(x) - torch.min(x))이게 끝이다.
예를들어 설명해주겠다.
첫번째 모델은 hugging face의 라이브러리로 만든 ViT다.
즉 군더더기 없는 코드이고, 학습도 잘된다.



learning rate가 0.001인 조건에서 텐서의 크기는 4정도 된다.
즉 backward가 진행될 때 4정도의 gradient가 propagation된다.
두번째 모델은 똑같은 ViT에 softmax를 추가한 것이다.
즉, softmax 특성상 gradient가 exponential하게 커질 것이다.


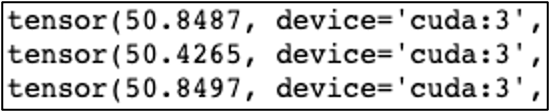
learning rate가 0.001인 조건에서 텐서의 크기는 40정도 된다.
4에서 40으로 gradient exploding이 일어났다. optimizer는 정신 못차리고 최소값을 못찾을 것이다.
이제 그럼 해결책으로 learning rate를 낮춰주자.


텐서의 크기가 4정도로 돌아왔고, 학습이 잘 이루어진다.
끝.
반응형
'Error 잡기' 카테고리의 다른 글
| ImageNet 다운로드, ImageNet 원본 이미지 보는 방법, 이미지넷 다운로드, 이미지넷 원본 이미지 보는 방법 (0) | 2023.05.09 |
|---|---|
| 이미지넷 클래스 파이썬 코드 (0) | 2023.05.09 |
| 리눅스 주피터 노트북 가상환경 추가, 커널 추가 (0) | 2023.04.13 |
| 파이참 설치, 파이참 환경변수 설정, 파이참 개발환경 설정, pycharm 설치, Free Educational Licenses (0) | 2023.03.21 |
| 아나콘다 설치, 환경변수 설정, 개발환경 설정, anaconda 설치 (0) | 2023.03.21 |



